TypeScript
简介
TypeScript 是一种基于 JavaScript 构建的强类型编程语言。TypeScript 限制了 JavaScript 的灵活性,但也增强了项目代码的健壮性。
理解原始类型与对象类型
首先,我们来看 JavaScript的内置原始类型。除了最常见的 number / string / boolean / null / undefined, ECMAScript 2015(ES6)、2020 (ES11) 又分别引入了 2 个新的原始类型:symbol 与 bigint 。在 TypeScript 中它们都有对应的类型注解:
const name: string = 'zhangsan';
const age: number = 24;
const male: boolean = false;
const undef: undefined = undefined;
const nul: null = null;
const obj: object = { name, age, male };
const bigintVar1: bigint = 9007199254740991n;
const bigintVar2: bigint = BigInt(9007199254740991);
const symbolVar: symbol = Symbol('unique');其中,除了 null 与 undefined 以外,余下的类型基本上可以完全对应到 JavaScript 中的数据类型概念,因此这里我们只对 null 与 undefined 展开介绍。
null 与 undefined
在 JavaScript 中,null 与 undefined 分别表示“这里有值,但是个空值”和“这里没有值”。而在 TypeScript 中,null 与 undefined 类型都是有具体意义的类型。也就是说,它们作为类型时,表示的是一个有意义的具体类型值。这两者在没有开启 strictNullChecks 检查的情况下,会被视作其他类型的子类型,比如 string 类型会被认为包含了 null 与 undefined 类型:
const tmp1: null = null;
const tmp2: undefined = undefined;
const tmp3: string = null; // 仅在关闭 strictNullChecks 时成立,下同
const tmp4: string = undefined;除了上面介绍的原始类型以及 null、undefined 类型以外,在 TypeScript 中还存在着一个特殊的类型:void,它和 JavaScript 中的 void 同样不是一回事,我们接着往下看。
void
<a href="javascript:void(0)">清除缓存</a>这里的 void(0) 等价于 void 0,即 void expression 的语法。void 操作符会执行后面跟着的表达式并返回一个 undefined,如你可以使用它来执行一个立即执行函数(IIFE):
void function iife() {
console.log("Invoked!");
}();能这么做是因为,void 操作符强制将后面的函数声明转化为了表达式,因此整体其实相当于:void((function iife(){})())。
事实上,TypeScript 的原始类型标注中也有 void,但与 JavaScript 中不同的是,这里的 void 用于描述一个内部没有 return 语句,或者没有显式 return 一个值的函数的返回值,如:
function func1() {}
function func2() {
return;
}
function func3() {
return undefined;
}在这里,func1 与 func2 的返回值类型都会被隐式推导为 void,只有显式返回了 undefined 值的 func3 其返回值类型才被推导为了 undefined。但在实际的代码执行中,func1 与 func2 的返回值均是 undefined。
TIP
虽然 func3 的返回值类型会被推导为 undefined,但是你仍然可以使用 void 类型进行标注,因为在类型层面 func1、func2、func3 都表示“没有返回一个有意义的值”。
这里可能有点绕,你可以认为 void 表示一个空类型,而 null 与 undefined 都是一个具有意义的实际类型(注意与它们在 JavaScript 中的意义区分)。而 undefined 能够被赋值给 void 类型的变量,就像在 JavaScript 中一个没有返回值的函数会默认返回一个 undefined 。null 类型也可以,但需要在关闭 strictNullChecks 配置的情况下才能成立。
const voidVar1: void = undefined;
const voidVar2: void = null; // 需要关闭 strictNullChecks数组的类型标注
数组同样是我们最常用的类型之一,在 TypeScript 中有两种方式来声明一个数组类型:
const arr1: string[] = [];
const arr2: Array<string> = [];这两种方式是完全等价的,但其实更多是以前者为主,如果你将鼠标悬浮在 arr2 上,会发现它显示的类型签名是 string[]。数组是我们在日常开发大量使用的数据结构,但在某些情况下,使用 元组(Tuple) 来代替数组要更加妥当,比如一个数组中只存放固定长度的变量,但我们进行了超出长度地访问:
const arr3: string[] = ['lin', 'bu', 'du'];
console.log(arr3[599]);这种情况肯定是不符合预期的,因为我们能确定这个数组中只有三个成员,并希望在越界访问时给出类型报错。这时我们可以使用元组类型进行类型标注:
const arr4: [string, string, string] = ['lin', 'bu', 'du'];
console.log(arr4[599]);此时将会产生一个类型错误:长度为“3”的元组类型“[string, string, string]”在索引“599“处没有元素。除了同类型的元素以外,元组内部也可以声明多个与其位置强绑定的,不同类型的元素:
const arr5: [string, number, boolean] = ['zhangsan', 599, true];在这种情况下,对数组合法边界内的索引访问(即 0、1、2)将精确地获得对应位置上的类型。同时元组也支持了在某一个位置上的可选成员:
const arr6: [string, number?, boolean?] = ['zhangsan'];
// 下面这么写也可以
// const arr6: [string, number?, boolean?] = ['zhangsan', , ,];对于标记为可选的成员,在 --strictNullCheckes 配置下会被视为一个 string | undefined 的类型。此时元组的长度属性也会发生变化,比如上面的元组 arr6 ,其长度的类型为 1 | 2 | 3:
type TupleLength = typeof arr6.length; // 1 | 2 | 3也就是说,这个元组的长度可能为 1、2、3。
TIP
关于类型别名(type)、类型查询(typeof)以及联合类型,我们会在后面讲到,这里你只需要简单了解即可。
你可能会觉得,元组的可读性实际上并不好。比如对于 [string, number, boolean] 来说,你并不能直接知道这三个元素都代表什么,还不如使用对象的形式。而在 TypeScript 4.0 中,有了具名元组(Labeled Tuple Elements)的支持,使得我们可以为元组中的元素打上类似属性的标记:
const arr7: [name: string, age: number, male: boolean] = ['zhangsan', 599, true];有没有很酷?考虑到某些拼装对象太麻烦,我们完全可以使用具名元组来做简单替换。具名元组可选元素的修饰符将成为以下形式:
const arr7: [name: string, age: number, male?: boolean] = ['zhangsan', 599, true];实际上除了显式地越界访问,还可能存在隐式地越界访问,如通过解构赋值的形式:
const arr1: string[] = [];
const [ele1, ele2, ...rest] = arr1;对于数组,此时仍然无法检查出是否存在隐式访问,因为类型层面并不知道它到底有多少个元素。但对于元组,隐式的越界访问也能够被揪出来给一个警告:
const arr5: [string, number, boolean] = ['zhangsan', 599, true];
// 长度为 "3" 的元组类型 "[string, number, boolean]" 在索引 "3" 处没有元素。
const [name, age, male, other] = arr5;JavaScript 的开发者对元组 Tuple 的概念可能比较陌生,毕竟在 JavaScript 中我们很少声明定长的数组。但使用元组确实能帮助我们进一步提升数组结构的严谨性,包括基于位置的类型标注、避免出现越界访问等等。除了通过数组类型提升数组结构的严谨性,TypeScript 中的对象类型也能帮助我们提升对象结构的严谨性。接下来我们就一起来看看。
对象的类型标注
作为 JavaScript 中使用最频繁的数据结构,对象的类型标注是我们本节要重点关注的部分。接下来我们会学习如何在 TypeScript 中声明对象、修饰对象属性,以及了解可能存在的使用误区。这些内容能够帮助你建立起对 TypeScript 中立体类型(我们可以理解为前面的原始类型是“平面类型”)的了解,正式入门 TypeScript 。
类似于数组类型,在 TypeScript 中我们也需要特殊的类型标注来描述对象类型,即 interface ,你可以理解为它代表了这个对象对外提供的接口结构。
首先我们使用 interface 声明一个结构,然后使用这个结构来作为一个对象的类型标注即可:
interface IDescription {
name: string;
age: number;
male: boolean;
}
const obj1: IDescription = {
name: 'zhangsan',
age: 599,
male: true,
};这里的“描述”指:
- 每一个属性的值必须一一对应到接口的属性类型
- 不能有多的属性,也不能有少的属性,包括直接在对象内部声明,或是
obj1.other = 'xxx'这样属性访问赋值的形式
除了声明属性以及属性的类型以外,我们还可以对属性进行修饰,常见的修饰包括可选(Optional) 与 只读(Readonly) 这两种。
修饰接口属性
类似于上面的元组可选,在接口结构中同样通过 ? 来标记一个属性为可选:
interface IDescription {
name: string;
age: number;
male?: boolean;
func?: Function;
}
const obj2: IDescription = {
name: 'zhangsan',
age: 599,
male: true,
// 无需实现 func 也是合法的
};在这种情况下,即使你在 obj2 中定义了 male 属性,但当你访问 obj2.male 时,它的类型仍然会是 boolean | undefined,因为毕竟这是我们自己定义的类型嘛。
假设新增一个可选的函数类型属性,然后进行调用:obj2.func() ,此时将会产生一个类型报错:不能调用可能是未定义的方法。但可选属性标记不会影响你对这个属性进行赋值,如:
obj2.male = false;
obj2.func = () => {};即使你对可选属性进行了赋值,TypeScript 仍然会使用接口的描述为准进行类型检查,你可以使用类型断言、非空断言或可选链解决(别急,我们在后面会讲到)。
除了标记一个属性为可选以外,你还可以标记这个属性为只读:readonly。很多同学对这一关键字比较陌生,因为以往 JavaScript 中并没有这一类概念,它的作用是防止对象的属性被再次赋值。
interface IDescription {
readonly name: string;
age: number;
}
const obj3: IDescription = {
name: 'zhangsan',
age: 599,
};
// 无法分配到 "name" ,因为它是只读属性
obj3.name = "张三";其实在数组与元组层面也有着只读的修饰,但与对象类型有着两处不同。
- 你只能将整个数组/元组标记为只读,而不能像对象那样标记某个属性为只读。
- 一旦被标记为只读,那这个只读数组/元组的类型上,将不再具有
push、pop等方法(即会修改原数组的方法),因此报错信息也将是类型xxx上不存在属性“push”这种。这一实现的本质是只读数组与只读元组的类型实际上变成了ReadonlyArray,而不再是Array。
type 与 interface
我也知道,很多同学更喜欢用 type(Type Alias,类型别名)来代替接口结构描述对象,而我更推荐的方式是,interface 用来描述对象、类的结构,而类型别名用来将一个函数签名、一组联合类型、一个工具类型等等抽离成一个完整独立的类型。但大部分场景下接口结构都可以被类型别名所取代,因此,只要你觉得统一使用类型别名让你觉得更整齐,也没什么问题。
object、Object 以及 {}
object、Object 以及{}(一个空对象)这三者的使用可能也会让部分同学感到困惑,所以我也专门解释下。
首先是 Object 的使用。被 JavaScript 原型链折磨过的同学应该记得,原型链的顶端是 Object 以及 Function,这也就意味着所有的原始类型与对象类型最终都指向 Object,在 TypeScript 中就表现为 Object 包含了所有的类型:
// 对于 undefined、null、void 0 ,需要关闭 strictNullChecks
const tmp1: Object = undefined;
const tmp2: Object = null;
const tmp3: Object = void 0;
const tmp4: Object = 'linbudu';
const tmp5: Object = 599;
const tmp6: Object = { name: 'linbudu' };
const tmp7: Object = () => {};
const tmp8: Object = [];和 Object 类似的还有 Boolean、Number、String、Symbol,这几个装箱类型(Boxed Types) 同样包含了一些超出预期的类型。以 String 为例,它同样包括 undefined、null、void,以及代表的 拆箱类型(Unboxed Types) string,但并不包括其他装箱类型对应的拆箱类型,如 boolean 与 基本对象类型,我们看以下的代码:
const tmp9: String = undefined;
const tmp10: String = null;
const tmp11: String = void 0;
const tmp12: String = 'linbudu';
// 以下不成立,因为不是字符串类型的拆箱类型
const tmp13: String = 599; // X
const tmp14: String = { name: 'linbudu' }; // X
const tmp15: String = () => {}; // X
const tmp16: String = []; // X在任何情况下,你都不应该使用这些装箱类型。
object 的引入就是为了解决对 Object 类型的错误使用,它代表所有非原始类型的类型,即数组、对象与函数类型这些:
const tmp17: object = undefined;
const tmp18: object = null;
const tmp19: object = void 0;
const tmp20: object = 'linbudu'; // X 不成立,值为原始类型
const tmp21: object = 599; // X 不成立,值为原始类型
const tmp22: object = { name: 'linbudu' };
const tmp23: object = () => {};
const tmp24: object = [];最后是{},一个奇奇怪怪的空对象,如果你了解过字面量类型,可以认为{}就是一个对象字面量类型(对应到字符串字面量类型这样)。否则,你可以认为使用{}作为类型签名就是一个合法的,但内部无属性定义的空对象,这类似于 Object(想想 new Object()),它意味着任何非 null / undefined 的值:
const tmp25: {} = undefined; // 仅在关闭 strictNullChecks 时成立,下同
const tmp26: {} = null;
const tmp27: {} = void 0; // void 0 等价于 undefined
const tmp28: {} = 'linbudu';
const tmp29: {} = 599;
const tmp30: {} = { name: 'linbudu' };
const tmp31: {} = () => {};
const tmp32: {} = [];虽然能够将其作为变量的类型,但你实际上无法对这个变量进行任何赋值操作:
const tmp30: {} = { name: 'linbudu' };
tmp30.age = 18; // X 类型“{}”上不存在属性“age”。这是因为它就是纯洁的像一张白纸一样的空对象,上面没有任何的属性(除了 toString 这种与生俱来的)。在类型层级一节我们还会再次见到它,不过那个时候它已经被称为“万物的起源”了。
最后,为了更好地区分 Object、object 以及{}这三个具有迷惑性的类型,我们再做下总结:
- 在任何时候都不要,不要,不要使用 Object 以及类似的装箱类型。
- 当你不确定某个变量的具体类型,但能确定它不是原始类型,可以使用
object。但我更推荐进一步区分,也就是使用Record<string, unknown>或Record<string, any>表示对象,unknown[]或any[]表示数组,(...args: any[]) => any表示函数这样。 - 我们同样要避免使用
{}。{}意味着任何非null / undefined的值,从这个层面上看,使用它和使用any一样恶劣。
unique symbol
Symbol 在 JavaScript 中代表着一个唯一的值类型,它类似于字符串类型,可以作为对象的属性名,并用于避免错误修改 对象 / Class 内部属性的情况。而在 TypeScript 中,symbol 类型并不具有这一特性,一百个具有 symbol 类型的对象,它们的 symbol 类型指的都是 TypeScript 中的同一个类型。为了实现“独一无二”这个特性,TypeScript 中支持了 unique symbol 这一类型声明,它是 symbol 类型的子类型,每一个 unique symbol 类型都是独一无二的。
const uniqueSymbolFoo: unique symbol = Symbol("linbudu")
// 类型不兼容
const uniqueSymbolBar: unique symbol = uniqueSymbolFoo在 JavaScript 中,我们可以用 Symbol.for 方法来复用已创建的 Symbol,如 Symbol.for("zhangsan") 会首先查找全局是否已经有使用 zhangsan 作为 key 的 Symbol 注册,如果有,则返回这个 Symbol,否则才会创建新的 Symbol 。
在 TypeScript 中,如果要引用已创建的 unique symbol 类型,则需要使用类型查询操作符 typeof :
declare const uniqueSymbolFoo: unique symbol;
const uniqueSymbolBaz: typeof uniqueSymbolFoo = uniqueSymbolFooTIP
以上代码实际执行时会报错,这是因为 uniqueSymbolFoo 是一个仅存在于类型空间的值,这里只是为了进行示例~
这里的 declare、typeof 等使用,都会在后面有详细地讲解。同时 unique symbol 在日常开发的使用非常少见,这里做了解就好~
掌握字面量类型与枚举
了解了原始类型与对象类型以后,我们已经能完成简单场景的类型标注了。但这还远远不够,我们还可以让这些类型标注更精确一些。比如,有一个接口结构,它描述了响应的消息结构:
interface IRes {
code: number;
status: string;
data: any;
}在大多数情况下,这里的 code 与 status 实际值会来自于一组确定值的集合,比如 code 可能是 10000 / 10001 / 50000,status 可能是 "success" / "failure"。而上面的类型只给出了一个宽泛的 number(string),此时我们既不能在访问 code 时获得精确的提示,也失去了 TypeScript 类型即文档的功能。
这个时候要怎么做?
字面量类型与联合类型
我们可以使用联合类型加上字面量类型,把上面的例子改写成这样:
interface Res {
code: 10000 | 10001 | 50000;
status: "success" | "failure";
data: any;
}这个时候,我们就能在访问时获得精确地类型推导了。
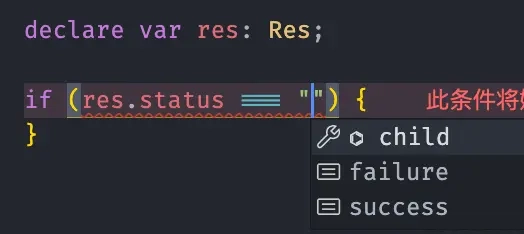
对于 declare var res: Res,你可以认为它其实就是快速生成一个符合指定类型,但没有实际值的变量,同时它也不存在于运行时中。上面引入了一些新的概念,我们来一个一个了解。
字面量类型
最开始你可能觉得很神奇,success 不是一个值吗?为什么它也可以作为类型?在 TypeScript 中,这叫做字面量类型(Literal Types),它代表着比原始类型更精确的类型,同时也是原始类型的子类型(关于类型层级,我们会在后面详细了解)。
字面量类型主要包括字符串字面量类型、数字字面量类型、布尔字面量类型和对象字面量类型,它们可以直接作为类型标注:
const str: "linbudu" = "linbudu";
const num: 599 = 599;
const bool: true = true;为什么说字面量类型比原始类型更精确?我们可以看这么个例子:
// 报错!不能将类型“"linbudu599"”分配给类型“"linbudu"”。
const str1: "linbudu" = "linbudu599";
const str2: string = "linbudu";
const str3: string = "linbudu599";上面的代码,原始类型的值可以包括任意的同类型值,而字面量类型要求的是值级别的字面量一致。
单独使用字面量类型比较少见,因为单个字面量类型并没有什么实际意义。它通常和联合类型(即这里的 |)一起使用,表达一组字面量类型:
interface Tmp {
bool: true | false;
num: 1 | 2 | 3;
str: "lin" | "bu" | "du"
}联合类型
而联合类型你可以理解为,它代表了一组类型的可用集合,只要最终赋值的类型属于联合类型的成员之一,就可以认为符合这个联合类型。联合类型对其成员并没有任何限制,除了上面这样对同一类型字面量的联合,我们还可以将各种类型混合到一起:
interface Tmp {
mixed: true | string | 599 | {} | (() => {}) | (1 | 2)
}这里有几点需要注意的:
- 对于联合类型中的函数类型,需要使用括号
()包裹起来 - 函数类型并不存在字面量类型,因此这里的
(() => {})就是一个合法的函数类型 - 你可以在联合类型中进一步嵌套联合类型,但这些嵌套的联合类型最终都会被展平到第一级中
联合类型的常用场景之一是通过多个对象类型的联合,来实现手动的互斥属性,即这一属性如果有字段1,那就没有字段2:
interface Tmp {
user:
| {
vip: true;
expires: string;
}
| {
vip: false;
promotion: string;
};
}
declare var tmp: Tmp;
if (tmp.user.vip) {
console.log(tmp.user.expires);
}在这个例子中,user 属性会满足普通用户与 VIP 用户两种类型,这里 vip 属性的类型基于布尔字面量类型声明。我们在实际使用时可以通过判断此属性为 true ,确保接下来的类型推导都会将其类型收窄到 VIP 用户的类型(即联合类型的第一个分支)。这一能力的使用涉及类型守卫与类型控制流分析,我们会在后面的章节详细来说。
我们也可以通过类型别名来复用一组字面量联合类型:
type Code = 10000 | 10001 | 50000;
type Status = "success" | "failure";除了原始类型的字面量类型以外,对象类型也有着对应的字面量类型。
对象字面量类型
类似的,对象字面量类型就是一个对象类型的值。当然,这也就意味着这个对象的值全都为字面量值:
interface Tmp {
obj: {
name: "linbudu",
age: 18
}
}
const tmp: Tmp = {
obj: {
name: "linbudu",
age: 18
}
}如果要实现一个对象字面量类型,意味着完全的实现这个类型每一个属性的每一个值。对象字面量类型在实际开发中的使用较少,我们只需要了解。
总的来说,在需要更精确类型的情况下,我们可以使用字面量类型加上联合类型的方式,将类型从 string 这种宽泛的原始类型直接收窄到 "resolved" | "pending" | "rejected" 这种精确的字面量类型集合。
TIP
需要注意的是,无论是原始类型还是对象类型的字面量类型,它们的本质都是类型而不是值。它们在编译时同样会被擦除,同时也是被存储在内存中的类型空间而非值空间。
如果说字面量类型是对原始类型的进一步扩展(对象字面量类型的使用较少),那么枚举在某些方面则可以理解为是对对象类型的扩展。
枚举
枚举并不是 JavaScript 中原生的概念,在其他语言中它都是老朋友了(Java、C#、Swift 等)。目前也已经存在给 JavaScript(ECMAScript)引入枚举支持的 proposal-enum 提案,但还未被提交给 TC39 ,仍处于 Stage 0 阶段。
如果要和 JavaScript 中现有的概念对比,我想最贴切的可能就是你曾经写过的 constants 文件了:
export default {
Home_Page_Url: "url1",
Setting_Page_Url: "url2",
Share_Page_Url: "url3",
}
// 或是这样:
export const PageUrl = {
Home_Page_Url: "url1",
Setting_Page_Url: "url2",
Share_Page_Url: "url3",
}如果把这段代码替换为枚举,会是如下的形式:
enum PageUrl {
Home_Page_Url = "url1",
Setting_Page_Url = "url2",
Share_Page_Url = "url3",
}
const home = PageUrl.Home_Page_Url;这么做的好处非常明显。首先,你拥有了更好的类型提示。其次,这些常量被真正地约束在一个命名空间下(上面的对象声明总是差点意思)。如果你没有声明枚举的值,它会默认使用数字枚举,并且从 0 开始,以 1 递增:
enum Items {
Foo,
Bar,
Baz
}在这个例子中,Items.Foo , Items.Bar , Items.Baz的值依次是 0,1,2 。
如果你只为某一个成员指定了枚举值,那么之前未赋值成员仍然会使用从 0 递增的方式,之后的成员则会开始从枚举值递增。
enum Items {
// 0
Foo,
Bar = 599,
// 600
Baz
}在数字型枚举中,你可以使用延迟求值的枚举值,比如函数:
const returnNum = () => 100 + 499;
enum Items {
Foo = returnNum(),
Bar = 599,
Baz
}但要注意,延迟求值的枚举值是有条件的。如果你使用了延迟求值,那么没有使用延迟求值的枚举成员必须放在使用常量枚举值声明的成员之后(如上例),或者放在第一位:
enum Items {
Baz,
Foo = returnNum(),
Bar = 599,
}TypeScript 中也可以同时使用字符串枚举值和数字枚举值:
enum Mixed {
Num = 599,
Str = "linbudu"
}枚举和对象的重要差异在于,对象是单向映射的,我们只能从键映射到键值。而枚举是双向映射的,即你可以从枚举成员映射到枚举值,也可以从枚举值映射到枚举成员:
enum Items {
Foo,
Bar,
Baz
}
const fooValue = Items.Foo; // 0
const fooKey = Items[0]; // "Foo"要了解这一现象的本质,我们需要来看一看枚举的编译产物,如以上的枚举会被编译为以下 JavaScript 代码:
"use strict";
var Items;
(function (Items) {
Items[Items["Foo"] = 0] = "Foo";
Items[Items["Bar"] = 1] = "Bar";
Items[Items["Baz"] = 2] = "Baz";
})(Items || (Items = {}));obj[k] = v 的返回值即是 v,因此这里的 obj[obj[k] = v] = k 本质上就是进行了 obj[k] = v 与 obj[v] = k 这样两次赋值。
但需要注意的是,仅有值为数字的枚举成员才能够进行这样的双向枚举,字符串枚举成员仍然只会进行单次映射:
enum Items {
Foo,
Bar = "BarValue",
Baz = "BazValue"
}
// 编译结果,只会进行 键-值 的单向映射
"use strict";
var Items;
(function (Items) {
Items[Items["Foo"] = 0] = "Foo";
Items["Bar"] = "BarValue";
Items["Baz"] = "BazValue";
})(Items || (Items = {}));除了数字枚举与字符串枚举这种分类以外,其实还存在着普通枚举与常量枚举这种分类方式。
常量枚举
常量枚举和枚举相似,只是其声明多了一个 const:
const enum Items {
Foo,
Bar,
Baz
}
const fooValue = Items.Foo; // 0它和普通枚举的差异主要在访问性与编译产物。对于常量枚举,你只能通过枚举成员访问枚举值(而不能通过值访问成员)。同时,在编译产物中并不会存在一个额外的辅助对象(如上面的 Items 对象),对枚举成员的访问会被直接内联替换为枚举的值。以上的代码会被编译为如下形式:
const fooValue = 0 /* Foo */; // 0TIP
实际上,常量枚举的表现、编译产物还受到配置项 --isolatedModules 以及 --preserveConstEnums 等的影响,我们会在后面的 TSConfig 详解中了解更多。
类型控制流分析中的字面量类型
除了手动声明字面量类型以外,实际上 TypeScript 也会在某些情况下将变量类型推导为字面量类型,看这个例子:
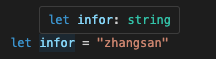
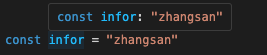
你会发现,使用 const 声明的变量,其类型会从值推导出最精确的字面量类型。而对象类型则只会推导至符合其属性结构的接口,不会使用字面量类型:
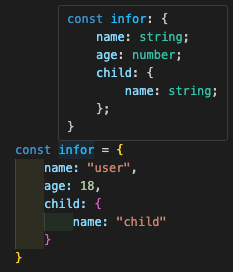
要解答这个现象,需要你回想 let 和 const 声明的意义。我们知道,使用 let 声明的变量是可以再次赋值的,在 TypeScript 中要求赋值类型始终与原类型一致(如果声明了的话)。因此对于 let 声明,只需要推导至这个值从属的类型即可。而 const 声明的原始类型变量将不再可变,因此类型可以直接一步到位收窄到最精确的字面量类型,但对象类型变量仍可变(但同样会要求其属性值类型保持一致)。
这些现象的本质都是 TypeScript 的类型控制流分析,我们会在后面的类型系统部分中讲到。
详解函数重载与面向对象
我们了解了日常开发中最常用的、基础的变量类型标注,包括原始类型、对象类型、字面量类型与枚举类型。而实际开发中还有一个重要的朋友:函数。函数能够帮助我们进一步抽离与封装代码逻辑,所以掌握函数类型必不可少。如果说函数代表着面向过程的编程,那么 Class 则代表着面向对象的编程
函数
函数的类型签名
如果说变量的类型是描述了这个变量的值类型,那么函数的类型就是描述了函数入参类型与函数返回值类型,它们同样使用:的语法进行类型标注。我们直接看最简单的例子:
function foo(name: string): number {
return name.length;
}在函数类型中同样存在着类型推导。比如在这个例子中,你可以不写返回值处的类型,它也能被正确推导为 number 类型。
在 JavaScript 中,我们称 function name () {} 这一声明函数的方式为函数声明(Function Declaration)。除了函数声明以外,我们还可以通过函数表达式(Function Expression),即 const foo = function(){} 的形式声明一个函数。在表达式中进行类型声明的方式是这样的:
const foo = function (name: string): number {
return name.length
}我们也可以像对变量进行类型标注那样,对 foo 这个变量进行类型声明:
const foo: (name: string) => number = function (name) {
return name.length
}这里的 (name: string) => number 看起来很眼熟,对吧?它是 ES6 的重要特性之一:箭头函数。但在这里,它其实是 TypeScript 中的函数类型签名。而实际的箭头函数,我们的类型标注也是类似的:
// 方式一
const foo = (name: string): number => {
return name.length
}// 方式二
const foo: (name: string) => number = (name) => {
return name.length
}在方式二的声明方式中,你会发现函数类型声明混合箭头函数声明时,代码的可读性会非常差。因此,一般不推荐这么使用,要么直接在函数中进行参数和返回值的类型声明,要么使用类型别名将函数声明抽离出来:
type FuncFoo = (name: string) => number
const foo: FuncFoo = (name) => {
return name.length
}如果只是为了描述这个函数的类型结构,我们甚至可以使用 interface 来进行函数声明:
interface FuncFooStruct {
(name: string): number
}这时的 interface 被称为 Callable Interface,看起来可能很奇怪,但我们可以这么认为,interface 就是用来描述一个类型结构的,而函数类型本质上也是一个结构固定的类型罢了。
void 类型
在 TypeScript 中,一个没有返回值(即没有调用 return 语句)的函数,其返回类型应当被标记为 void 而不是 undefined,即使它实际的值是 undefined。
// 没有调用 return 语句
function foo(): void { }
// 调用了 return 语句,但没有返回值
function bar(): void {
return;
}原因和我们在原始类型与对象类型一节中讲到的:在 TypeScript 中,undefined 类型是一个实际的、有意义的类型值,而 void 才代表着空的、没有意义的类型值。 相比之下,void 类型就像是 JavaScript 中的 null 一样。因此在我们没有实际返回值时,使用 void 类型能更好地说明这个函数没有进行返回操作。但在上面的第二个例子中,其实更好的方式是使用 undefined :
function bar(): undefined {
return;
}此时我们想表达的则是,这个函数进行了返回操作,但没有返回实际的值。
可选参数与 rest 参数
在很多时候,我们会希望函数的参数可以更灵活,比如它不一定全都必传,当你不传入参数时函数会使用此参数的默认值。正如在对象类型中我们使用 ? 描述一个可选属性一样,在函数类型中我们也使用 ? 描述一个可选参数:
// 在函数逻辑中注入可选参数默认值
function foo1(name: string, age?: number): number {
const inputAge = age || 18; // 或使用 age ?? 18
return name.length + inputAge
}
// 直接为可选参数声明默认值
function foo2(name: string, age: number = 18): number {
const inputAge = age;
return name.length + inputAge
}需要注意的是,可选参数必须位于必选参数之后。毕竟在 JavaScript 中函数的入参是按照位置(形参),而不是按照参数名(名参)进行传递。当然,我们也可以直接将可选参数与默认值合并,但此时就不能够使用 ? 了,因为既然都有默认值,那肯定是可选参数啦。
function foo(name: string, age: number = 18): number {
const inputAge = age || 18;
return name.length + inputAge
}在某些情况下,这里的可选参数类型也可以省略,如这里原始类型的情况可以直接从提供的默认值类型推导出来。但对于联合类型或对象类型的复杂情况,还是需要老老实实地进行标注。
对于 rest 参数的类型标注也比较简单,由于其实际上是一个数组,这里我们也应当使用数组类型进行标注:
function foo(arg1: string, ...rest: any[]) { }TIP
对于 any 类型,你可以简单理解为它包含了一切可能的类型,我们会在下一节详细介绍。
当然,你也可以使用我们前面学习的元组类型进行标注:
function foo(arg1: string, ...rest: [number, boolean]) { }
foo("linbudu", 18, true)重载
在某些逻辑较复杂的情况下,函数可能有多组入参类型和返回值类型:
function func(foo: number, bar?: boolean): string | number {
if (bar) {
return String(foo);
} else {
return foo * 599;
}
}在这个实例中,函数的返回类型基于其入参 bar 的值,并且从其内部逻辑中我们知道,当 bar 为 true,返回值为 string 类型,否则为 number 类型。而这里的类型签名完全没有体现这一点,我们只知道它的返回值是这么个联合类型。
要想实现与入参关联的返回值类型,我们可以使用 TypeScript 提供的函数重载签名(Overload Signature),将以上的例子使用重载改写:
function func(foo: number, bar: true): string;
function func(foo: number, bar?: false): number;
function func(foo: number, bar?: boolean): string | number {
if (bar) {
return String(foo);
} else {
return foo * 599;
}
}
const res1 = func(599); // number
const res2 = func(599, true); // string
const res3 = func(599, false); // number这里我们的三个 function func 其实具有不同的意义:
function func(foo: number, bar: true): string,重载签名一,传入bar的值为true时,函数返回值为string类型。function func(foo: number, bar?: false): number,重载签名二,不传入bar,或传入bar的值为false时,函数返回值为number类型。function func(foo: number, bar?: boolean): string | number,函数的实现签名,会包含重载签名的所有可能情况。
基于重载签名,我们就实现了将入参类型和返回值类型的可能情况进行关联,获得了更精确的类型标注能力。
TIP
这里有一个需要注意的地方,拥有多个重载声明的函数在被调用时,是按照重载的声明顺序往下查找的。因此在第一个重载声明中,为了与逻辑中保持一致,即在 bar 为 true 时返回 string 类型,这里我们需要将第一个重载声明的 bar 声明为必选的字面量类型。
TIP
你可以试着为第一个重载声明的 bar 参数也加上可选符号,然后就会发现第一个函数调用错误地匹配到了第一个重载声明。
实际上,TypeScript 中的重载更像是伪重载,它只有一个具体实现,其重载体现在方法调用的签名上而非具体实现上。而在如 C++ 等语言中,重载体现在多个名称一致但入参不同的函数实现上,这才是更广义上的函数重载。
异步函数、Generator 函数等类型签名
对于异步函数、Generator 函数、异步 Generator 函数的类型签名,其参数签名基本一致,而返回值类型则稍微有些区别:
async function asyncFunc(): Promise<void> {}
function* genFunc(): Iterable<void> {}
async function* asyncGenFunc(): AsyncIterable<void> {}其中,Generator 函数与异步 Generator 函数现在已经基本不再使用,这里仅做了解即可。而对于异步函数(即标记为 async 的函数),其返回值必定为一个 Promise 类型,而 Promise 内部包含的类型则通过泛型的形式书写,即 Promise<T>(关于泛型我们会在后面进行详细了解)。
在函数这一节中,我们主要关注函数的类型标注。因为 TypeScript 中的函数实际上相比 JavaScript 也只是多在重载这一点上,我们需要着重掌握的仍然是类型标注。但在 Class 中,我们的学习重点其实更侧重于其语法与面向对象的编程理念。
Class
类与类成员的类型签名
一个函数的主要结构即是参数、逻辑和返回值,对于逻辑的类型标注其实就是对普通代码的标注,所以我们只介绍了对参数以及返回值的类型标注。而到了 Class 中其实也一样,它的主要结构只有构造函数、属性、方法和访问符(Accessor),我们也只需要关注这三个部分即可。这里我要说明一点,有的同学可能认为装饰器也是 Class 的结构,但我个人认为它并不是 Class 携带的逻辑,不应该被归类在这里。
属性的类型标注类似于变量,而构造函数、方法、存取器的类型编标注类似于函数:
class Foo {
prop: string;
constructor(inputProp: string) {
this.prop = inputProp;
}
print(addon: string): void {
console.log(`${this.prop} and ${addon}`)
}
get propA(): string {
return `${this.prop}+A`;
}
set propA(value: string) {
this.prop = `${value}+A`
}
}唯一需要注意的是,setter 方法不允许进行返回值的类型标注,你可以理解为 setter 的返回值并不会被消费,它是一个只关注过程的函数。类的方法同样可以进行函数那样的重载,且语法基本一致,这里我们不再赘述。
就像函数可以通过函数声明与函数表达式创建一样,类也可以通过类声明和类表达式的方式创建。很明显上面的写法即是类声明,而使用类表达式的语法则是这样的:
const Foo = class {
prop: string;
constructor(inputProp: string) {
this.prop = inputProp;
}
print(addon: string): void {
console.log(`${this.prop} and ${addon}`)
}
// ...
}修饰符
在 TypeScript 中我们能够为 Class 成员添加这些修饰符:public / private / protected / readonly。除 readonly 以外,其他三位都属于访问性修饰符,而 readonly 属于操作性修饰符(就和 interface 中的 readonly 意义一致)。
这些修饰符应用的位置在成员命名前:
class Foo {
private prop: string;
constructor(inputProp: string) {
this.prop = inputProp;
}
protected print(addon: string): void {
console.log(`${this.prop} and ${addon}`)
}
public get propA(): string {
return `${this.prop}+A`;
}
public set propA(value: string) {
this.propA = `${value}+A`
}
}TIP
我们通常不会为构造函数添加修饰符,而是让它保持默认的 public。在后面我们会讲到 private 修饰构造函数的场景。
如果没有其他语言学习经验,你可能不太理解 public / private / protected 的意义,我们简单做个解释。
public:此类成员在类、类的实例、子类中都能被访问。private:此类成员仅能在类的内部被访问。protected:此类成员仅能在类与子类中被访问,你可以将类和类的实例当成两种概念,即一旦实例化完毕(出厂零件),那就和类(工厂)没关系了,即不允许再访问受保护的成员。
当你不显式使用访问性修饰符,成员的访问性默认会被标记为 public。实际上,在上面的例子中,我们通过构造函数为类成员赋值的方式还是略显麻烦,需要声明类属性以及在构造函数中进行赋值。简单起见,我们可以在构造函数中对参数应用访问性修饰符:
class Foo {
constructor(public arg1: string, private arg2: boolean) { }
}
new Foo("linbudu", true)此时,参数会被直接作为类的成员(即实例的属性),免去后续的手动赋值。
静态成员
在 TypeScript 中,你可以使用 static 关键字来标识一个成员为静态成员:
class Foo {
static staticHandler() { }
public instanceHandler() { }
}不同于实例成员,在类的内部静态成员无法通过 this 来访问,需要通过 Foo.staticHandler 这种形式进行访问。我们可以查看编译到 ES5 及以下 target 的 JavaScript 代码(ES6 以上就原生支持静态成员了),来进一步了解它们的区别:
var Foo = /** @class */ (function () {
function Foo() {
}
Foo.staticHandler = function () { };
Foo.prototype.instanceHandler = function () { };
return Foo;
}());从中我们可以看到,静态成员直接被挂载在函数体上,而实例成员挂载在原型上,这就是二者的最重要差异:静态成员不会被实例继承,它始终只属于当前定义的这个类(以及其子类)。而原型对象上的实例成员则会沿着原型链进行传递,也就是能够被继承。
而对于静态成员和实例成员的使用时机,其实并不需要非常刻意地划分。比如我会用类 + 静态成员来收敛变量与 utils 方法:
class Utils {
public static identifier = "linbudu";
public static makeUHappy() {
Utils.studyWithU();
// ...
}
public static studyWithU() { }
}
Utils.makeUHappy();继承、实现、抽象类
既然说到 Class,那就一定离不开继承。与 JavaScript 一样,TypeScript 中也使用 extends 关键字来实现继承:
class Base { }
class Derived extends Base { }对于这里的两个类,比较严谨的称呼是 基类(Base) 与 派生类(Derived)。当然,如果你觉得叫父类与子类更容易理解也没问题。关于基类与派生类,我们需要了解的主要是派生类对基类成员的访问与覆盖操作。
基类中的哪些成员能够被派生类访问,完全是由其访问性修饰符决定的。我们在上面其实已经介绍过,派生类中可以访问到使用 public 或 protected 修饰符的基类成员。除了访问以外,基类中的方法也可以在派生类中被覆盖,但我们仍然可以通过 super 访问到基类中的方法:
class Base {
print() { }
}
class Derived extends Base {
print() {
super.print()
// ...
}
}在派生类中覆盖基类方法时,我们并不能确保派生类的这一方法能覆盖基类方法,万一基类中不存在这个方法呢?所以,TypeScript 4.3 新增了 override 关键字,来确保派生类尝试覆盖的方法一定在基类中存在定义:
class Base {
printWithLove() { }
}
class Derived extends Base {
override print() {
// ...
}
}在这里 TS 将会给出错误,因为尝试覆盖的方法并未在基类中声明。通过这一关键字我们就能确保首先这个方法在基类中存在,同时标识这个方法在派生类中被覆盖了。
除了基类与派生类以外,还有一个比较重要的概念:抽象类。抽象类是对类结构与方法的抽象,简单来说,一个抽象类描述了一个类中应当有哪些成员(属性、方法等),一个抽象方法描述了这一方法在实际实现中的结构。我们知道类的方法和函数非常相似,包括结构,因此抽象方法其实描述的就是这个方法的入参类型与返回值类型。
抽象类使用 abstract 关键字声明:
abstract class AbsFoo {
abstract absProp: string;
abstract get absGetter(): string;
abstract absMethod(name: string): string
}注意,抽象类中的成员也需要使用 abstract 关键字才能被视为抽象类成员,如这里的抽象方法。我们可以实现(implements)一个抽象类:
class Foo implements AbsFoo {
absProp: string = "linbudu"
get absGetter() {
return "linbudu"
}
absMethod(name: string) {
return name
}
}此时,我们必须完全实现这个抽象类的每一个抽象成员。需要注意的是,在 TypeScript 中无法声明静态的抽象成员。
对于抽象类,它的本质就是描述类的结构。看到结构,你是否又想到了 interface?是的。interface 不仅可以声明函数结构,也可以声明类的结构:
interface FooStruct {
absProp: string;
get absGetter(): string;
absMethod(input: string): string
}
class Foo implements FooStruct {
absProp: string = "linbudu"
get absGetter() {
return "linbudu"
}
absMethod(name: string) {
return name
}
}在这里,我们让类去实现了一个接口。这里接口的作用和抽象类一样,都是描述这个类的结构。除此以外,我们还可以使用 Newable Interface 来描述一个类的结构(类似于描述函数结构的 Callable Interface):
class Foo { }
interface FooStruct {
new(): Foo
}
declare const NewableFoo: FooStruct;
const foo = new NewableFoo();私有构造函数
上面说到,我们通常不会对类的构造函数进行访问性修饰,如果我们一定要试试呢?
class Foo {
private constructor() { }
}看起来好像没什么问题,但是当你想要实例化这个类时,一行美丽的操作就会出现:类的构造函数被标记为私有,且只允许在类内部访问。
有些场景下私有构造函数确实有奇妙的用法,比如像我一样把类作为 utils 方法时,此时 Utils 类内部全部都是静态成员,我们也并不希望真的有人去实例化这个类。此时就可以使用私有构造函数来阻止它被错误地实例化:
class Utils {
public static identifier = "linbudu";
private constructor(){}
public static makeUHappy() {
}
}或者在一个类希望把实例化逻辑通过方法来实现,而不是通过 new 的形式时,也可以使用私有构造函数来达成目的。
SOLID 原则
SOLID 原则是面向对象编程中的基本原则,它包括以下这些五项基本原则:
- S(单一功能原则):一个类应该仅具有一种职责,这也意味着只存在一种原因使得需要修改类的代码。 如对于一个数据实体的操作,其读操作和写操作也应当被视为两种不同的职责,并被分配到两个类中。更进一步,对实体的业务逻辑和对实体的入库逻辑也都应该被拆分开来。
- O(开放封闭原则):一个类应该是可扩展但不可修改的。即假设我们的业务中支持通过微信、支付宝登录,原本在一个
login方法中进行if else判断, 假设后面又新增了抖音登录、美团登录,难道要再加else if分支(或switch case)吗?ts当然不,基于开放封闭原则,我们应当将登录的基础逻辑抽离出来,不同的登录方式通过扩展这个基础类来实现自己的特殊逻辑。enum LoginType { WeChat, TaoBao, TikTok, // ... } class Login { public static handler(type: LoginType) { if (type === LoginType.WeChat) { } else if (type === LoginType.TikTok) { } else if (type === LoginType.TaoBao) { } else { throw new Error("Invalid Login Type!") } } }tsabstract class LoginHandler { abstract handler(): void } class WeChatLoginHandler implements LoginHandler { handler() { } } class TaoBaoLoginHandler implements LoginHandler { handler() { } } class TikTokLoginHandler implements LoginHandler { handler() { } } class Login { public static handlerMap: Record<LoginType, LoginHandler> = { [LoginType.TaoBao]: new TaoBaoLoginHandler(), [LoginType.TikTok]: new TikTokLoginHandler(), [LoginType.WeChat]: new WeChatLoginHandler(), } public static handler(type: LoginType) { Login.handlerMap[type].handler() } } - L(里式替换原则):一个派生类可以在程序的任何一处对其基类进行替换。这也就意味着,子类完全继承了父类的一切,对父类进行了功能地扩展(而非收窄)。
- I(接口分离原则):类的实现方应当只需要实现自己需要的那部分接口。比如微信登录支持指纹识别,支付宝支持指纹识别和人脸识别, 这个时候微信登录的实现类应该不需要实现人脸识别方法才对。这也就意味着我们提供的抽象类应当按照功能维度拆分成粒度更小的组成才对。
- D(依赖倒置原则):这是实现开闭原则的基础,它的核心思想即是对功能的实现应该依赖于抽象层,即不同的逻辑通过实现不同的抽象类。 还是登录的例子,我们的登录提供方法应该基于共同的登录抽象类实现(
LoginHandler),最终调用方法也基于这个抽象类,而不是在一个高阶登录方法中去依赖多个低阶登录提供方。
any、unknown、never 与类型断言
此前我们学习基础类型标注、字面量类型与枚举、函数与 Class 等概念时,实际上一直在用 JavaScript 的概念来进行映射,或者说这可以看作是 JavaScript 代码到 TypeScript 代码的第一步迁移。 接下来让我们使用 TypeScript 提供的内置类型在类型世界里获得更好的编程体验。
内置类型:any 、unknown 与 never
有些时候,我们的 TS 代码并不需要十分精确严格的类型标注。比如 console.log 方法就能够接受任意类型的参数,不管你是数组、字符串、对象或是其他的,统统来者不拒。那么,我们难道要把所有类型用联合类型串起来?
这当然不现实,为了能够表示“任意类型”,TypeScript 中提供了一个内置类型 any ,来表示所谓的任意类型。此时我们就可以使用 any 作为参数的类型:
log(message?: any, ...optionalParams: any[]): void在这里,一个被标记为 any 类型的参数可以接受任意类型的值。除了 message 是 any 以外,optionalParams 作为一个 rest 参数,也使用 any[] 进行了标记,这就意味着你可以使用任意类型的任意数量类型来调用这个方法。除了显式的标记一个变量或参数为 any,在某些情况下你的变量/参数也会被隐式地推导为 any。比如使用 let 声明一个变量但不提供初始值,以及不为函数参数提供类型标注:
// any
let foo;
// foo、bar 均为 any
function func(foo, bar){}以上的函数声明在 tsconfig 中启用了 noImplicitAny 时会报错,你可以显式为这两个参数指定 any 类型,或者暂时关闭这一配置(不推荐)。而 any 类型的变量几乎无所不能,它可以在声明后再次接受任意类型的值,同时可以被赋值给任意其它类型的变量:
// 被标记为 any 类型的变量可以拥有任意类型的值
let anyVar: any = "linbudu";
anyVar = false;
anyVar = "linbudu";
anyVar = {
site: "juejin"
};
anyVar = () => { }
// 标记为具体类型的变量也可以接受任何 any 类型的值
const val1: string = anyVar;
const val2: number = anyVar;
const val3: () => {} = anyVar;
const val4: {} = anyVar;你可以在 any 类型变量上任意地进行操作,包括赋值、访问、方法调用等等,此时可以认为类型推导与检查是被完全禁用的:
let anyVar: any = null;
anyVar.foo.bar.baz();
anyVar[0][1][2].prop1;而 any 类型的主要意义,其实就是为了表示一个无拘无束的“任意类型”,它能兼容所有类型,也能够被所有类型兼容。这一作用其实也意味着类型世界给你开了一个外挂,无论什么时候,你都可以使用 any 类型跳过类型检查。当然,运行时出了问题就需要你自己负责了。
TIP
any 的本质是类型系统中的顶级类型,即 Top Type,这是许多类型语言中的重要概念,我们会在类型层级部分讲解。
any 类型的万能性也导致我们经常滥用它,比如类型不兼容了就 any 一下,类型不想写了也 any 一下,不确定可能会是啥类型还是 any 一下。此时的 TypeScript 就变成了令人诟病的 AnyScript。为了避免这一情况,我们要记住以下使用小 tips :
- 如果是类型不兼容报错导致你使用
any,考虑用类型断言替代,我们下面就会开始介绍类型断言的作用。 - 如果是类型太复杂导致你不想全部声明而使用
any,考虑将这一处的类型去断言为你需要的最简类型。如你需要调用foo.bar.baz(),就可以先将foo断言为一个具有bar方法的类型。 - 如果你是想表达一个未知类型,更合理的方式是使用
unknown。
unknown 类型和 any 类型有些类似,一个 unknown 类型的变量可以再次赋值为任意其它类型,但只能赋值给 any 与 unknown 类型的变量:
let unknownVar: unknown = "linbudu";
unknownVar = false;
unknownVar = "linbudu";
unknownVar = {
site: "juejin"
};
unknownVar = () => { }
const val1: string = unknownVar; // Error
const val2: number = unknownVar; // Error
const val3: () => {} = unknownVar; // Error
const val4: {} = unknownVar; // Error
const val5: any = unknownVar;
const val6: unknown = unknownVar;unknown 和 any 的一个主要差异体现在赋值给别的变量时,any 就像是 我身化万千无处不在 ,所有类型都把它当自己人。而 unknown 就像是 我虽然身化万千,但我坚信我在未来的某一刻会得到一个确定的类型 ,只有 any 和 unknown 自己把它当自己人。简单地说,any 放弃了所有的类型检查,而 unknown 并没有。这一点也体现在对 unknown 类型的变量进行属性访问时:
let unknownVar: unknown;
unknownVar.foo(); // 报错:对象类型为 unknown要对 unknown 类型进行属性访问,需要进行类型断言(别急,马上就讲类型断言!),即**“虽然这是一个未知的类型,但我跟你保证它在这里就是这个类型!”**:
let unknownVar: unknown;
(unknownVar as { foo: () => {} }).foo();TIP
在类型未知的情况下,更推荐使用 unknown 标注。这相当于你使用额外的心智负担保证了类型在各处的结构,后续重构为具体类型时也可以获得最初始的类型信息,同时还保证了类型检查的存在。当然,unknown 用起来很麻烦,一堆类型断言写起来可不太好看。归根结底,到底用哪个完全取决于你自己,毕竟语言只是工具嘛。
如果说,any 与 unknown 是比原始类型、对象类型等更广泛的类型,也就是说它们更上层一些,就像 string 字符串类型比 'linbudu' 字符串字面量更上层一些,即 any/unknown -> 原始类型、对象类型 -> 字面量类型。那么,是否存在比字面量类型更底层一些的类型?
这里的上层与底层,其实即意味着包含类型信息的多少。any 类型包括了任意的类型,字符串类型包括任意的字符串字面量类型,而字面量类型只表示一个精确的值类型。如要还要更底层,也就是再少一些类型信息,那就只能什么都没有了。
而内置类型 never 就是这么一个什么都没有的类型。此前我们已经了解了另一个什么都没有的类型void。但相比于 void,never 还要更加空白一些。
虚无的 never 类型
是不是有点不好理解?我们看一个联合类型的例子就能 get 到一些了:
type UnionWithNever = "linbudu" | 599 | true | void | never;将鼠标悬浮在类型别名之上,你会发现这里显示的类型是"linbudu" | 599 | true | void。never 类型被直接无视掉了,而 void 仍然存在。这是因为,void 作为类型表示一个空类型,就像没有返回值的函数使用 void 来作为返回值类型标注一样,void 类型就像 JavaScript 中的 null 一样代表这里有类型,但是个空类型。
而 never 才是一个什么都没有的类型,它甚至不包括空的类型,严格来说never类型不携带任何的类型信息,因此会在联合类型中被直接移除,比如我们看 void 和 never 的类型兼容性:
declare let v1: never;
declare let v2: void;
v1 = v2; // X 类型 void 不能赋值给类型 never
v2 = v1;在编程语言的类型系统中,never 类型被称为 Bottom Type,是整个类型系统层级中最底层的类型。和 null、undefined 一样,它是所有类型的子类型,但只有 never 类型的变量能够赋值给另一个 never 类型变量。
通常我们不会显式地声明一个 never 类型,它主要被类型检查所使用。但在某些情况下使用 never 确实是符合逻辑的,比如一个只负责抛出错误的函数:
function justThrow(): never {
throw new Error()
}在类型流的分析中,一旦一个返回值类型为 never 的函数被调用,那么下方的代码都会被视为无效的代码(即无法执行到):
function justThrow(): never {
throw new Error()
}
function foo (input:number){
if(input > 1){
justThrow();
// 等同于 return 语句后的代码,即 Dead Code
const name = "linbudu";
}
}我们也可以显式利用它来进行类型检查,即上面在联合类型中 never 类型神秘消失的原因。假设,我们需要对一个联合类型的每个类型分支进行不同处理:
declare const strOrNumOrBool: string | number | boolean;
if (typeof strOrNumOrBool === "string") {
console.log("str!");
} else if (typeof strOrNumOrBool === "number") {
console.log("num!");
} else if (typeof strOrNumOrBool === "boolean") {
console.log("bool!");
} else {
throw new Error(`Unknown input type: ${strOrNumOrBool}`);
}如果我们希望这个变量的每一种类型都需要得到妥善处理,在最后可以抛出一个错误,但这是运行时才会生效的措施,是否能在类型检查时就分析出来?
实际上,由于 TypeScript 强大的类型分析能力,每经过一个 if 语句处理,strOrNumOrBool 的类型分支就会减少一个(因为已经被对应的 typeof 处理过)。而在最后的 else 代码块中,它的类型只剩下了 never 类型,即一个无法再细分、本质上并不存在的虚空类型。在这里,我们可以利用只有 never 类型能赋值给 never 类型这一点,来巧妙地分支处理检查:
if (typeof strOrNumOrBool === "string") {
// 一定是字符串!
strOrNumOrBool.charAt(1);
} else if (typeof strOrNumOrBool === "number") {
strOrNumOrBool.toFixed();
} else if (typeof strOrNumOrBool === "boolean") {
strOrNumOrBool === true;
} else {
const _exhaustiveCheck: never = strOrNumOrBool;
throw new Error(`Unknown input type: ${_exhaustiveCheck}`);
}假设某个粗心的同事新增了一个类型分支,strOrNumOrBool 变成了 strOrNumOrBoolOrFunc,却忘记新增对应的处理分支,此时在 else 代码块中就会出现将 Function 类型赋值给 never 类型变量的类型错误。这实际上就是利用了类型分析能力与 never 类型只能赋值给 never 类型这一点,来确保联合类型变量被妥善处理。
前面我们提到了主动使用 never 类型的两种方式,而 never 其实还会在某些情况下不请自来。比如说,你可能遇到过这样的类型错误:
const arr = [];
arr.push("linbudu"); // 类型“string”的参数不能赋给类型“never”的参数。此时这个未标明类型的数组被推导为了 never[] 类型,这种情况仅会在你启用了 strictNullChecks 配置,同时禁用了 noImplicitAny 配置时才会出现。解决的办法也很简单,为这个数组声明一个具体类型即可。关于这两个配置的具体作用,我们会在后面有详细的介绍。
在这一部分,我们了解了 TypeScript 中 Top Type (any / unknown) 与 Bottom Type(never)它们的表现。在讲 any 的时候,我们在小 tips 中提到,可以使用类型断言来避免对 any 类型的滥用。那么接下来,我们就来学习类型断言这一概念。
类型断言:警告编译器不准报错
类型断言能够显式告知类型检查程序当前这个变量的类型,可以进行类型分析地修正、类型。它其实就是一个将变量的已有类型更改为新指定类型的操作,它的基本语法是 as NewType,你可以将 any / unknown 类型断言到一个具体的类型:
let unknownVar: unknown;
(unknownVar as { foo: () => {} }).foo();还可以 as 到 any 来为所欲为,跳过所有的类型检查:
const str: string = "linbudu";
(str as any).func().foo().prop;也可以在联合类型中断言一个具体的分支:
function foo(union: string | number) {
if ((union as string).includes("linbudu")) { }
if ((union as number).toFixed() === '599') { }
}但是类型断言的正确使用方式是,在 TypeScript 类型分析不正确或不符合预期时,将其断言为此处的正确类型:
interface IFoo {
name: string;
}
declare const obj: {
foo: IFoo
}
const {
foo = {} as IFoo
} = obj这里从 {} 字面量类型断言为了 IFoo 类型,即为解构赋值默认值进行了预期的类型断言。当然,更严谨的方式应该是定义为 Partial<IFoo> 类型,即 IFoo 的属性均为可选的。
除了使用 as 语法以外,你也可以使用 <> 语法。它虽然书写更简洁,但效果一致,只是在 TSX 中尖括号断言并不能很好地被分析出来。你也可以通过 TypeScript ESLint 提供的 consistent-type-assertions 规则来约束断言风格。
需要注意的是,类型断言应当是在迫不得己的情况下使用的。虽然说我们可以用类型断言纠正不正确的类型分析,但类型分析在大部分场景下还是可以智能地满足我们需求的。
总的来说,在实际场景中,还是 as any 这一种操作更多。但这也是让你的代码编程 AnyScript 的罪魁祸首之一,请务必小心使用。
双重断言
如果在使用类型断言时,原类型与断言类型之间差异过大,也就是指鹿为马太过离谱,离谱到了指鹿为霸王龙的程度,TypeScript 会给你一个类型报错:
const str: string = "linbudu";
// 从 X 类型 到 Y 类型的断言可能是错误的,blabla
(str as { handler: () => {} }).handler()此时它会提醒你先断言到 unknown 类型,再断言到预期类型,就像这样:
const str: string = "linbudu";
(str as unknown as { handler: () => {} }).handler();
// 使用尖括号断言
(<{ handler: () => {} }>(<unknown>str)).handler();这是因为你的断言类型和原类型的差异太大,需要先断言到一个通用的类,即 any / unknown。这一通用类型包含了所有可能的类型,因此断言到它和从它断言到另一个类型差异不大。
非空断言
非空断言其实是类型断言的简化,它使用 ! 语法,即 obj!.func()!.prop 的形式标记前面的一个声明一定是非空的(实际上就是剔除了 null 和 undefined 类型),比如这个例子:
declare const foo: {
func?: () => ({
prop?: number | null;
})
};
foo.func().prop.toFixed();此时,func 在 foo 中不一定存在,prop 在 func 调用结果中不一定存在,且可能为 null,我们就会收获两个类型报错。如果不管三七二十一地坚持调用,想要解决掉类型报错就可以使用非空断言:
foo.func!().prop!.toFixed();其应用位置类似于可选链:
foo.func?.().prop?.toFixed();但不同的是,非空断言的运行时仍然会保持调用链,因此在运行时可能会报错。而可选链则会在某一个部分收到 undefined 或 null 时直接短路掉,不会再发生后面的调用。
非空断言的常见场景还有 document.querySelector、Array.find 方法等:
const element = document.querySelector("#id")!;
const target = [1, 2, 3, 599].find(item => item === 599)!;为什么说非空断言是类型断言的简写?因为上面的非空断言实际上等价于以下的类型断言操作:
((foo.func as () => ({
prop?: number;
}))().prop as number).toFixed();怎么样,非空断言是不是简单多了?你可以通过 non-nullable-type-assertion-style 规则来检查代码中是否存在类型断言能够被简写为非空断言的情况。
类型断言还有一种用法是作为代码提示的辅助工具,比如对于以下这个稍微复杂的接口:
interface IStruct {
foo: string;
bar: {
barPropA: string;
barPropB: number;
barMethod: () => void;
baz: {
handler: () => Promise<void>;
};
};
}假设你想要基于这个结构随便实现一个对象,你可能会使用类型标注:
const obj: IStruct = {};这个时候等待你的是一堆类型报错,你必须规规矩矩地实现整个接口结构才可以。但如果使用类型断言,我们可以在保留类型提示的前提下,不那么完整地实现这个结构:
// 这个例子是不会报错的
const obj = <IStruct>{
bar: {
baz: {},
},
};类型提示仍然存在:

在你错误地实现结构时仍然可以给到你报错信息:

类型层级初探
前面我们已经说到,any 与 unknown 属于 Top Type,表现在它们包含了所有可能的类型,而 never 属于 Bottom Type,表现在它是一个虚无的、不存在的类型。那么加上此前学习的原始类型与字面量类型等,按照类型的包含来进行划分,我们大概能梳理出这么个类型层级关系。
- 最顶级的类型,
any与unknown - 特殊的
Object,它也包含了所有的类型,但和Top Type比还是差了一层 String、Boolean、Number这些装箱类型- 原始类型与对象类型
- 字面量类型,即更精确的原始类型与对象类型嘛,需要注意的是
null和undefined并不是字面量类型的子类型 - 最底层的
never
TIP
实际上这个层级链并不完全,因为还有联合类型、交叉类型、函数类型的情况,我们会在后面专门有一节进行讲解~
而实际上类型断言的工作原理也和类型层级有关,在判断断言是否成立,即差异是否能接受时,实际上判断的即是这两个类型是否能够找到一个公共的父类型。比如 { } 和 { name: string } 其实可以认为拥有公共的父类型 {}(一个新的 {}!你可以理解为这是一个基类,参与断言的 { } 和 { name: string } 其实是它的派生类)。
如果找不到具有意义的公共父类型呢?这个时候就需要请出 Top Type 了,如果我们把它先断言到 Top Type,那么就拥有了公共父类型 Top Type,再断言到具体的类型也是同理。你可以理解为先向上断言,再向下断言,比如前面的双重断言可以改写成这样:
const str: string = "linbudu";
(str as (string | { handler: () => {} }) as { handler: () => {} }).handler();类型工具
在实际的类型编程中,为了满足各种需求下的类型定义,我们通常会结合使用这些类型工具。因此,我们一定要清楚这些类型工具各自的使用方法和功能。如果按照使用方式来划分,类型工具可以分成三类:操作符、关键字与专用语法。而按照使用目的来划分,类型工具可以分为 类型创建 与 类型安全保护 两类。
类型别名
类型别名可以说是 TypeScript 类型编程中最重要的一个功能,从一个简单的函数类型别名,到让你眼花缭乱的类型体操,都离不开类型别名。虽然很重要,但它的使用却并不复杂:
type A = string;我们通过 type 关键字声明了一个类型别名 A ,同时它的类型等价于 string 类型。类型别名的作用主要是对一组类型或一个特定类型结构进行封装,以便于在其它地方进行复用。
比如抽离一组联合类型:
type StatusCode = 200 | 301 | 400 | 500 | 502;
type PossibleDataTypes = string | number | (() => unknown);
const status: StatusCode = 502;抽离一个函数类型:
type Handler = (e: Event) => void;
const clickHandler: Handler = (e) => { };
const moveHandler: Handler = (e) => { };
const dragHandler: Handler = (e) => { };声明一个对象类型,就像接口那样:
type ObjType = {
name: string;
age: number;
}看起来类型别名真的非常简单,不就是声明了一个变量让类型声明更简洁和易于拆分吗?如果真的只是把它作为类型别名,用来进行特定类型的抽离封装,那的确很简单。然而,类型别名还能作为工具类型。工具类同样基于类型别名,只是多了个泛型。
TIP
如果你还不了解泛型也无需担心,现阶段我们只要了解它和类型别名相关的使用就可以了。至于更复杂的泛型使用场景,我们后面会详细了解。
在类型别名中,类型别名可以这么声明自己能够接受泛型(我称之为泛型坑位)。一旦接受了泛型,我们就叫它工具类型:
type Factory<T> = T | number | string;虽然现在类型别名摇身一变成了工具类型,但它的基本功能仍然是创建类型,只不过工具类型能够接受泛型参数,实现更灵活的类型创建功能。从这个角度看,工具类型就像一个函数一样,泛型是入参,内部逻辑基于入参进行某些操作,再返回一个新的类型。比如在上面这个工具类型中,我们就简单接受了一个泛型,然后把它作为联合类型的一个成员,返回了这个联合类型。
const foo: Factory<boolean> = true;当然,我们一般不会直接使用工具类型来做类型标注,而是再度声明一个新的类型别名:
type FactoryWithBool = Factory<boolean>;
const foo: FactoryWithBool = true;同时,泛型参数的名称(上面的 T )也不是固定的。通常我们使用大写的 T / K / U / V / M / O ...这种形式。如果为了可读性考虑,我们也可以写成大驼峰形式(即在驼峰命名的基础上,首字母也大写)的名称,比如:
type Factory<NewType> = NewType | number | string;声明一个简单、有实际意义的工具类型:
type MaybeNull<T> = T | null;这个工具类型会接受一个类型,并返回一个包括 null 的联合类型。这样一来,在实际使用时就可以确保你处理了可能为空值的属性读取与方法调用:
type MaybeNull<T> = T | null;
function process(input: MaybeNull<{ handler: () => {} }>) {
input?.handler();
}类似的还有 MaybePromise、MaybeArray。这也是我在日常开发中最常使用的一类工具类型:
type MaybeArray<T> = T | T[];
// 函数泛型我们会在后面了解~
function ensureArray<T>(input: MaybeArray<T>): T[] {
return Array.isArray(input) ? input : [input];
}另外,类型别名中可以接受任意个泛型,以及为泛型指定约束、默认值等,这些内容我们都会在泛型一节深入了解。
总之,对于工具类型来说,它的主要意义是基于传入的泛型进行各种类型操作,得到一个新的类型。而这个类型操作的指代就非常非常广泛了,甚至说类型编程的大半难度都在这儿呢,这也是这本小册占据篇幅最多的部分。
联合类型与交叉类型
在原始类型与对象类型一节,我们了解了联合类型。但实际上,联合类型还有一个和它有点像的孪生兄弟:交叉类型。它和联合类型的使用位置一样,只不过符号是&,即按位与运算符。
实际上,正如联合类型的符号是|,它代表了按位或,即只需要符合联合类型中的一个类型,既可以认为实现了这个联合类型,如A | B,只需要实现 A 或 B 即可。
我们声明一个交叉类型:
interface NameStruct {
name: string;
}
interface AgeStruct {
age: number;
}
type ProfileStruct = NameStruct & AgeStruct;
const profile: ProfileStruct = {
name: "linbudu",
age: 18
}很明显这里的 profile 对象需要同时符合这两个对象的结构。从另外一个角度来看,ProfileStruct 其实就是一个新的,同时包含 NameStruct 和 AgeStruct 两个接口所有属性的类型。这里是对于对象类型的合并,那对于原始类型呢?
type StrAndNum = string & number; // never我们可以看到,它竟然变成 never 了!看起来很奇怪,但想想我们前面给出的定义,新的类型会同时符合交叉类型的所有成员,存在既是 string 又是 number 的类型吗?当然不。实际上,这也是 never 这一 BottomType 的实际意义之一,描述根本不存在的类型嘛。
对于对象类型的交叉类型,其内部的同名属性类型同样会按照交叉类型进行合并:
type Struct1 = {
primitiveProp: string;
objectProp: {
name: string;
}
}
type Struct2 = {
primitiveProp: number;
objectProp: {
age: number;
}
}
type Composed = Struct1 & Struct2;
type PrimitivePropType = Composed['primitiveProp']; // never
type ObjectPropType = Composed['objectProp']; // { name: string; age: number; }如果是两个联合类型组成的交叉类型呢?其实还是类似的思路,既然只需要实现一个联合类型成员就能认为是实现了这个联合类型,那么各实现两边联合类型中的一个就行了,也就是两边联合类型的交集:
type UnionIntersection1 = (1 | 2 | 3) & (1 | 2); // 1 | 2
type UnionIntersection2 = (string | number | symbol) & string; // string总结一下交叉类型和联合类型的区别就是,联合类型只需要符合成员之一即可(||),而交叉类型需要严格符合每一位成员(&&)。
索引类型
索引类型指的不是某一个特定的类型工具,它其实包含三个部分:索引签名类型、索引类型查询与索引类型访问。目前很多社区的学习教程并没有这一点进行说明,实际上这三者都是独立的类型工具。唯一共同点是,它们都通过索引的形式来进行类型操作,但索引签名类型是声明,后两者则是读取。接下来,我们来依次介绍三个部分。
索引签名类型
索引签名类型主要指的是在接口或类型别名中,通过以下语法来快速声明一个键值类型一致的类型结构:
interface AllStringTypes {
[key: string]: string;
}
type AllStringTypes = {
[key: string]: string;
}这时,即使你还没声明具体的属性,对于这些类型结构的属性访问也将全部被视为 string 类型:
interface AllStringTypes {
[key: string]: string;
}
type PropType1 = AllStringTypes['linbudu']; // string
type PropType2 = AllStringTypes['599']; // string在这个例子中我们声明的键的类型为 string([key: string]),这也意味着在实现这个类型结构的变量中只能声明字符串类型的键:
interface AllStringTypes {
[key: string]: string;
}
const foo: AllStringTypes = {
"linbudu": "599"
}但由于 JavaScript 中,对于 obj[prop] 形式的访问会将数字索引访问转换为字符串索引访问,也就是说, obj[599] 和 obj['599'] 的效果是一致的。因此,在字符串索引签名类型中我们仍然可以声明数字类型的键。类似的,symbol 类型也是如此:
const foo: AllStringTypes = {
"linbudu": "599",
599: "linbudu",
[Symbol("ddd")]: 'symbol',
}索引签名类型也可以和具体的键值对类型声明并存,但这时这些具体的键值类型也需要符合索引签名类型的声明:
interface AllStringTypes {
// 类型“number”的属性“propA”不能赋给“string”索引类型“boolean”。
propA: number;
[key: string]: boolean;
}这里的符合即指子类型,因此自然也包括联合类型:
interface StringOrBooleanTypes {
propA: number;
propB: boolean;
[key: string]: number | boolean;
}索引签名类型的一个常见场景是在重构 JavaScript 代码时,为内部属性较多的对象声明一个 any 的索引签名类型,以此来暂时支持对类型未明确属性的访问,并在后续一点点补全类型:
interface AnyTypeHere {
[key: string]: any;
}
const foo: AnyTypeHere['linbudu'] = 'any value';索引类型查询
刚才我们已经提到了索引类型查询,也就是 keyof 操作符。严谨地说,它可以将对象中的所有键转换为对应字面量类型,然后再组合成联合类型。注意,这里并不会将数字类型的键名转换为字符串类型字面量,而是仍然保持为数字类型字面量。
interface Foo {
linbudu: 1,
599: 2
}
type FooKeys = keyof Foo; // "linbudu" | 599
// 在 VS Code 中悬浮鼠标只能看到 'keyof Foo'
// 看不到其中的实际值,你可以这么做:
type FooKeys = keyof Foo & {}; // "linbudu" | 599如果觉得不太好理解,我们可以写段伪代码来模拟 “从键名到联合类型” 的过程。
type FooKeys = Object.keys(Foo).join(" | ");除了应用在已知的对象类型结构上以外,你还可以直接 keyof any 来生产一个联合类型,它会由所有可用作对象键值的类型组成:string | number | symbol。也就是说,它是由无数字面量类型组成的,由此我们可以知道, keyof 的产物必定是一个联合类型。
索引类型访问
在 JavaScript 中我们可以通过 obj[expression] 的方式来动态访问一个对象属性(即计算属性),expression 表达式会先被执行,然后使用返回值来访问属性。而 TypeScript 中我们也可以通过类似的方式,只不过这里的 expression 要换成类型。接下来,我们来看个例子:
interface NumberRecord {
[key: string]: number;
}
type PropType = NumberRecord[string]; // number这里,我们使用 string 这个类型来访问 NumberRecord。由于其内部声明了数字类型的索引签名,这里访问到的结果即是 number 类型。注意,其访问方式与返回值均是类型。
更直观的例子是通过字面量类型来进行索引类型访问:
interface Foo {
propA: number;
propB: boolean;
}
type PropAType = Foo['propA']; // number
type PropBType = Foo['propB']; // boolean看起来这里就是普通的值访问,但实际上这里的'propA'和'propB'都是字符串字面量类型,而不是一个 JavaScript 字符串值。索引类型查询的本质其实就是,通过键的字面量类型('propA')访问这个键对应的键值类型(number)。
看到这你肯定会想到,上面的 keyof 操作符能一次性获取这个对象所有的键的字面量类型,是否能用在这里?当然,这可是 TypeScript 啊。
interface Foo {
propA: number;
propB: boolean;
propC: string;
}
type PropTypeUnion = Foo[keyof Foo]; // string | number | boolean使用字面量联合类型进行索引类型访问时,其结果就是将联合类型每个分支对应的类型进行访问后的结果,重新组装成联合类型。索引类型查询、索引类型访问通常会和映射类型一起搭配使用,前两者负责访问键,而映射类型在其基础上访问键值类型,我们在下面一个部分就会讲到。
注意,在未声明索引签名类型的情况下,我们不能使用 NumberRecord[string] 这种原始类型的访问方式,而只能通过键名的字面量类型来进行访问。
interface Foo {
propA: number;
}
// 类型“Foo”没有匹配的类型“string”的索引签名。
type PropAType = Foo[string];索引类型的最佳拍档之一就是映射类型,同时映射类型也是类型编程中常用的一个手段。
映射类型:类型编程的第一步
不同于索引类型包含好几个部分,映射类型指的就是一个确切的类型工具。看到映射这个词你应该能联想到 JavaScript 中数组的 map 方法,实际上也是如此,映射类型的主要作用即是基于键名映射到键值类型。概念不好理解,我们直接来看例子:
type Stringify<T> = {
[K in keyof T]: string;
};这个工具类型会接受一个对象类型(假设我们只会这么用),使用 keyof 获得这个对象类型的键名组成字面量联合类型,然后通过映射类型(即这里的 in 关键字)将这个联合类型的每一个成员映射出来,并将其键值类型设置为 string。
具体使用的表现是这样的:
interface Foo {
prop1: string;
prop2: number;
prop3: boolean;
prop4: () => void;
}
type StringifiedFoo = Stringify<Foo>;
// 等价于
interface StringifiedFoo {
prop1: string;
prop2: string;
prop3: string;
prop4: string;
}我们还是可以用伪代码的形式进行说明:
const StringifiedFoo = {};
for (const k of Object.keys(Foo)){
StringifiedFoo[k] = string;
}看起来好像很奇怪,我们应该很少会需要把一个接口的所有属性类型映射到 string?这有什么意义吗?别忘了,既然拿到了键,那键值类型其实也能拿到:
type Clone<T> = {
[K in keyof T]: T[K];
};这里的T[K]其实就是上面说到的索引类型访问,我们使用键的字面量类型访问到了键值的类型,这里就相当于克隆了一个接口。需要注意的是,这里其实只有 K in 属于映射类型的语法,keyof T 属于 keyof 操作符,[K in keyof T]的[]属于索引签名类型,T[K]属于索引类型访问。
总结
以下这张表格概括了类型工具的实现方式与常见搭配:
| 类型工具 | 创建新类型的方式 | 常见搭配 |
|---|---|---|
| 类型别名(Type Alias) | 将一组类型/类型结构封装,作为一个新的类型 | 联合类型、映射类型 |
| 工具类型(Tool Type) | 在类型别名的基础上,基于泛型去动态创建新类型 | 基本所有类型工具 |
| 联合类型(Union Type) | 创建一组类型集合,满足其中一个类型即满足这个联合类型( | |
| 交叉类型(Intersection Type) | 创建一组类型集合,满足其中所有类型才满足映射联合类型(&&) | 类型别名、工具类型 |
| 索引签名类型(Index Signature Type) | 声明一个拥有任意属性,键值类型一致的接口结构 | 映射类型 |
| 索引类型查询(Indexed Type Query) | 从一个接口结构,创建一个由其键名字符串字面量组成的联合类型 | 映射类型 |
| 索引类型访问(Indexed Access Type) | 从一个接口结构,使用键名字符串字面量访问到对应的键值类型 | 类型别名、映射类型 |
| 映射类型 (Mapping Type) | 从一个联合类型依次映射到其内部的每一个类型 | 工具类型 |
前面我们主要了解了类型别名、联合类型与交叉类型、索引类型与映射类型这几样类型工具。在大部分时候,这些类型工具的作用是基于已有的类型去创建出新的类型,即类型工具的重要作用之一。
而除了类型的创建以外,类型的安全保障同样属于类型工具的能力之一,我们本节要介绍的就是两个主要用于类型安全的类型工具:类型查询操作符与类型守卫。
类型查询操作符:熟悉又陌生的 typeof
TypeScript 存在两种功能不同的 typeof 操作符。我们最常见的一种 typeof 操作符就是 JavaScript 中,用于检查变量类型的 typeof ,它会返回 "string" / "number" / "object" / "undefined" 等值。而除此以外, TypeScript 还新增了用于类型查询的 typeof ,即 Type Query Operator,这个 typeof 返回的是一个 TypeScript 类型:
const str = "linbudu";
const obj = { name: "linbudu" };
const nullVar = null;
const undefinedVar = undefined;
const func = (input: string) => {
return input.length > 10;
}
type Str = typeof str; // "linbudu"
type Obj = typeof obj; // { name: string; }
type Null = typeof nullVar; // null
type Undefined = typeof undefined; // undefined
type Func = typeof func; // (input: string) => boolean你不仅可以直接在类型标注中使用 typeof,还能在工具类型中使用 typeof。
const func = (input: string) => {
return input.length > 10;
}
const func2: typeof func = (name: string) => {
return name === 'linbudu'
}这里我们暂时不用深入了解 ReturnType 这个工具类型,只需要知道它会返回一个函数类型中返回值位置的类型:
const func = (input: string) => {
return input.length > 10;
}
// boolean
type FuncReturnType = ReturnType<typeof func>;绝大部分情况下,typeof 返回的类型就是当你把鼠标悬浮在变量名上时出现的推导后的类型,并且是最窄的推导程度(即到字面量类型的级别)。你也不必担心混用了这两种 typeof,在逻辑代码中使用的 typeof 一定会是 JavaScript 中的 typeof,而类型代码(如类型标注、类型别名中等)中的一定是类型查询的 typeof 。同时,为了更好地避免这种情况,也就是隔离类型层和逻辑层,类型查询操作符后是不允许使用表达式的:
const isInputValid = (input: string) => {
return input.length > 10;
}
// 不允许表达式
let isValid: typeof isInputValid("linbudu");类型守卫
TypeScript 中提供了非常强大的类型推导能力,它会随着你的代码逻辑不断尝试收窄类型,这一能力称之为类型的控制流分析(也可以简单理解为类型推导)。
这么说有点抽象,我们可以想象有一条河流,它从上而下流过你的程序,随着代码的分支分出一条条支流,在最后重新合并为一条完整的河流。在河流流动的过程中,如果遇到了有特定条件才能进入的河道(比如 if else 语句、switch case 语句等),那河流流过这里就会收集对应的信息,等到最后合并时,它们就会嚷着交流:“我刚刚流过了一个只有字符串类型才能进入的代码分支!” “我刚刚流过了一个只有函数类型才能进入的代码分支!”……就这样,它会把整个程序的类型信息都收集完毕。
function foo (input: string | number) {
if(typeof input === 'string') {}
if(typeof input === 'number') {}
// ...
}我们在 never 类型一节中学到的也是如此。在类型控制流分析下,每流过一个 if 分支,后续联合类型的分支就少了一个,因为这个类型已经在这个分支处理过了,不会进入下一个分支:
declare const strOrNumOrBool: string | number | boolean;
if (typeof strOrNumOrBool === "string") {
// 一定是字符串!
strOrNumOrBool.charAt(1);
} else if (typeof strOrNumOrBool === "number") {
// 一定是数字!
strOrNumOrBool.toFixed();
} else if (typeof strOrNumOrBool === "boolean") {
// 一定是布尔值!
strOrNumOrBool === true;
} else {
// 要是走到这里就说明有问题!
const _exhaustiveCheck: never = strOrNumOrBool;
throw new Error(`Unknown input type: ${_exhaustiveCheck}`);
}在这里,我们实际上通过 if 条件中的表达式进行了类型保护,即告知了流过这里的分析程序每个 if 语句代码块中变量会是何类型。这即是编程语言的类型能力中最重要的一部分:与实际逻辑紧密关联的类型。我们从逻辑中进行类型地推导,再反过来让类型为逻辑保驾护航。
前面我们说到,类型控制流分析就像一条河流一样流过,那 if 条件中的表达式要是现在被提取出来了怎么办?
function isString(input: unknown): boolean {
return typeof input === "string";
}
function foo(input: string | number) {
if (isString(input)) {
// 类型“string | number”上不存在属性“replace”。
(input).replace("linbudu", "linbudu599")
}
if (typeof input === 'number') { }
// ...
}奇怪的事情发生了,我们只是把逻辑提取到了外面而已,如果 isString 返回了 true,那 input 肯定也是 string 类型啊?
想象类型控制流分析这条河流,刚流进 if (isString(input)) 就戛然而止了。因为 isString 这个函数在另外一个地方,内部的判断逻辑并不在函数 foo 中。这里的类型控制流分析做不到跨函数上下文来进行类型的信息收集(但别的类型语言中可能是支持的)。
实际上,将判断逻辑封装起来提取到函数外部进行复用非常常见。为了解决这一类型控制流分析的能力不足,TypeScript 引入了 is 关键字来显式地提供类型信息:
function isString(input: unknown): input is string {
return typeof input === "string";
}
function foo(input: string | number) {
if (isString(input)) {
// 正确了
(input).replace("linbudu", "linbudu599")
}
if (typeof input === 'number') { }
// ...
}isString 函数称为类型守卫,在它的返回值中,我们不再使用 boolean 作为类型标注,而是使用 input is string 这么个奇怪的搭配,拆开来看它是这样的:
input函数的某个参数;is string,即 is 关键字 + 预期类型,即如果这个函数成功返回为true,那么is关键字前这个入参的类型,就会被这个类型守卫调用方后续的类型控制流分析收集到。
需要注意的是,类型守卫函数中并不会对判断逻辑和实际类型的关联进行检查:
function isString(input: unknown): input is number {
return typeof input === "string";
}
function foo(input: string | number) {
if (isString(input)) {
// 报错,在这里变成了 number 类型
(input).replace("linbudu", "linbudu599")
}
if (typeof input === 'number') { }
// ...
}从这个角度来看,其实类型守卫有些类似于类型断言,但类型守卫更宽容,也更信任你一些。你指定什么类型,它就是什么类型。 除了使用简单的原始类型以外,我们还可以在类型守卫中使用对象类型、联合类型等,比如下面我开发时常用的两个守卫:
export type Falsy = false | "" | 0 | null | undefined;
export const isFalsy = (val: unknown): val is Falsy => !val;
// 不包括不常用的 symbol 和 bigint
export type Primitive = string | number | boolean | undefined;
export const isPrimitive = (val: unknown): val is Primitive => ['string', 'number', 'boolean' , 'undefined'].includes(typeof val);除了使用 typeof 以外,我们还可以使用许多类似的方式来进行类型保护,只要它能够在联合类型的类型成员中起到筛选作用。
基于 in 与 instanceof 的类型保护
in 操作符 并不是 TypeScript 中新增的概念,而是 JavaScript 中已有的部分,它可以通过 key in object 的方式来判断 key 是否存在于 object 或其原型链上(返回 true 说明存在)。
既然能起到区分作用,那么 TypeScript 中自然也可以用它来保护类型:
interface Foo {
foo: string;
fooOnly: boolean;
shared: number;
}
interface Bar {
bar: string;
barOnly: boolean;
shared: number;
}
function handle(input: Foo | Bar) {
if ('foo' in input) {
input.fooOnly;
} else {
input.barOnly;
}
}这里的 foo / bar、fooOnly / barOnly、shared 属性们其实有着不同的意义。我们使用 foo 和 bar 来区分 input 联合类型,然后就可以在对应的分支代码块中正确访问到 Foo 和 Bar 独有的类型 fooOnly / barOnly。但是,如果用 shared 来区分,就会发现在分支代码块中 input 仍然是初始的联合类型:
function handle(input: Foo | Bar) {
if ('shared' in input) {
// 类型“Foo | Bar”上不存在属性“fooOnly”。类型“Bar”上不存在属性“fooOnly”。
input.fooOnly;
} else {
// 类型“never”上不存在属性“barOnly”。
input.barOnly;
}
}这里需要注意的是,Foo 与 Bar 都满足 'shared' in input 这个条件。因此在 if 分支中, Foo 与 Bar 都会被保留,那在 else 分支中就只剩下 never 类型。
这个时候肯定有人想问,为什么 shared 不能用来区分?答案很明显,因为它同时存在两个类型中不具有辨识度。而 foo / bar 和 fooOnly / barOnly 是各个类型独有的属性,因此可以作为可辨识属性(Discriminant Property 或 Tagged Property)。Foo 与 Bar 又因为存在这样具有区分能力的辨识属性,可以称为可辨识联合类型(Discriminated Unions 或 Tagged Union)。虽然它们是一堆类型的联合体,但其中每一个类型都具有一个独一无二的,能让它鹤立鸡群的属性。
这个可辨识属性可以是结构层面的,比如结构 A 的属性 prop 是数组,而结构 B 的属性 prop 是对象,或者结构 A 中存在属性 prop 而结构 B 中不存在。
它甚至可以是共同属性的字面量类型差异:
function ensureArray(input: number | number[]): number[] {
if (Array.isArray(input)) {
return input;
} else {
return [input];
}
}
interface Foo {
kind: 'foo';
diffType: string;
fooOnly: boolean;
shared: number;
}
interface Bar {
kind: 'bar';
diffType: number;
barOnly: boolean;
shared: number;
}
function handle1(input: Foo | Bar) {
if (input.kind === 'foo') {
input.fooOnly;
} else {
input.barOnly;
}
}如上例所示,对于同名但不同类型的属性,我们需要使用字面量类型的区分,并不能使用简单的 typeof:
function handle2(input: Foo | Bar) {
// 报错,并没有起到区分的作用,在两个代码块中都是 Foo | Bar
if (typeof input.diffType === 'string') {
input.fooOnly;
} else {
input.barOnly;
}
}除此之外,JavaScript 中还存在一个功能类似于 typeof 与 in 的操作符:instanceof,它判断的是原型级别的关系,如 foo instanceof Base 会沿着 foo 的原型链查找 Base.prototype 是否存在其上。当然,在 ES6 已经无处不在的今天,我们也可以简单地认为这是判断 foo 是否是 Base 类的实例。同样的,instanceof 也可以用来进行类型保护:
class FooBase {}
class BarBase {}
class Foo extends FooBase {
fooOnly() {}
}
class Bar extends BarBase {
barOnly() {}
}
function handle(input: Foo | Bar) {
if (input instanceof FooBase) {
input.fooOnly();
} else {
input.barOnly();
}
}除了使用 is 关键字的类型守卫以外,其实还存在使用 asserts 关键字的类型断言守卫。
类型断言守卫
如果你写过测试用例或者使用过 NodeJs 的 assert 模块,那对断言这个概念应该不陌生:
import assert from 'assert';
let name: any = 'linbudu';
assert(typeof name === 'number');
// number 类型
name.toFixed();上面这段代码在运行时会抛出一个错误,因为 assert 接收到的表达式执行结果为 false。这其实也类似类型守卫的场景:如果断言不成立,比如在这里意味着值的类型不为 number,那么在断言下方的代码就执行不到(相当于 Dead Code)。如果断言通过了,不管你最开始是什么类型,断言后的代码中就一定是符合断言的类型,比如在这里就是 number。
但断言守卫和类型守卫最大的不同点在于,在判断条件不通过时,断言守卫需要抛出一个错误,类型守卫只需要剔除掉预期的类型。 这里的抛出错误可能让你想到了 never 类型,但实际情况要更复杂一些,断言守卫并不会始终都抛出错误,所以它的返回值类型并不能简单地使用 never 类型。为此,TypeScript 3.7 版本专门引入了 asserts 关键字来进行断言场景下的类型守卫,比如前面 assert 方法的签名可以是这样的:
function assert(condition: any, msg?: string): asserts condition {
if (!condition) {
throw new Error(msg);
}
}这里使用的是 asserts condition ,而 condition 来自于实际逻辑!这也意味着,我们将 condition 这一逻辑层面的代码,作为了类型层面的判断依据,相当于在返回值类型中使用一个逻辑表达式进行了类型标注。
举例来说,对于 assert(typeof name === 'number'); 这么一个断言,如果函数成功返回,就说明其后续的代码中 condition 均成立,也就是 name 神奇地变成了一个 number 类型。
这里的 condition 甚至还可以结合使用 is 关键字来提供进一步的类型守卫能力:
let name: any = 'linbudu';
function assertIsNumber(val: any): asserts val is number {
if (typeof val !== 'number') {
throw new Error('Not a number!');
}
}
assertIsNumber(name);
// number 类型!
name.toFixed();在这种情况下,你无需再为断言守卫传入一个表达式,而是可以将这个判断用的表达式放进断言守卫的内部,来获得更独立地代码逻辑。
接口的合并
在交叉类型一节中,你可能会注意到,接口和类型别名都能直接使用交叉类型。但除此以外,接口还能够使用继承进行合并,在继承时子接口可以声明同名属性,但并不能覆盖掉父接口中的此属性。子接口中的属性类型需要能够兼容(extends)父接口中的属性类型:
interface Struct1 {
primitiveProp: string;
objectProp: {
name: string;
};
unionProp: string | number;
}
// 接口“Struct2”错误扩展接口“Struct1”。
interface Struct2 extends Struct1 {
// “primitiveProp”的类型不兼容。不能将类型“number”分配给类型“string”。
primitiveProp: number;
// 属性“objectProp”的类型不兼容。
objectProp: {
age: number;
};
// 属性“unionProp”的类型不兼容。
// 不能将类型“boolean”分配给类型“string | number”。
unionProp: boolean;
}类似的,如果你直接声明多个同名接口,虽然接口会进行合并,但这些同名属性的类型仍然需要兼容,此时的表现其实和显式扩展接口基本一致:
interface Struct1 {
primitiveProp: string;
}
interface Struct1 {
// 后续属性声明必须属于同一类型。
// 属性“primitiveProp”的类型必须为“string”,但此处却为类型“number”。
primitiveProp: number;
}这也是接口和类型别名的重要差异之一。
那么接口和类型别名之间的合并呢?其实规则一致,如接口继承类型别名,和类型别名使用交叉类型合并接口:
type Base = {
name: string;
};
interface IDerived extends Base {
// 报错!就像继承接口一样需要类型兼容
name: number;
age: number;
}
interface IBase {
name: string;
}
// 合并后的 name 同样是 never 类型
type Derived = IBase & {
name: number;
};更强大的可辨识联合类型分析
类型控制流分析其实是一直在不断增强的,在 4.5、4.6、4.7 版本中都有或多或少的场景增强。而这里说的增强,其实就包括了对可辨识联合类型的分析能力。比如下面这个例子在此前(4.6 版本以前)的 TypeScript 代码中会报错:
type Args = ['a', number] | ['b', string];
type Func = (...args: ["a", number] | ["b", string]) => void;
const f1: Func = (kind, payload) => {
if (kind === "a") {
// 仍然是 string | number
payload.toFixed();
}
if (kind === "b") {
// 仍然是 string | number
payload.toUpperCase();
}
};而在 4.6 版本中则对这一情况下的 联合类型辨识(即元组) 做了支持。
如果你有兴趣了解 TypeScript 中的类型控制流分析以及更多可辨识联合类型的场景,可以阅读:TypeScript 中的类型控制流分析演进。
无处不在的泛型
在类型工具学习中,我们已经接触过类型别名中的泛型,比如类型别名如果声明了泛型坑位,那其实就等价于一个接受参数的函数:
type Factory<T> = T | number | string;上面这个类型别名的本质就是一个函数,T 就是它的变量,返回值则是一个包含 T 的联合类型,我们可以写段伪代码来加深一下记忆:
function Factory(typeArg){
return [typeArg, number, string]
}类型别名中的泛型大多是用来进行工具类型封装,比如我们在上一节的映射类型中学习的工具类型:
type Stringify<T> = {
[K in keyof T]: string;
};
type Clone<T> = {
[K in keyof T]: T[K];
};Stringify 会将一个对象类型的所有属性类型置为 string ,而 Clone 则会进行类型的完全复制。我们可以提前看一个 TypeScript 的内置工具类型实现:
type Partial<T> = {
[P in keyof T]?: T[P];
};工具类型 Partial 会将传入的对象类型复制一份,但会额外添加一个?,还记得这代表什么吗?可选,也就是说现在我们获得了一个属性均为可选的山寨版:
interface IFoo {
prop1: string;
prop2: number;
prop3: boolean;
prop4: () => void;
}
type PartialIFoo = Partial<IFoo>;
// 等价于
interface PartialIFoo {
prop1?: string;
prop2?: number;
prop3?: boolean;
prop4?: () => void;
}类型别名与泛型的结合中,除了映射类型、索引类型等类型工具以外,还有一个非常重要的工具:条件类型。我们先来简单了解一下:
type IsEqual<T> = T extends true ? 1 : 2;
type A = IsEqual<true>; // 1
type B = IsEqual<false>; // 2
type C = IsEqual<'linbudu'>; // 2在条件类型参与的情况下,通常泛型会被作为条件类型中的判断条件(T extends Condition,或者 Type extends T)以及返回值(即 : 两端的值),这也是我们筛选类型需要依赖的能力之一。
泛型约束与默认值
像函数可以声明一个参数的默认值一样,泛型同样有着默认值的设定,比如:
type Factory<T = boolean> = T | number | string;这样在你调用时就可以不带任何参数了,默认会使用我们声明的默认值来填充。
const foo: Factory = false;再看个伪代码帮助理解:
function Factory(typeArg = boolean){
return [typeArg, number, string]
}除了声明默认值以外,泛型还能做到一样函数参数做不到的事:泛型约束。也就是说,你可以要求传入这个工具类型的泛型必须符合某些条件,否则你就拒绝进行后面的逻辑。在函数中,我们只能在逻辑中处理:
function add(source: number, add: number){
if(typeof source !== 'number' || typeof add !== 'number'){
throw new Error("Invalid arguments!")
}
return source + add;
}而在泛型中,我们可以使用 extends 关键字来约束传入的泛型参数必须符合要求。关于 extends,A extends B 意味着 A 是 B 的子类型,这里我们暂时只需要了解非常简单的判断逻辑,也就是说 A 比 B 的类型更精确,或者说更复杂。具体来说,可以分为以下几类。
- 更精确,如字面量类型是对应原始类型的子类型,即
'linbudu' extends string,599 extends number成立。类似的,联合类型子集均为联合类型的子类型,即1、1 | 2是1 | 2 | 3 | 4的子类型。 - 更复杂,如
{ name: string }是{}的子类型,因为在{}的基础上增加了额外的类型,基类与派生类(父类与子类)同理。
我们来看下面这个例子:
type ResStatus<ResCode extends number> = ResCode extends 10000 | 10001 | 10002
? 'success'
: 'failure';这个例子会根据传入的请求码判断请求是否成功,这意味着它只能处理数字字面量类型的参数,因此这里我们通过 extends number 来标明其类型约束,如果传入一个不合法的值,就会出现类型错误:
type ResStatus<ResCode extends number> = ResCode extends 10000 | 10001 | 10002
? 'success'
: 'failure';
type Res1 = ResStatus<10000>; // "success"
type Res2 = ResStatus<20000>; // "failure"
type Res3 = ResStatus<'10000'>; // 类型“string”不满足约束“number”。与此同时,如果我们想让这个类型别名可以无需显式传入泛型参数也能调用,并且默认情况下是成功地,这样就可以为这个泛型参数声明一个默认值:
type ResStatus<ResCode extends number = 10000> = ResCode extends 10000 | 10001 | 10002
? 'success'
: 'failure';
type Res4 = ResStatus; // "success"在 TypeScript 中,泛型参数存在默认约束(在下面的函数泛型、Class 泛型中也是)。这个默认约束值在 TS 3.9 版本以前是 any,而在 3.9 版本以后则为 unknown。在 TypeScript ESLint 中,你可以使用 no-unnecessary-type-constraint 规则,来避免代码中声明了与默认约束相同的泛型约束。
多泛型关联
我们不仅可以同时传入多个泛型参数,还可以让这几个泛型参数之间也存在联系。我们可以先看一个简单的场景,条件类型下的多泛型参数:
type Conditional<Type, Condition, TruthyResult, FalsyResult> =
Type extends Condition ? TruthyResult : FalsyResult;
// "passed!"
type Result1 = Conditional<'linbudu', string, 'passed!', 'rejected!'>;
// "rejected!"
type Result2 = Conditional<'linbudu', boolean, 'passed!', 'rejected!'>;这个例子表明,多泛型参数其实就像接受更多参数的函数,其内部的运行逻辑(类型操作)会更加抽象,表现在参数(泛型参数)需要进行的逻辑运算(类型操作)会更加复杂。
上面我们说,多个泛型参数之间的依赖,其实指的即是在后续泛型参数中,使用前面的泛型参数作为约束或默认值:
type ProcessInput<
Input,
SecondInput extends Input = Input,
ThirdInput extends Input = SecondInput
> = number;这里的内部类型操作并不是重点,我们直接忽略即可。从这个类型别名中你能获得哪些信息?
- 这个工具类型接受 1-3 个泛型参数。
- 第二、三个泛型参数的类型需要是首个泛型参数的子类型。
- 当只传入一个泛型参数时,其第二个泛型参数会被赋值为此参数,而第三个则会赋值为第二个泛型参数,相当于均使用了这唯一传入的泛型参数。
- 当传入两个泛型参数时,第三个泛型参数会默认赋值为第二个泛型参数的值。
多泛型关联在一些复杂的工具类型中非常常见,我们会在后续的内置类型讲解、内置类型进阶等章节中再实战,这里先了解即可。
对象类型中的泛型
由于泛型提供了对类型结构的复用能力,我们也经常在对象类型结构中使用泛型。最常见的一个例子应该还是响应类型结构的泛型处理:
interface IRes<TData = unknown> {
code: number;
error?: string;
data: TData;
}这个接口描述了一个通用的响应类型结构,预留出了实际响应数据的泛型坑位,然后在你的请求函数中就可以传入特定的响应类型了:
interface IUserProfileRes {
name: string;
homepage: string;
avatar: string;
}
function fetchUserProfile(): Promise<IRes<IUserProfileRes>> {}
type StatusSucceed = boolean;
function handleOperation(): Promise<IRes<StatusSucceed>> {}而泛型嵌套的场景也非常常用,比如对存在分页结构的数据,我们也可以将其分页的响应结构抽离出来:
interface IPaginationRes<TItem = unknown> {
data: TItem[];
page: number;
totalCount: number;
hasNextPage: boolean;
}
function fetchUserProfileList(): Promise<IRes<IPaginationRes<IUserProfileRes>>> {}这些结构看起来很复杂,但其实就是简单的泛型参数填充而已。就像我们会封装请求库、请求响应拦截器一样,对请求中的参数、响应中的数据的类型的封装其实也不应该落下。甚至在理想情况下,这些结构体封装应该在请求库封装一层中就被处理掉。
直到目前为止,我们了解的泛型似乎就是一个类型别名的参数,它需要手动传入,可以设置类型层面约束和默认值,看起来似乎没有特别神奇的地方?
接下来,我们要来看看泛型的另一面,也是你实际上会打交道最频繁的一面:类型的自动提取。
函数中的泛型
假设我们有这么一个函数,它可以接受多个类型的参数并进行对应处理,比如:
- 对于字符串,返回部分截取;
- 对于数字,返回它的 n 倍;
- 对于对象,修改它的属性并返回。
这个时候,我们要如何对函数进行类型声明?是 any 大法好?
function handle(input: any): any {}还是用联合类型来包括所有可能类型?
function handle(input: string | number | {}): string | number | {} {}第一种我们肯定要直接 pass,第二种虽然麻烦了一点,但似乎可以满足需要?但如果我们真的调用一下就知道不合适了。
const shouldBeString = handle("linbudu");
const shouldBeNumber = handle(599);
const shouldBeObject = handle({ name: "linbudu" });虽然我们约束了入参的类型,但返回值的类型并没有像我们预期的那样和入参关联起来,上面三个调用结果的类型仍然是一个宽泛的联合类型 string | number | {}。难道要用重载一个个声明可能的关联关系?
function handle(input: string): string
function handle(input: number): number
function handle(input: {}): {}
function handle(input: string | number | {}): string | number | {} { }天,如果再多一些复杂的情况,别说你愿不愿意补充每一种关联了,同事看到这样的代码都会质疑你的水平。这个时候,我们就该请出泛型了:
function handle<T>(input: T): T {}我们为函数声明了一个泛型参数 T,并将参数的类型与返回值类型指向这个泛型参数。这样,在这个函数接收到参数时,T 会自动地被填充为这个参数的类型。这也就意味着你不再需要预先确定参数的可能类型了,而在返回值与参数类型关联的情况下,也可以通过泛型参数来进行运算。
在基于参数类型进行填充泛型时,其类型信息会被推断到尽可能精确的程度,如这里会推导到字面量类型而不是基础类型。这是因为在直接传入一个值时,这个值是不会再被修改的,因此可以推导到最精确的程度。而如果你使用一个变量作为参数,那么只会使用这个变量标注的类型(在没有标注时,会使用推导出的类型)。
function handle<T>(input: T): T {}
const author = "linbudu"; // 使用 const 声明,被推导为 "linbudu"
let authorAge = 18; // 使用 let 声明,被推导为 number
handle(author); // 填充为字面量类型 "linbudu"
handle(authorAge); // 填充为基础类型 number你也可以将鼠标悬浮在表达式上,来查看填充的泛型信息:

再看一个例子:
function swap<T, U>([start, end]: [T, U]): [U, T] {
return [end, start];
}
const swapped1 = swap(["linbudu", 599]);
const swapped2 = swap([null, 599]);
const swapped3 = swap([{ name: "linbudu" }, {}]);在这里返回值类型对泛型参数进行了一些操作,而同样你可以看到其调用信息符合预期:
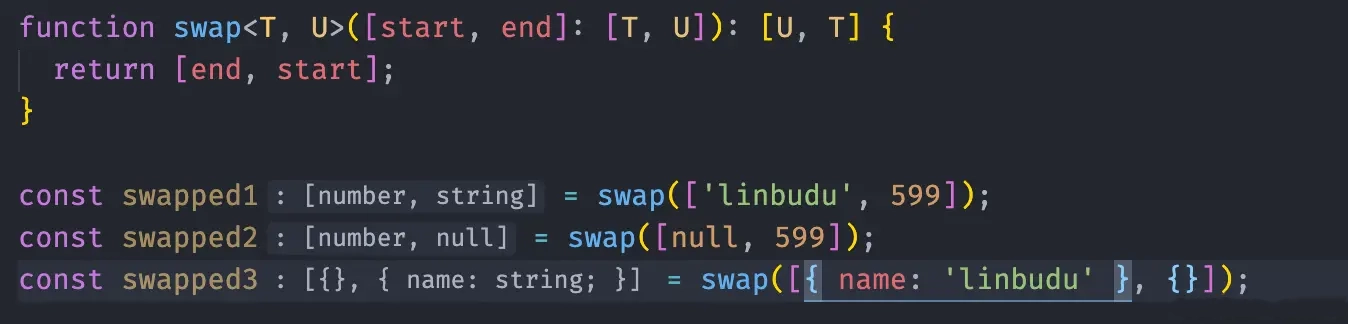
函数中的泛型同样存在约束与默认值,比如上面的 handle 函数,现在我们希望做一些代码拆分,不再处理对象类型的情况了:
function handle<T extends string | number>(input: T): T {}而 swap 函数,现在我们只想处理数字元组的情况:
function swap<T extends number, U extends number>([start, end]: [T, U]): [U, T] {
return [end, start];
}而多泛型关联也是如此,比如 lodash 的 pick 函数,这个函数首先接受一个对象,然后接受一个对象属性名组成的数组,并从这个对象中截取选择的属性部分:
const object = { 'a': 1, 'b': '2', 'c': 3 };
_.pick(object, ['a', 'c']);
// => { 'a': 1, 'c': 3 }这个函数很明显需要在泛型层面声明关联,即数组中的元素只能来自于对象的属性名(组成的字面量联合类型!),因此我们可以这么写(部分简化):
pick<T extends object, U extends keyof T>(object: T, ...props: Array<U>): Pick<T, U>;这里 T 声明约束为对象类型,而 U 声明约束为 keyof T。同时对应的,其返回值类型中使用了 Pick<T, U> 这一工具类型,它与 pick 函数的作用一致,对一个对象结构进行裁剪,我们会在后面内置工具类型一节讲到。
函数的泛型参数也会被内部的逻辑消费,如:
function handle<T>(payload: T): Promise<[T]> {
return new Promise<[T]>((res, rej) => {
res([payload]);
});
}对于箭头函数的泛型,其书写方式是这样的:
const handle = <T>(input: T): T => {}需要注意的是在 tsx 文件中泛型的尖括号可能会造成报错,编译器无法识别这是一个组件还是一个泛型,此时你可以让它长得更像泛型一些:
const handle = <T extends any>(input: T): T => {}函数的泛型是日常使用较多的一部分,更明显地体现了泛型在调用时被填充这一特性,而类型别名中,我们更多是手动传入泛型。这一差异的缘由其实就是它们的场景不同,我们通常使用类型别名来对已经确定的类型结构进行类型操作,比如将一组确定的类型放置在一起。而在函数这种场景中,我们并不能确定泛型在实际运行时会被什么样的类型填充。
需要注意的是,不要为了用泛型而用泛型,就像这样:
function handle<T>(arg: T): void {
console.log(arg);
};在这个函数中,泛型参数 T 没有被返回值消费,也没有被内部的逻辑消费,这种情况下即使随着调用填充了泛型参数,也是没有意义的。因此这里你就完全可以用 any 来进行类型标注。
Class 中的泛型
Class 中的泛型和函数中的泛型非常类似,只不过函数中泛型参数的消费方是参数和返回值类型,Class 中的泛型消费方则是属性、方法、乃至装饰器等。同时 Class 内的方法还可以再声明自己独有的泛型参数。我们直接来看完整的示例:
class Queue<TElementType> {
private _list: TElementType[];
constructor(initial: TElementType[]) {
this._list = initial;
}
// 入队一个队列泛型子类型的元素
enqueue<TType extends TElementType>(ele: TType): TElementType[] {
this._list.push(ele);
return this._list;
}
// 入队一个任意类型元素(无需为队列泛型子类型)
enqueueWithUnknownType<TType>(element: TType): (TElementType | TType)[] {
return [...this._list, element];
}
// 出队
dequeue(): TElementType[] {
this._list.shift();
return this._list;
}
}其中,enqueue 方法的入参类型 TType 被约束为队列类型的子类型,而 enqueueWithUnknownType 方法中的 TType 类型参数则不会受此约束,它会在其被调用时再对应地填充,同时也会在返回值类型中被使用。
内置方法中的泛型
TypeScript 中为非常多的内置对象都预留了泛型坑位,如 Promise 中
function p() {
return new Promise<boolean>((resolve, reject) => {
resolve(true);
});
}在你填充 Promise 的泛型以后,其内部的 resolve 方法也自动填充了泛型,而在 TypeScript 内部的 Promise 类型声明中同样是通过泛型实现:
interface PromiseConstructor {
resolve<T>(value: T | PromiseLike<T>): Promise<T>;
}
declare var Promise: PromiseConstructor;还有数组 Array<T> 当中,其泛型参数代表数组的元素类型,几乎贯穿所有的数组方法:
const arr: Array<number> = [1, 2, 3];
// 类型“string”的参数不能赋给类型“number”的参数。
arr.push('linbudu');
// 类型“string”的参数不能赋给类型“number”的参数。
arr.includes('linbudu');
// number | undefined
arr.find(() => false);
// 第一种 reduce
arr.reduce((prev, curr, idx, arr) => {
return prev;
}, 1);
// 第二种 reduce
// 报错:不能将 number 类型的值赋值给 never 类型
arr.reduce((prev, curr, idx, arr) => {
return [...prev, curr]
}, []);reduce 方法是相对特殊的一个,它的类型声明存在几种不同的重载:
- 当你不传入初始值时,泛型参数会从数组的元素类型中进行填充。
- 当你传入初始值时,如果初始值的类型与数组元素类型一致,则使用数组的元素类型进行填充。即这里第一个
reduce调用。 - 当你传入一个数组类型的初始值,比如这里的第二个
reduce调用,reduce的泛型参数会默认从这个初始值推导出的类型进行填充,如这里是never[]。
其中第三种情况也就意味着信息不足,无法推导出正确的类型,我们可以手动传入泛型参数来解决:
arr.reduce<number[]>((prev, curr, idx, arr) => {
return prev;
}, []);在 React 中,我们同样可以找到无处不在的泛型坑位:
const [state, setState] = useState<number[]>([]);
// 不传入默认值,则类型为 number[] | undefined
const [state, setState] = useState<number[]>();
// 体现在 ref.current 上
const ref = useRef<number>();
const context = createContext<ContextType>({});关于 React 中的更多泛型坑位以及 TypeScript 结合使用,我们会在后面的实战一节进行详细讲解。
类型兼容性判断的幕后
在 TypeScript 中,你可能遇见过以下这样“看起来不太对,但竟然能正常运行”的代码:
class Cat {
eat() { }
}
class Dog {
eat() { }
}
function feedCat(cat: Cat) { }
feedCat(new Dog())这里的 feedCat 函数明明需要的是一只猫,可为什么上传一只狗也可以呢?实际上,这就是 TypeScript 的类型系统特性:结构化类型系统,也是我们这一节要学习的概念。我们会了解结构化类型系统的比较方式,对比另一种类型系统(标称类型系统)的工作方式,以及在 TypeScript 中去模拟另一种类型系统。
结构化类型系统的概念非常基础但十分重要,它不仅能让你明确类型比较的核心原理,从根上理解条件类型等类型工具,也能够在日常开发中帮你解决许多常见的类型报错。
结构化类型系统
首先回到我们开头提出的问题,如果我们为 Cat 类新增一个独特的方法,这个时候的表现才是符合预期的,即我们只能用真实的 Cat 类来进行调用:
class Cat {
meow() { }
eat() { }
}
class Dog {
eat() { }
}
function feedCat(cat: Cat) { }
// 报错!
feedCat(new Dog())这是因为,TypeScript 比较两个类型并非通过类型的名称(即 feedCat 函数只能通过 Cat 类型调用),而是比较这两个类型上实际拥有的属性与方法。也就是说,这里实际上是比较 Cat 类型上的属性是否都存在于 Dog 类型上。
在我们最初的例子里,Cat 与 Dog 类型上的方法是一致的,所以它们虽然是两个名字不同的类型,但仍然被视为结构一致,这就是结构化类型系统的特性。你可能听过结构类型的别称鸭子类型(Duck Typing),这个名字来源于鸭子测试(Duck Test)。其核心理念是,如果你看到一只鸟走起来像鸭子,游泳像鸭子,叫得也像鸭子,那么这只鸟就是鸭子。
也就说,鸭子类型中两个类型的关系是通过对象中的属性方法来判断的。比如最开始的 Cat 类型和 Dog 类型被视为同一个类型,而为 Cat 类型添加独特的方法之后就不再能被视为一个类型。但如果为 Dog 类型添加一个独特方法呢?
class Cat {
eat() { }
}
class Dog {
bark() { }
eat() { }
}
function feedCat(cat: Cat) { }
feedCat(new Dog())这个时候为什么却没有类型报错了?这是因为,结构化类型系统认为 Dog 类型完全实现了 Cat 类型。至于额外的方法 bark,可以认为是 Dog 类型继承 Cat 类型后添加的新方法,即此时 Dog 类可以被认为是 Cat 类的子类。同样的,面向对象编程中的里氏替换原则也提到了鸭子测试:如果它看起来像鸭子,叫起来也像鸭子,但是却需要电池才能工作,那么你的抽象很可能出错了。
更进一步,在比较对象类型的属性时,同样会采用结构化类型系统进行判断。而对结构中的函数类型(即方法)进行比较时,同样存在类型的兼容性比较:
class Cat {
eat(): boolean {
return true
}
}
class Dog {
eat(): number {
return 599;
}
}
function feedCat(cat: Cat) { }
// 报错!
feedCat(new Dog())这就是结构化类型系统的核心理念,即基于类型结构进行判断类型兼容性。结构化类型系统在 C#、Python、Objective-C 等语言中都被广泛使用或支持。
严格来说,鸭子类型系统和结构化类型系统并不完全一致,结构化类型系统意味着基于完全的类型结构来判断类型兼容性,而鸭子类型则只基于运行时访问的部分来决定。也就是说,如果我们调用了走、游泳、叫这三个方法,那么传入的类型只需要存在这几个方法即可(而不需要类型结构完全一致)。但由于 TypeScript 本身并不是在运行时进行类型检查(也做不到),同时官方文档中同样认为这两个概念是一致的(One of TypeScript’s core principles is that type checking focuses on the shape that values have. This is sometimes called “duck typing” or “structural typing”.)。因此在这里,我们可以直接认为鸭子类型与结构化类型是同一概念。
除了基于类型结构进行兼容性判断的结构化类型系统以外,还有一种基于类型名进行兼容性判断的类型系统,标称类型系统。
标称类型系统
标称类型系统(Nominal Typing System)要求,两个可兼容的类型,其名称必须是完全一致的,比如以下代码:
type USD = number;
type CNY = number;
const CNYCount: CNY = 200;
const USDCount: USD = 200;
function addCNY(source: CNY, input: CNY) {
return source + input;
}
addCNY(CNYCount, USDCount)在结构化类型系统中,USD 与 CNY (分别代表美元单位与人民币单位)被认为是两个完全一致的类型,因此在 addCNY 函数中可以传入 USD 类型的变量。这就很离谱了,人民币与美元这两个单位实际的意义并不一致,怎么能进行相加?
在标称类型系统中,CNY 与 USD 被认为是两个完全不同的类型,因此能够避免这一情况发生。在《编程与类型系统》一书中提到,类型的重要意义之一是限制了数据的可用操作与实际意义,这一点在标称类型系统中的体现要更加明显。比如,上面我们可以通过类型的结构,来让结构化类型系统认为两个类型具有父子类型关系,而对于标称类型系统,父子类型关系只能通过显式的继承来实现,称为标称子类型(Nominal Subtyping)。
class Cat { }
// 实现一只短毛猫!
class ShorthairCat extends Cat { }C++、Java、Rust 等语言中都主要使用标称类型系统。那么,我们是否可以在 TypeScript 中模拟出标称类型系统?
在 TypeScript 中模拟标称类型系统
再看一遍这句话:类型的重要意义之一是限制了数据的可用操作与实际意义。这往往是通过类型附带的额外信息来实现的(类似于元数据),要在 TypeScript 中实现,其实我们也只需要为类型额外附加元数据即可,比如 CNY 与 USD,我们分别附加上它们的单位信息即可,但同时又需要保留原本的信息(即原本的 number 类型)。
我们可以通过交叉类型的方式来实现信息的附加:
export declare class TagProtector<T extends string> {
protected __tag__: T;
}
export type Nominal<T, U extends string> = T & TagProtector<U>;在这里我们使用 TagProtector 声明了一个具有 protected 属性的类,使用它来携带额外的信息,并和原本的类型合并到一起,就得到了 Nominal 工具类型。
有了 Nominal 这个工具类型,我们可以尝试来改进下上面的例子了:
export type CNY = Nominal<number, 'CNY'>;
export type USD = Nominal<number, 'USD'>;
const CNYCount = 100 as CNY;
const USDCount = 100 as USD;
function addCNY(source: CNY, input: CNY) {
return (source + input) as CNY;
}
addCNY(CNYCount, CNYCount);
// 报错了!
addCNY(CNYCount, USDCount);这一实现方式本质上只在类型层面做了数据的处理,在运行时无法进行进一步的限制。我们还可以从逻辑层面入手进一步确保安全性:
class CNY {
private __tag!: void;
constructor(public value: number) {}
}
class USD {
private __tag!: void;
constructor(public value: number) {}
}相应的,现在使用方式也要进行变化:
const CNYCount = new CNY(100);
const USDCount = new USD(100);
function addCNY(source: CNY, input: CNY) {
return (source.value + input.value);
}
addCNY(CNYCount, CNYCount);
// 报错了!
addCNY(CNYCount, USDCount);通过这种方式,我们可以在运行时添加更多的检查逻辑,同时在类型层面也得到了保障。
这两种方式的本质都是通过额外属性实现了类型信息的附加,从而使得结构化类型系统将结构一致的两个类型也判断为不可兼容。
在 type-fest 中也通过 Opaque Type 支持了类似的功能,其实现如下:
declare const tag: unique symbol;
declare type Tagged<Token> = {
readonly [tag]: Token;
};
export type Opaque<Type, Token = unknown> = Type & Tagged<Token>;总结一下,在 TypeScript 中我们可以通过类型或者逻辑的方式来模拟标称类型,这两种方式其实并没有非常明显的优劣之分,基于类型实现更加轻量,你的代码逻辑不会受到影响,但难以进行额外的逻辑检查工作。而使用逻辑实现稍显繁琐,但你能够进行更进一步或更细致的约束。
类型、类型系统与类型检查
对于类型、类型系统、类型检查,你可以认为它们是不同的概念。
- 类型:限制了数据的可用操作、意义、允许的值的集合,总的来说就是访问限制与赋值限制。在
TypeScript中即是原始类型、对象类型、函数类型、字面量类型等基础类型,以及类型别名、联合类型等经过类型编程后得到的类型。 - 类型系统:一组为变量、函数等结构分配、实施类型的规则,通过显式地指定或类型推导来分配类型。同时类型系统也定义了如何判断类型之间的兼容性:在
TypeScript中即是结构化类型系统。 - 类型检查:确保类型遵循类型系统下的类型兼容性,对于静态类型语言,在编译时进行,而对于动态语言,则在运行时进行。
TypeScript就是在编译时进行类型检查的。
一个需要注意的地方是,静态类型与动态类型指的是类型检查发生的时机,并不等于这门语言的类型能力。比如 JavaScript 实际上是动态类型语言,它的类型检查发生在运行时。
另外一个静态类型与动态类型的重要区别体现在变量赋值时,如在 TypeScript 中无法给一个声明为 number 的变量使用字符串赋值,因为这个变量在声明时的类型就已经确定了。而在 JavaScript 中则没有这样的限制,你可以随时切换一个变量的类型。
另外,在编程语言中还有强类型、弱类型的概念,它们体现在对变量类型检查的程度,如在 JavaScript 中可以实现 '1' - 1 这样神奇的运算(通过隐式转换),这其实就是弱类型语言的显著特点之一。
从 Top Type 到 Bottom Type
如果说类型系统是 TypeScript 中的重要基础知识,那么类型层级就是类型系统中的重要概念之一。对于没有类型语言经验学习的同学,说类型层级是最重要的基础概念也不为过。
类型层级一方面能帮助我们明确各种类型的层级与兼容性,而兼容性问题往往就是许多类型错误产生的原因。另一方面,类型层级也是我们后续学习条件类型必不可少的前置知识。我也建议你能同时学习这两篇内容,遇到不理解、不熟悉的地方可以多看几遍。
类型层级实际上指的是,TypeScript 中所有类型的兼容关系,从最上面一层的 any 类型,到最底层的 never 类型。那么,从上至下的类型兼容关系到底长什么样呢? 这一节,我们就从原始类型变量和字面量类型开始比较,分别向上、向下延伸,依次把这些类型串起来形成层级链,让你能够构建出 TypeScript 的整个类型体系。
判断类型兼容性的方式
在开始前,我们需要先了解一下如何直观地判断两个类型的兼容性。本节中我们主要使用条件类型来判断类型兼容性,类似这样:
type Result = 'linbudu' extends string ? 1 : 2;如果返回 1,则说明 'linbudu' 为 string 的子类型。否则,说明不成立。但注意,不成立并不意味着 string 就是 'linbudu' 的子类型了。还有一种备选的,通过赋值来进行兼容性检查的方式,其大致使用方式是这样的:
declare let source: string;
declare let anyType: any;
declare let neverType: never;
anyType = source;
// 不能将类型“string”分配给类型“never”。
neverType = source;对于变量 a = 变量 b,如果成立,意味着 <变量 b 的类型> extends <变量 a 的类型> 成立,即 b 类型是 a 类型的子类型,在这里即是 string extends never ,这明显是不成立的。
觉得不好理解?那可以试着这么想,我们有一个“狗”类型的变量,还有两个分别是“柯基”类型与“橘猫”类型的变量。
- 狗 = 柯基,意味着将柯基作为狗,这是没问题的。
- 狗 = 橘猫,很明显不对,程序对“狗”这个变量的使用,都建立在它是一个“狗”类型的基础上,你给个猫,让后面咋办?
这两种判断方式并没有明显的区别,只在使用场景上略有差异。在需要判断多个类型的层级时,条件类型更为直观,而如果只是两个类型之间的兼容性判断时,使用类型声明则更好理解一些,你可以依据自己的习惯来进行选择。
从原始类型开始
了解了类型兼容性判断的方式后,我们就可以开始探讨类型层级了。首先,我们从原始类型、对象类型(后文统称为基础类型)和它们对应的字面量类型开始。
type Result1 = "linbudu" extends string ? 1 : 2; // 1
type Result2 = 1 extends number ? 1 : 2; // 1
type Result3 = true extends boolean ? 1 : 2; // 1
type Result4 = { name: string } extends object ? 1 : 2; // 1
type Result5 = { name: 'linbudu' } extends object ? 1 : 2; // 1
type Result6 = [] extends object ? 1 : 2; // 1很明显,一个基础类型和它们对应的字面量类型必定存在父子类型关系。严格来说,object 出现在这里并不恰当,因为它实际上代表着所有非原始类型的类型,即数组、对象与函数类型,所以这里 Result6 成立的原因即是[]这个字面量类型也可以被认为是 object 的字面量类型。我们将结论简记为,字面量类型 < 对应的原始类型。
接下来,我们就从这个原始类型与字面量出发,向上、向下去探索类型层级。
向上探索,直到穹顶之上
联合类型
我们之前讲过,在联合类型中,只需要符合其中一个类型,我们就可以认为实现了这个联合类型,用条件类型表达是这样的:
type Result7 = 1 extends 1 | 2 | 3 ? 1 : 2; // 1
type Result8 = 'lin' extends 'lin' | 'bu' | 'du' ? 1 : 2; // 1
type Result9 = true extends true | false ? 1 : 2; // 1在这一层面上,并不需要联合类型的所有成员均为字面量类型,或者字面量类型来自于同一基础类型这样的前提,只需要这个类型存在于联合类型中。
对于原始类型,联合类型的比较其实也是一致的:
type Result10 = string extends string | false | number ? 1 : 2; // 1结论:字面量类型 < 包含此字面量类型的联合类型,原始类型 < 包含此原始类型的联合类型。
而如果一个联合类型由同一个基础类型的类型字面量组成,那这个时候情况又有点不一样了。既然你的所有类型成员都是字符串字面量类型,那你岂不就是我 string 类型的小弟?如果你的所有类型成员都是对象、数组字面量类型或函数类型,那你岂不就是我 object 类型的小弟?
type Result11 = 'lin' | 'bu' | 'budu' extends string ? 1 : 2; // 1
type Result12 = {} | (() => void) | [] extends object ? 1 : 2; // 1结论:同一基础类型的字面量联合类型 < 此基础类型。
合并一下结论,去掉比较特殊的情况,我们得到了这个最终结论:字面量类型 < 包含此字面量类型的联合类型(同一基础类型) < 对应的原始类型,即:
// 2
type Result13 = 'linbudu' extends 'linbudu' | '599'
? 'linbudu' | '599' extends string
? 2
: 1
: 0;对于这种嵌套的联合类型,我们这里直接观察最后一个条件语句的结果即可,因为如果所有条件语句都成立,那结果就是最后一个条件语句为真时的值。另外,由于联合类型实际上是一个比较特殊的存在,大部分类型都存在至少一个联合类型作为其父类型,因此在后面我们不会再体现联合类型。
现在,我们关注的类型变成了基础类型,即 string 与 object 这一类。
装箱类型
在「原始类型与对象类型」一节中,我们已经讲到了 JavaScript 中装箱对象 String 在 TypeScript 中的体现: String 类型,以及在原型链顶端傲视群雄的 Object 对象与 Object 类型。
很明显,string 类型会是 String 类型的子类型,String 类型会是 Object 类型的子类型,那中间还有吗?还真有,而且你不一定能猜到。我们直接看从 string 到 Object 的类型层级:
type Result14 = string extends String ? 1 : 2; // 1
type Result15 = String extends {} ? 1 : 2; // 1
type Result16 = {} extends object ? 1 : 2; // 1
type Result18 = object extends Object ? 1 : 2; // 1这里看着像是混进来一个很奇怪的东西,{} 不是 object 的字面量类型吗?为什么能在这里比较,并且 String 还是它的子类型?
这时请回忆我们在结构化类型系统中一节学习到的概念,假设我们把 String 看作一个普通的对象,上面存在一些方法,如:
interface String {
replace: // ...
replaceAll: // ...
startsWith: // ...
endsWith: // ...
includes: // ...
}这个时候,是不是能看做 String 继承了 {} 这个空对象,然后自己实现了这些方法?当然可以!在结构化类型系统的比较下,String 会被认为是 {} 的子类型。这里从 string < {} < object 看起来构建了一个类型链,但实际上 string extends object 并不成立:
type Tmp = string extends object ? 1 : 2; // 2由于结构化类型系统这一特性的存在,我们能得到一些看起来矛盾的结论:
type Result16 = {} extends object ? 1 : 2; // 1
type Result18 = object extends {} ? 1 : 2; // 1
type Result17 = object extends Object ? 1 : 2; // 1
type Result20 = Object extends object ? 1 : 2; // 1
type Result19 = Object extends {} ? 1 : 2; // 1
type Result21 = {} extends Object ? 1 : 2; // 116-18 和 19-21 这两对,为什么无论如何判断都成立?难道说明 {} 和 object 类型相等,也和 Object 类型一致?
当然不,这里的 {} extends 和 extends {} 实际上是两种完全不同的比较方式。{} extends object 和 {} extends Object 意味着,{} 是 object 和 Object 的字面量类型,是从类型信息的层面出发的,即字面量类型在基础类型之上提供了更详细的类型信息。object extends {} 和 Object extends {} 则是从结构化类型系统的比较出发的,即 {} 作为一个一无所有的空对象,几乎可以被视作是所有类型的基类,万物的起源。如果混淆了这两种类型比较的方式,就可能会得到 string extends object 这样的错误结论。
而 object extends Object 和 Object extends object 这两者的情况就要特殊一些,它们是因为“系统设定”的问题,Object 包含了所有除 Top Type 以外的类型(基础类型、函数类型等),object 包含了所有非原始类型的类型,即数组、对象与函数类型,这就导致了你中有我、我中有你的神奇现象。
在这里,我们暂时只关注从类型信息层面出发的部分,即结论为:原始类型 < 原始类型对应的装箱类型 < Object 类型。
现在,我们关注的类型为 Object 。
Top Type
再往上,我们就到达了类型层级的顶端(是不是很快),这里只有 any 和 unknown 这两兄弟。我们在 any、unknown 与 never 一节中已经了解,any 与 unknown 是系统中设定为 Top Type 的两个类型,它们无视一切因果律,是类型世界的规则产物。因此,Object 类型自然会是 any 与 unknown 类型的子类型。
type Result22 = Object extends any ? 1 : 2; // 1
type Result23 = Object extends unknown ? 1 : 2; // 1但如果我们把条件类型的两端对调一下呢?
type Result24 = any extends Object ? 1 : 2; // 1 | 2
type Result25 = unknown extends Object ? 1 : 2; // 2你会发现,any 竟然调过来,值竟然变成了 1 | 2?我们再多试几个看看:
type Result26 = any extends 'linbudu' ? 1 : 2; // 1 | 2
type Result27 = any extends string ? 1 : 2; // 1 | 2
type Result28 = any extends {} ? 1 : 2; // 1 | 2
type Result29 = any extends never ? 1 : 2; // 1 | 2是不是感觉匪夷所思?实际上,还是因为“系统设定”的原因。any 代表了任何可能的类型,当我们使用 any extends 时,它包含了“让条件成立的一部分”,以及“让条件不成立的一部分”。而从实现上说,在 TypeScript 内部代码的条件类型处理中,如果接受判断的是 any,那么会直接返回条件类型结果组成的联合类型。
因此 any extends string 并不能简单地认为等价于以下条件类型:
type Result30 = ("I'm string!" | {}) extends string ? 1 : 2; // 2这种情况下,由于联合类型的成员并非均是字符串字面量类型,条件显然不成立。
在前面学习 any 类型时,你可能也感受到了奇怪之处,在赋值给其他类型时,any 来者不拒,而 unknown 则只允许赋值给 unknown 类型和 any 类型,这也是由于“系统设定”的原因,即 any 可以表达为任何类型。你需要我赋值给这个变量?那我现在就是这个变量的子类型了,我是不是很乖巧?
另外,any 类型和 unknown 类型的比较也是互相成立的:
type Result31 = any extends unknown ? 1 : 2; // 1
type Result32 = unknown extends any ? 1 : 2; // 1虽然还是存在系统设定的部分,但我们仍然只关注类型信息层面的层级,即结论为:Object < any / unknown。而到这里,我们已经触及了类型世界的最高一层,接下来我们再回到字面量类型,只不过这一次我们要向下探索了。
向下探索,直到万物虚无
向下地探索其实就简单多了,首先我们能确认一定有个 never 类型,因为它代表了“虚无”的类型,一个根本不存在的类型。对于这样的类型,它会是任何类型的子类型,当然也包括字面量类型:
type Result33 = never extends 'linbudu' ? 1 : 2; // 1但你可能又想到了一些特别的部分,比如 null、undefined、void。
type Result34 = undefined extends 'linbudu' ? 1 : 2; // 2
type Result35 = null extends 'linbudu' ? 1 : 2; // 2
type Result36 = void extends 'linbudu' ? 1 : 2; // 2上面三种情况当然不应该成立。别忘了在 TypeScript 中,void、undefined、null 都是切实存在、有实际意义的类型,它们和 string、number、object 并没有什么本质区别。
因此,这里我们得到的结论是,never < 字面量类型。这就是类型世界的最底层,有点像我的世界那样,当你挖穿地面后,出现的是一片茫茫的空白与虚无。
那现在,我们可以开始组合整个类型层级了。
类型层级链
结合我们上面得到的结论,可以书写出这样一条类型层级链:
type TypeChain = never extends 'linbudu'
? 'linbudu' extends 'linbudu' | '599'
? 'linbudu' | '599' extends string
? string extends String
? String extends Object
? Object extends any
? any extends unknown
? unknown extends any
? 8
: 7
: 6
: 5
: 4
: 3
: 2
: 1
: 0其返回的结果为 8 ,也就意味着所有条件均成立。当然,结合上面的结构化类型系统与类型系统设定,我们还可以构造出一条更长的类型层级链:
type VerboseTypeChain = never extends 'linbudu'
? 'linbudu' extends 'linbudu' | 'budulin'
? 'linbudu' | 'budulin' extends string
? string extends {}
? string extends String
? String extends {}
? {} extends object
? object extends {}
? {} extends Object
? Object extends {}
? object extends Object
? Object extends object
? Object extends any
? Object extends unknown
? any extends unknown
? unknown extends any
? 8
: 7
: 6
: 5
: 4
: 3
: 2
: 1
: 0
: -1
: -2
: -3
: -4
: -5
: -6
: -7
: -8结果仍然为 8 。
其他比较场景
除了我们上面提到的类型比较,其实还存在着一些比较情况,我们稍作补充。
对于基类和派生类,通常情况下派生类会完全保留基类的结构,而只是自己新增新的属性与方法。在结构化类型的比较下,其类型自然会存在子类型关系。更不用说派生类本身就是
extends基类得到的。联合类型的判断,前面我们只是判断联合类型的单个成员,那如果是多个成员呢?
tstype Result36 = 1 | 2 | 3 extends 1 | 2 | 3 | 4 ? 1 : 2; // 1 type Result37 = 2 | 4 extends 1 | 2 | 3 | 4 ? 1 : 2; // 1 type Result38 = 1 | 2 | 5 extends 1 | 2 | 3 | 4 ? 1 : 2; // 2 type Result39 = 1 | 5 extends 1 | 2 | 3 | 4 ? 1 : 2; // 2实际上,对于联合类型地类型层级比较,我们只需要比较一个联合类型是否可被视为另一个联合类型的子集,即这个联合类型中所有成员在另一个联合类型中都能找到。
数组和元组
数组和元组是一个比较特殊的部分,我们直接来看例子:
tstype Result40 = [number, number] extends number[] ? 1 : 2; // 1 type Result41 = [number, string] extends number[] ? 1 : 2; // 2 type Result42 = [number, string] extends (number | string)[] ? 1 : 2; // 1 type Result43 = [] extends number[] ? 1 : 2; // 1 type Result44 = [] extends unknown[] ? 1 : 2; // 1 type Result45 = number[] extends (number | string)[] ? 1 : 2; // 1 type Result46 = any[] extends number[] ? 1 : 2; // 1 type Result47 = unknown[] extends number[] ? 1 : 2; // 2 type Result48 = never[] extends number[] ? 1 : 2; // 1我们一个个来讲解:
- 40,这个元组类型实际上能确定其内部成员全部为
number类型,因此是number[]的子类型。而 41 中混入了别的类型元素,因此认为不成立。 - 42混入了别的类型,但其判断条件为
(number | string)[],即其成员需要为number或string类型。 - 43的成员是未确定的,等价于
never[] extends number[],44 同理。 - 45类似于41,即可能存在的元素类型是符合要求的。
- 46、47,还记得身化万千的
any类型和小心谨慎的unknown类型嘛? - 48,类似于 43、44,由于
never类型本就位于最下方,这里显然成立。只不过never[]类型的数组也就无法再填充值了。
- 40,这个元组类型实际上能确定其内部成员全部为
基础的类型层级可以用以下这张图表示:

条件类型与 infer
条件类型基础
条件类型的语法类似于我们平时常用的三元表达式,它的基本语法如下(伪代码):
ValueA === ValueB ? Result1 : Result2;
TypeA extends TypeB ? Result1 : Result2;但需要注意的是,条件类型中使用 extends 判断类型的兼容性,而非判断类型的全等性。这是因为在类型层面中,对于能够进行赋值操作的两个变量,我们并不需要它们的类型完全相等,只需要具有兼容性,而两个完全相同的类型,其 extends 自然也是成立的。
条件类型绝大部分场景下会和泛型一起使用,我们知道,泛型参数的实际类型会在实际调用时才被填充(类型别名中显式传入,或者函数中隐式提取),而条件类型在这一基础上,可以基于填充后的泛型参数做进一步的类型操作,比如这个例子:
type LiteralType<T> = T extends string ? "string" : "other";
type Res1 = LiteralType<"linbudu">; // "string"
type Res2 = LiteralType<599>; // "other"同三元表达式可以嵌套一样,条件类型中也常见多层嵌套,如:
export type LiteralType<T> = T extends string
? "string"
: T extends number
? "number"
: T extends boolean
? "boolean"
: T extends null
? "null"
: T extends undefined
? "undefined"
: never;
type Res1 = LiteralType<"linbudu">; // "string"
type Res2 = LiteralType<599>; // "number"
type Res3 = LiteralType<true>; // "boolean"而在函数中,条件类型与泛型的搭配同样很常见。考考你,以下这个函数,我们应该如何标注它的返回值类型?
function universalAdd<T extends number | bigint | string>(x: T, y: T) {
return x + (y as any);
}当我们调用这个函数时,由于两个参数都引用了泛型参数 T ,因此泛型会被填充为一个联合类型:
universalAdd(599, 1); // T 填充为 599 | 1
universalAdd("linbudu", "599"); // T 填充为 linbudu | 599那么此时的返回值类型就需要从这个字面量联合类型中推导回其原本的基础类型。在类型层级一节中,我们知道同一基础类型的字面量联合类型,其可以被认为是此基础类型的子类型,即 599 | 1 是 number 的子类型。
因此,我们可以使用嵌套的条件类型来进行字面量类型到基础类型地提取:
function universalAdd<T extends number | bigint | string>(
x: T,
y: T
): LiteralToPrimitive<T> {
return x + (y as any);
}
export type LiteralToPrimitive<T> = T extends number
? number
: T extends bigint
? bigint
: T extends string
? string
: never;
universalAdd("linbudu", "599"); // string
universalAdd(599, 1); // number
universalAdd(10n, 10n); // bigint条件类型还可以用来对更复杂的类型进行比较,比如函数类型:
type Func = (...args: any[]) => any;
type FunctionConditionType<T extends Func> = T extends (
...args: any[]
) => string
? 'A string return func!'
: 'A non-string return func!';
// "A string return func!"
type StringResult = FunctionConditionType<() => string>;
// 'A non-string return func!';
type NonStringResult1 = FunctionConditionType<() => boolean>;
// 'A non-string return func!';
type NonStringResult2 = FunctionConditionType<() => number>;在这里,我们的条件类型用于判断两个函数类型是否具有兼容性,而条件中并不限制参数类型,仅比较二者的返回值类型。
与此同时,存在泛型约束和条件类型两个 extends 可能会让你感到疑惑,但它们产生作用的时机完全不同,泛型约束要求你传入符合结构的类型参数,相当于参数校验。而条件类型使用类型参数进行条件判断(就像 if else),相当于实际内部逻辑。
我们上面讲到的这些条件类型,本质上就是在泛型基于调用填充类型信息的基础上,新增了基于类型信息的条件判断。看起来很不错,但你可能也发现了一个无法满足的场景:提取传入的类型信息。
infer 关键字
在上面的例子中,假如我们不再比较填充的函数类型是否是 (...args: any[]) => string 的子类型,而是要拿到其返回值类型呢?或者说,我们希望拿到填充的类型信息的一部分,而不是只是用它来做条件呢?
TypeScript 中支持通过 infer 关键字来在条件类型中提取类型的某一部分信息,比如上面我们要提取函数返回值类型的话,可以这么放:
type FunctionReturnType<T extends Func> = T extends (
...args: any[]
) => infer R
? R
: never;看起来是新朋友,其实还是老伙计。上面的代码其实表达了,当传入的类型参数满足 T extends (...args: any[] ) => infer R 这样一个结构(不用管 infer R,当它是 any 就行),返回 infer R 位置的值,即 R。否则,返回 never。
infer,意为推断,如 infer R 中 R 就表示 待推断的类型。infer 只能在条件类型中使用,因为我们实际上仍然需要类型结构是一致的,比如上例中类型信息需要是一个函数类型结构,我们才能提取出它的返回值类型。如果连函数类型都不是,那我只会给你一个 never 。
这里的类型结构当然并不局限于函数类型结构,还可以是数组:
type Swap<T extends any[]> = T extends [infer A, infer B] ? [B, A] : T;
type SwapResult1 = Swap<[1, 2]>; // 符合元组结构,首尾元素替换[2, 1]
type SwapResult2 = Swap<[1, 2, 3]>; // 不符合结构,没有发生替换,仍是 [1, 2, 3]由于我们声明的结构是一个仅有两个元素的元组,因此三个元素的元组就被认为是不符合类型结构了。但我们可以使用 rest 操作符来处理任意长度的情况:
// 提取首尾两个
type ExtractStartAndEnd<T extends any[]> = T extends [
infer Start,
...any[],
infer End
]
? [Start, End]
: T;
// 调换首尾两个
type SwapStartAndEnd<T extends any[]> = T extends [
infer Start,
...infer Left,
infer End
]
? [End, ...Left, Start]
: T;
// 调换开头两个
type SwapFirstTwo<T extends any[]> = T extends [
infer Start1,
infer Start2,
...infer Left
]
? [Start2, Start1, ...Left]
: T;是的,infer 甚至可以和 rest 操作符一样同时提取一组不定长的类型,而 ...any[] 的用法是否也让你直呼神奇?上面的输入输出仍然都是数组,而实际上我们完全可以进行结构层面的转换。比如从数组到联合类型:
type ArrayItemType<T> = T extends Array<infer ElementType> ? ElementType : never;
type ArrayItemTypeResult1 = ArrayItemType<[]>; // never
type ArrayItemTypeResult2 = ArrayItemType<string[]>; // string
type ArrayItemTypeResult3 = ArrayItemType<[string, number]>; // string | number原理即是这里的 [string, number] 实际上等价于 (string | number)[]。
除了数组,infer 结构也可以是接口:
// 提取对象的属性类型
type PropType<T, K extends keyof T> = T extends { [Key in K]: infer R }
? R
: never;
type PropTypeResult1 = PropType<{ name: string }, 'name'>; // string
type PropTypeResult2 = PropType<{ name: string; age: number }, 'name' | 'age'>; // string | number
// 反转键名与键值
type ReverseKeyValue<T extends Record<string, unknown>> = T extends Record<infer K, infer V> ? Record<V & string, K> : never
type ReverseKeyValueResult1 = ReverseKeyValue<{ "key": "value" }>; // { "value": "key" }在这里,为了体现 infer 作为类型工具的属性,我们结合了索引类型与映射类型,以及使用 & string 来确保属性名为 string 类型的小技巧。
为什么需要这个小技巧,如果不使用又会有什么问题呢?
// 类型“V”不满足约束“string | number | symbol”。
type ReverseKeyValue<T extends Record<string, string>> = T extends Record<
infer K,
infer V
>
? Record<V, K>
: never;明明约束已经声明了 V 的类型是 string,为什么还是报错了?
这是因为,泛型参数 V 的来源是从键值类型推导出来的,TypeScript 中这样对键值类型进行 infer 推导,将导致类型信息丢失,而不满足索引签名类型只允许 string | number | symbol 的要求。
还记得映射类型的判断条件吗?需要同时满足其两端的类型,我们使用 V & string 这一形式,就确保了最终符合条件的类型参数 V 一定会满足 string | never 这个类型,因此可以被视为合法的索引签名类型。
infer 结构还可以是 Promise 结构!
type PromiseValue<T> = T extends Promise<infer V> ? V : T;
type PromiseValueResult1 = PromiseValue<Promise<number>>; // number
type PromiseValueResult2 = PromiseValue<number>; // number,但并没有发生提取就像条件类型可以嵌套一样,infer 关键字也经常被使用在嵌套的场景中,包括对类型结构深层信息地提取,以及对提取到类型信息的筛选等。比如上面的 PromiseValue,如果传入了一个嵌套的 Promise 类型就失效了:
type PromiseValueResult3 = PromiseValue<Promise<Promise<boolean>>>; // Promise<boolean>,只提取了一层这种时候我们就需要进行嵌套地提取了:
type PromiseValue<T> = T extends Promise<infer V>
? V extends Promise<infer N>
? N
: V
: T;当然,在这时应该使用递归来处理任意嵌套深度:
type PromiseValue<T> = T extends Promise<infer V> ? PromiseValue<V> : T;条件类型在泛型的基础上支持了基于类型信息的动态条件判断,但无法直接消费填充类型信息,而 infer 关键字则为它补上了这一部分的能力,让我们可以进行更多奇妙的类型操作。TypeScript 内置的工具类型中还有一些基于 infer 关键字的应用,我们会在内置工具类型讲解一章中了解它们的具体实现。而我们上面了解的 rest infer(...infer Left),结合其他类型工具、递归 infer 等,都是日常比较常用的操作,这些例子应当能让你再一次意识到“类型编程”的真谛。
分布式条件类型
分布式条件类型听起来真的很高级,但这里和分布式和分布式服务并不是一回事。分布式条件类型(Distributive Conditional Type),也称条件类型的分布式特性,只不过是条件类型在满足一定情况下会执行的逻辑而已。我们来看一个例子:
type Condition<T> = T extends 1 | 2 | 3 ? T : never;
// 1 | 2 | 3
type Res1 = Condition<1 | 2 | 3 | 4 | 5>;
// never
type Res2 = 1 | 2 | 3 | 4 | 5 extends 1 | 2 | 3 ? 1 | 2 | 3 | 4 | 5 : never;这个例子可能让你感觉充满了疑惑,某些地方似乎和我们学习的知识并不一样?先不说这两个理论上应该执行结果一致的类型别名,为什么在 Res1 中诡异地返回了一个联合类型?
仔细观察这两个类型别名的差异你会发现,唯一的差异就是在 Res1 中,进行判断的联合类型被作为泛型参数传入给另一个独立的类型别名,而 Res2 中直接对这两者进行判断。
记住第一个差异:是否通过泛型参数传入。我们再看一个例子:
type Naked<T> = T extends boolean ? "Y" : "N";
type Wrapped<T> = [T] extends [boolean] ? "Y" : "N";
// "N" | "Y"
type Res3 = Naked<number | boolean>;
// "N"
type Res4 = Wrapped<number | boolean>;现在我们都是通过泛型参数传入了,但诡异的事情又发生了,为什么第一个还是个联合类型?第二个倒是好理解一些,元组的成员有可能是数字类型,显然不兼容于 [boolean]。再仔细观察这两个例子你会发现,它们唯一的差异是条件类型中的泛型参数是否被数组包裹了。
同时,你会发现在 Res3 的判断中,其联合类型的两个分支,恰好对应于分别使用 number 和 boolean 去作为条件类型判断时的结果。
把上面的线索理一下,其实我们就大致得到了条件类型分布式起作用的条件。首先,你的类型参数需要是一个联合类型 。其次,类型参数需要通过泛型参数的方式传入,而不能直接进行条件类型判断(如 Res2 中)。最后,条件类型中的泛型参数不能被包裹。
而条件类型分布式特性会产生的效果也很明显了,即将这个联合类型拆开来,每个分支分别进行一次条件类型判断,再将最后的结果合并起来(如 Naked 中)。如果再严谨一些,其实我们就得到了官方的解释:
对于属于裸类型参数的检查类型,条件类型会在实例化时期自动分发到联合类型上。(Conditional types in which the checked type is a naked type parameter are called distributive conditional types. Distributive conditional types are automatically distributed over union types during instantiation.)
这里的自动分发,我们可以这么理解:
type Naked<T> = T extends boolean ? "Y" : "N";
// (number extends boolean ? "Y" : "N") | (boolean extends boolean ? "Y" : "N")
// "N" | "Y"
type Res3 = Naked<number | boolean>;写成伪代码其实就是这样的:
const Res3 = [];
for(const input of [number, boolean]){
if(input extends boolean){
Res3.push("Y");
} else {
Res.push("N");
}
}而这里的裸类型参数,其实指的就是泛型参数是否完全裸露,我们上面使用数组包裹泛型参数只是其中一种方式,比如还可以这么做:
export type NoDistribute<T> = T & {};
type Wrapped<T> = NoDistribute<T> extends boolean ? "Y" : "N";
type Res1 = Wrapped<number | boolean>; // "N"
type Res2 = Wrapped<true | false>; // "Y"
type Res3 = Wrapped<true | false | 599>; // "N"需要注意的是,我们并不是只会通过裸露泛型参数,来确保分布式特性能够发生。在某些情况下,我们也会需要包裹泛型参数来禁用掉分布式特性。最常见的场景也许还是联合类型的判断,即我们不希望进行联合类型成员的分布判断,而是希望直接判断这两个联合类型的兼容性判断,就像在最初的 Res2 中那样:
type CompareUnion<T, U> = [T] extends [U] ? true : false;
type CompareRes1 = CompareUnion<1 | 2, 1 | 2 | 3>; // true
type CompareRes2 = CompareUnion<1 | 2, 1>; // false通过将参数与条件都包裹起来的方式,我们对联合类型的比较就变成了数组成员类型的比较,在此时就会严格遵守类型层级一文中联合类型的类型判断了(子集为其子类型)。
另外一种情况则是,当我们想判断一个类型是否为 never 时,也可以通过类似的手段:
type IsNever<T> = [T] extends [never] ? true : false;
type IsNeverRes1 = IsNever<never>; // true
type IsNeverRes2 = IsNever<"linbudu">; // false这里的原因其实并不是因为分布式条件类型。我们此前在类型层级中了解过,当条件类型的判断参数为 any,会直接返回条件类型两个结果的联合类型。而在这里其实类似,当通过泛型传入的参数为 never,则会直接返回 never。
需要注意的是这里的 never 与 any 的情况并不完全相同,any 在直接作为判断参数时、作为泛型参数时都会产生这一效果:
// 直接使用,返回联合类型
type Tmp1 = any extends string ? 1 : 2; // 1 | 2
type Tmp2<T> = T extends string ? 1 : 2;
// 通过泛型参数传入,同样返回联合类型
type Tmp2Res = Tmp2<any>; // 1 | 2
// 如果判断条件是 any,那么仍然会进行判断
type Special1 = any extends any ? 1 : 2; // 1
type Special2<T> = T extends any ? 1 : 2;
type Special2Res = Special2<any>; // 1而 never 仅在作为泛型参数时才会产生:
// 直接使用,仍然会进行判断
type Tmp3 = never extends string ? 1 : 2; // 1
type Tmp4<T> = T extends string ? 1 : 2;
// 通过泛型参数传入,会跳过判断
type Tmp4Res = Tmp4<never>; // never
// 如果判断条件是 never,还是仅在作为泛型参数时才跳过判断
type Special3 = never extends never ? 1 : 2; // 1
type Special4<T> = T extends never ? 1 : 2;
type Special4Res = Special4<never>; // never这里的 any、never 两种情况都不会实际地执行条件类型,而在这里我们通过包裹的方式让它不再是一个孤零零的 never,也就能够去执行判断了。
之所以分布式条件类型要这么设计,我个人理解主要是为了处理联合类型这种情况。就像我们到现在为止的伪代码都一直使用数组来表达联合类型一样,在类型世界中联合类型就像是一个集合一样。通过使用分布式条件类型,我们能轻易地进行集合之间的运算,比如交集:
type Intersection<A, B> = A extends B ? A : never;
type IntersectionRes = Intersection<1 | 2 | 3, 2 | 3 | 4>; // 2 | 3进一步的,当联合类型的组成是一个对象的属性名(keyof IObject),此时对这样的两个类型集合进行处理,得到属性名的交集,那我们就可以在此基础上获得两个对象类型结构的交集。除此以外,还有许多相对复杂的场景可以降维到类型集合,即联合类型的层面,然后我们就可以愉快地使用分布式条件类型进行各种处理了。关于类型层面的集合运算、对象结构集合运算,我们都会在小册的后续章节有详细的讲解。
IsAny 与 IsUnknown
上面我们通过比较 hack 的手段得到了 IsNever,那你一定会想是否能实现 IsAny 与 IsUnknown ?当然可以,只不过它们的实现稍微复杂一些,并且并不完全依赖分布式条件类型。
首先是 IsAny,上面已经提到我们并不能通过 any extends Type 这样的形式来判断一个类型是否是 any 。而是要利用 any 的另一个特性:身化万千:
type IsAny<T> = 0 extends 1 & T ? true : false;0 extends 1 必然是不成立的,而交叉类型 1 & T 也非常奇怪,它意味着同时符合字面量类型 1 和另一个类型 T 。在学习交叉类型时我们已经了解,对于 1 这样的字面量类型,只有传入其本身、对应的原始类型、包含其本身的联合类型,才能得到一个有意义的值,并且这个值一定只可能是它本身:
type Tmp1 = 1 & (0 | 1); // 1
type Tmp2 = 1 & number; // 1
type Tmp3 = 1 & 1; // 1这是因为交叉类型就像短板效应一样,其最终计算的类型是由最短的那根木板,也就是最精确的那个类型决定的。这样看,无论如何 0 extends 1 都不会成立。
但作为代表任意类型的 any ,它的存在就像是开天辟地的基本规则一样,如果交叉类型的其中一个成员是 any,那短板效应就失效了,此时最终类型必然是 any 。
type Tmp4 = 1 & any; // any而对于 unknown 并不能享受到这个待遇,因为它并不是“身化万千”的:
type Tmp5 = 1 & unknown; // 1因此,我们并不能用这个方式来写 IsUnknown。其实现过程要更复杂一些,我们需要过滤掉其他全部的类型来只剩下 unknown 。这里直接看实现:
type IsUnknown<T> = IsNever<T> extends false
? T extends unknown
? unknown extends T
? IsAny<T> extends false
? true
: false
: false
: false
: false;首先过滤掉 never 类型,然后对于 T extends unknown 和 unknown extends T,只有 any 和 unknown 类型能够同时符合(还记得我们在类型层级一节进行的尝试吗?),如果再过滤掉 any,那肯定就只剩下 unknown 类型啦。
这里的 IsUnknown 类型其实可以使用更简单的方式实现。利用 unknown extends T 时仅有 T 为 any 或 unknown 时成立这一点,我们可以直接将类型收窄到 any 与 unknown,然后在去掉 any 类型时,我们仍然可以利用上面的身化万千特性:
type IsUnknown<T> = unknown extends T
? IsAny<T> extends true
? false
: true
: false;内置工具类型基础
在很多时候,工具类型其实都被妖魔化了。它仿佛是武林中人人追捧的武功秘籍,修炼难度极其苛刻,掌握它就能立刻类型编程功力大涨,成为武林盟主傲世群雄。然而,这是非常错误的想法。
首先,工具类型学起来不难,它的概念也不复杂。很多同学觉得难,是因为还没完全熟悉所有类型工具,对类型系统还懵懵懂懂的情况下,就直接一头扎进各种复杂的类型编程源码中去。其实只要我们熟悉了类型工具的使用,了解类型系统的概念,再结合小册中对类型编程 4 大范式进行的分类解析,再复杂的类型编程也会被你所掌握的。
其次,工具类型和类型编程并不完全等价。虽然它是类型编程最常见的一种表现形式,但不能完全代表类型编程水平,如很多框架代码中,类型编程的复杂度也体现在函数的重载与泛型约束方面。但通过工具类型,我们能够更好地理解类型编程的本质。
工具类型的分类
内置的工具类型按照类型操作的不同,其实也可以大致划分为这么几类:
- 对属性的修饰,包括对象属性和数组元素的可选/必选、只读/可写。我们将这一类统称为属性修饰工具类型。
- 对既有类型的裁剪、拼接、转换等,比如使用对一个对象类型裁剪得到一个新的对象类型,将联合类型结构转换到交叉类型结构。我们将这一类统称为结构工具类型。
- 对集合(即联合类型)的处理,即交集、并集、差集、补集。我们将这一类统称为集合工具类型。
- 基于 infer 的模式匹配,即对一个既有类型特定位置类型的提取,比如提取函数类型签名中的返回值类型。我们将其统称为模式匹配工具类型。
- 模板字符串专属的工具类型,比如神奇地将一个对象类型中的所有属性名转换为大驼峰的形式。这一类当然就统称为模板字符串工具类型。
属性修饰工具类型
这一部分的工具类型主要使用属性修饰、映射类型与索引类型相关(索引类型签名、索引类型访问、索引类型查询均有使用,因此这里直接用索引类型指代)。
在内置工具类型中,访问性修饰工具类型包括以下三位:
type Partial<T> = {
[P in keyof T]?: T[P];
};
type Required<T> = {
[P in keyof T]-?: T[P];
};
type Readonly<T> = {
readonly [P in keyof T]: T[P];
};其中,Partial 与 Required 可以认为是一对工具类型,它们的功能是相反的,而在实现上,它们的唯一差异是在索引类型签名处的可选修饰符,Partial 是 ?,即标记属性为可选,而 Required 则是 -?,相当于在原本属性上如果有 ? 这个标记,则移除它。
如果你觉得不好记,其实 Partial 也可以使用 +? 来显式的表示添加可选标记:
type Partial<T> = {
[P in keyof T]+?: T[P];
};需要注意的是,可选标记不等于修改此属性类型为 原类型 | undefined ,如以下的接口结构:
interface Foo {
optional: string | undefined;
required: string;
}如果你声明一个对象去实现这个接口,它仍然会要求你提供 optional 属性
interface Foo {
optional: string | undefined;
required: string;
}
// 类型 "{ required: string; }" 中缺少属性 "optional",但类型 "Foo" 中需要该属性。
const foo1: Foo = {
required: '1',
};
const foo2: Foo = {
required: '1',
optional: undefined
};这是因为对于结构声明来说,一个属性是否必须提供仅取决于其是否携带可选标记。即使你使用 never 也无法标记这个属性为可选:
interface Foo {
optional: never;
required: string;
}
const foo: Foo = {
required: '1',
// 不能将类型“string”分配给类型“never”。
optional: '',
};反而你会惊喜地发现你没法为这个属性声明值了,毕竟除本身以外没有类型可以赋值给 never 类型。
而类似 +?,Readonly 中也可以使用 +readonly:
type Readonly<T> = {
+readonly [P in keyof T]: T[P];
};虽然 TypeScript 中并没有提供它的另一半,但参考 Required 其实我们很容易想到这么实现一个工具类型 Mutable,来将属性中的 readonly 修饰移除:
type Mutable<T> = {
-readonly [P in keyof T]: T[P];
};思考
现在我们了解了 Partial、Readonly 这一类属性修饰的工具类型,不妨想想它们是否能满足我们的需要?假设场景逐渐开始变得复杂,比如以下这些情况:
- 现在的属性修饰是浅层的,如果我想将嵌套在里面的对象类型也进行修饰,需要怎么改进?
- 现在的属性修饰是全量的,如果我只想修饰部分属性呢?这里的部分属性,可能是基于传入已知的键名来确定(比如属性a、b),也可能是基于属性类型来确定(比如所有函数类型的值)?
结构工具类型
这一部分的工具类型主要使用条件类型以及映射类型、索引类型。
结构工具类型其实又可以分为两类,结构声明和结构处理。
结构声明工具类型即快速声明一个结构,比如内置类型中的 Record:
type Record<K extends keyof any, T> = {
[P in K]: T;
};其中,K extends keyof any 即为键的类型,这里使用 extends keyof any 标明,传入的 可以是单个类型,也可以是联合类型,而 T 即为属性的类型。
// 键名均为字符串,键值类型未知
type Record1 = Record<string, unknown>;
// 键名均为字符串,键值类型任意
type Record2 = Record<string, any>;
// 键名为字符串或数字,键值类型任意
type Record3 = Record<string | number, any>;其中,Record<string, unknown> 和 Record<string, any> 是日常使用较多的形式,通常我们使用这两者来代替 object 。
在一些工具类库源码中其实还存在类似的结构声明工具类型,如:
type Dictionary<T> = {
[index: string]: T;
};
type NumericDictionary<T> = {
[index: number]: T;
};Dictionary(字典) 结构只需要一个作为属性类型的泛型参数即可。
而对于结构处理工具类型,在 TypeScript 中主要是 Pick、Omit 两位选手:
type Pick<T, K extends keyof T> = {
[P in K]: T[P];
};
type Omit<T, K extends keyof any> = Pick<T, Exclude<keyof T, K>>;首先来看 Pick,它接受两个泛型参数,T 即是我们会进行结构处理的原类型(一般是对象类型),而 K 则被约束为 T 类型的键名联合类型。由于泛型约束是立即填充推导的,即你为第一个泛型参数传入 Foo 类型以后,K 的约束条件会立刻被填充,因此在你输入 K 时会获得代码提示:
interface Foo {
name: string;
age: number;
job: JobUnionType;
}
type PickedFoo = Pick<Foo, "name" | "age">然后 Pick 会将传入的联合类型作为需要保留的属性,使用这一联合类型配合映射类型,即上面的例子等价于:
type Pick<T> = {
[P in "name" | "age"]: T[P];
};联合类型的成员会被依次映射,并通过索引类型访问来获取到它们原本的类型。
而对于 Omit 类型,看名字其实能 get 到它就是 Pick 的反向实现:Pick 是保留这些传入的键,比如从一个庞大的结构中选择少数字段保留,需要的是这些少数字段,而 Omit 则是移除这些传入的键,也就是从一个庞大的结构中剔除少数字段,需要的是剩余的多数部分。
但它的实现看起来有些奇怪:
type Omit<T, K extends keyof any> = Pick<T, Exclude<keyof T, K>>;首先我们发现,Omit 是基于 Pick 实现的,这也是 TypeScript 中成对工具类型的另一种实现方式。上面的 Partial 与 Required 使用类似的结构,在关键位置使用一个相反操作来实现反向,而这里的 Omit 类型则是基于 Pick 类型实现,也就是反向工具类型基于正向工具类型实现。
首先接受的泛型参数类似,也是一个类型与联合类型(要剔除的属性),但是在将这个联合类型传入给 Pick 时多了一个 Exclude,这一工具类型属于工具类型,我们可以暂时理解为 Exclude<A, B> 的结果就是联合类型 A 中不存在于 B 中的部分:
type Tmp1 = Exclude<1, 2>; // 1
type Tmp2 = Exclude<1 | 2, 2>; // 1
type Tmp3 = Exclude<1 | 2 | 3, 2 | 3>; // 1
type Tmp4 = Exclude<1 | 2 | 3, 2 | 4>; // 1 | 3因此,在这里 Exclude<keyof T, K> 其实就是 T 的键名联合类型中剔除了 K 的部分,将其作为 Pick 的键名,就实现了剔除一部分类型的效果。
思考
Pick和Omit是基于键名的,如果我们需要基于键值类型呢?比如仅对函数类型的属性?- 除了将一个对象结构拆分为多个子结构外,对这些子结构的互斥处理也是结构工具类型需要解决的问题之一。互斥处理指的是,假设你的对象存在三个属性
A、B、C,其中A与C互斥,即A存在时不允许C存在。而A与B绑定,即A存在时B也必须存在,A不存在时B也不允许存在。此时应该如何实现?
另外,你可能发现 Pick 会约束第二个参数的联合类型来自于对象属性,而 Omit 并不这么要求?官方团队的考量是,可能存在这么一种情况:
type Omit1<T, K> = Pick<T, Exclude<keyof T, K>>;
type Omit2<T, K extends keyof T> = Pick<T, Exclude<keyof T, K>>;
// 这里就不能用严格 Omit 了
declare function combineSpread<T1, T2>(obj: T1, otherObj: T2, rest: Omit1<T1, keyof T2>): void;
type Point3d = { x: number, y: number, z: number };
declare const p1: Point3d;
// 能够检测出错误,rest 中缺少了 y
combineSpread(p1, { x: 10 }, { z: 2 });这里我们使用 keyof Obj2 去剔除 Obj1,此时如果声明约束反而不符合预期。
集合工具类型
这一部分的工具类型主要使用条件类型、条件类型分布式特性。
在开始集合类型前,我们不妨先聊一聊数学中的集合概念。对于两个集合来说,通常存在交集、并集、差集、补集这么几种情况,用图表示是这样的:
我们搭配上图来依次解释这些概念。
- 并集,两个集合的合并,合并时重复的元素只会保留一份(这也是联合类型的表现行为)。
- 交集,两个集合的相交部分,即同时存在于这两个集合内的元素组成的集合。
- 差集,对于 A、B 两个集合来说,A 相对于 B 的差集即为 A 中独有而 B 中不存在的元素 的组成的集合,或者说 A 中剔除了 B 中也存在的元素以后,还剩下的部分。
- 补集,补集是差集的特殊情况,此时集合 B 为集合 A 的子集,在这种情况下 A 相对于 B 的差集 + B = 完整的集合 A。
内置工具类型中提供了交集与差集的实现:
type Extract<T, U> = T extends U ? T : never;
type Exclude<T, U> = T extends U ? never : T;这里的具体实现其实就是条件类型的分布式特性,即当 T、U 都是联合类型(视为一个集合)时,T 的成员会依次被拿出来进行 extends U ? T1 : T2 的计算,然后将最终的结果再合并成联合类型。
比如对于交集 Extract ,其运行逻辑是这样的:
type AExtractB = Extract<1 | 2 | 3, 1 | 2 | 4>; // 1 | 2
type _AExtractB =
| (1 extends 1 | 2 | 4 ? 1 : never) // 1
| (2 extends 1 | 2 | 4 ? 2 : never) // 2
| (3 extends 1 | 2 | 4 ? 3 : never); // never而差集 Exclude 也是类似,但需要注意的是,差集存在相对的概念,即 A 相对于 B 的差集与 B 相对于 A 的差集并不一定相同,而交集则一定相同。
为了便于理解,我们也将差集展开:
type SetA = 1 | 2 | 3 | 5;
type SetB = 0 | 1 | 2 | 4;
type AExcludeB = Exclude<SetA, SetB>; // 3 | 5
type BExcludeA = Exclude<SetB, SetA>; // 0 | 4
type _AExcludeB =
| (1 extends 0 | 1 | 2 | 4 ? never : 1) // never
| (2 extends 0 | 1 | 2 | 4 ? never : 2) // never
| (3 extends 0 | 1 | 2 | 4 ? never : 3) // 3
| (5 extends 0 | 1 | 2 | 4 ? never : 5); // 5
type _BExcludeA =
| (0 extends 1 | 2 | 3 | 5 ? never : 0) // 0
| (1 extends 1 | 2 | 3 | 5 ? never : 1) // never
| (2 extends 1 | 2 | 3 | 5 ? never : 2) // never
| (4 extends 1 | 2 | 3 | 5 ? never : 4); // 4除了差集和交集,我们也可以很容易实现并集与补集,为了更好地建立印象,这里我们使用集合相关的命名:
// 并集
export type Concurrence<A, B> = A | B;
// 交集
export type Intersection<A, B> = A extends B ? A : never;
// 差集
export type Difference<A, B> = A extends B ? never : A;
// 补集
export type Complement<A, B extends A> = Difference<A, B>;补集基于差集实现,我们只需要约束集合 B 为集合 A 的子集即可。
内置工具类型中还有一个场景比较明确的集合工具类型:
type NonNullable<T> = T extends null | undefined ? never : T;
type _NonNullable<T> = Difference<T, null | undefined>很明显,它的本质就是集合 T 相对于 null | undefined 的差集,因此我们可以用之前的差集来进行实现。
在基于分布式条件类型的工具类型中,其实也存在着正反工具类型,但并不都是简单地替换条件类型结果的两端,如交集与补集就只是简单调换了结果,但二者作用却完全不同。
联合类型中会自动合并相同的元素,因此我们可以默认这里指的类型集合全部都是类似 Set 那样的结构,不存在重复元素。
思考
- 目前为止我们的集合类型都停留在一维的层面,即联合类型之间的集合运算。如果现在我们要处理对象类型结构的集合运算呢?
- 在处理对象类型结构运算时,可能存在不同的需求,比如合并时,我们可能希望保留原属性或替换原属性,可能希望替换原属性的同时并不追加新的属性进来(即仅使用新的对象类型中的属性值覆盖原本对象类型中的同名属性值),此时要如何灵活地处理这些情况?
模式匹配工具类型
这一部分的工具类型主要使用条件类型与 infer 关键字。
在条件类型一节中我们已经差不多了解了 infer 关键字的使用,而更严格地说 infer 其实代表了一种 模式匹配(pattern matching) 的思路,如正则表达式、Glob 中等都体现了这一概念。
首先是对函数类型签名的模式匹配:
type FunctionType = (...args: any) => any;
type Parameters<T extends FunctionType> = T extends (...args: infer P) => any ? P : never;
type ReturnType<T extends FunctionType> = T extends (...args: any) => infer R ? R : any;根据 infer 的位置不同,我们就能够获取到不同位置的类型,在函数这里则是参数类型与返回值类型。
我们还可以更进一步,比如只匹配第一个参数类型:
type FirstParameter<T extends FunctionType> = T extends (
arg: infer P,
...args: any
) => any
? P
: never;
type FuncFoo = (arg: number) => void;
type FuncBar = (...args: string[]) => void;
type FooFirstParameter = FirstParameter<FuncFoo>; // number
type BarFirstParameter = FirstParameter<FuncBar>; // string除了对函数类型进行模式匹配,内置工具类型中还有一组对 Class 进行模式匹配的工具类型:
type ClassType = abstract new (...args: any) => any;
type ConstructorParameters<T extends ClassType> = T extends abstract new (
...args: infer P
) => any
? P
: never;
type InstanceType<T extends ClassType> = T extends abstract new (
...args: any
) => infer R
? R
: any;Class 的通用类型签名可能看起来比较奇怪,但实际上它就是声明了可实例化(new)与可抽象(abstract)罢了。我们也可以使用接口来进行声明:
export interface ClassType<TInstanceType = any> {
new (...args: any[]): TInstanceType;
}对 Class 的模式匹配思路类似于函数,或者说这是一个通用的思路,即基于放置位置的匹配。放在参数部分,那就是构造函数的参数类型,放在返回值部分,那当然就是 Class 的实例类型了。
思考
infer和条件类型的搭配看起来会有奇效,比如在哪些场景?比如随着条件类型的嵌套每个分支会提取不同位置的 infer ?infer在某些特殊位置下应该如何处理?比如上面我们写了第一个参数类型,不妨试着来写写最后一个参数类型?
infer 约束
在某些时候,我们可能对 infer 提取的类型值有些要求,比如我只想要数组第一个为字符串的成员,如果第一个成员不是字符串,那我就不要了。
先写一个提取数组第一个成员的工具类型:
type FirstArrayItemType<T extends any[]> = T extends [infer P, ...any[]]
? P
: never;加上对提取字符串的条件类型:
type FirstArrayItemType<T extends any[]> = T extends [infer P, ...any[]]
? P extends string
? P
: never
: never;试用一下:
type Tmp1 = FirstArrayItemType<[599, 'linbudu']>; // never
type Tmp2 = FirstArrayItemType<['linbudu', 599]>; // 'linbudu'
type Tmp3 = FirstArrayItemType<['linbudu']>; // 'linbudu'看起来好像能满足需求,但程序员总是精益求精的。泛型可以声明约束,只允许传入特定的类型,那 infer 中能否也添加约束,只提取特定的类型?
TypeScript 4.7 就支持了 infer 约束功能来实现对特定类型地提取,比如上面的例子可以改写为这样:
type FirstArrayItemType<T extends any[]> = T extends [infer P extends string, ...any[]]
? P
: never;实际上,infer + 约束的场景是非常常见的,尤其是在某些连续嵌套的情况下,一层层的 infer 提取再筛选会严重地影响代码的可读性,而 infer 约束这一功能无疑带来了更简洁直观的类型编程代码。