Vite
简介
Vite(法语意为 "快速的",发音 /vit/,发音同 "veet")是一种新型前端构建工具,能够显著提升前端开发体验。它主要由两部分组成:
一个开发服务器,它基于 原生 ES 模块 提供了 丰富的内建功能,如速度快到惊人的 模块热更新(HMR)。
一套构建指令,它使用 Rollup 打包你的代码,并且它是预配置的,可输出用于生产环境的高度优化过的静态资源。
Vite 意在提供开箱即用的配置,同时它的 插件 API 和 JavaScript API 带来了高度的可扩展性,并有完整的类型支持。
快速上手
- 环境搭建
- 前往Node.js官网安装Node环境,推荐 12.0.0 及以上版本,如果低于这个版本,推荐使用 nvm 工具切换 Node.js 版本。
- 安装包管理工具shell
npm i -g pnpm # 推荐使用 pnpm 做包管理器 pnpm config set registry https://registry.npmmirror.com/ # 设置国内镜像源
- 项目初始化pnpmshell交互流程:
pnpm create vite- 输入项目名称;
- 选择前端框架;
- 选择开发语言。
shell# 进入项目目录 cd vite-project # 安装依赖 pnpm install # 启动项目 pnpm run dev - 初识配置文件ts
// vite.config.ts import { defineConfig } from 'vite' // 引入 path 包注意两点: // 1. 为避免类型报错,你需要通过 `pnpm i @types/node -D` 安装类型 // 2. tsconfig.node.json 中设置 `allowSyntheticDefaultImports: true`,以允许下面的 default 导入方式 import path from 'path' import react from '@vitejs/plugin-react' // 官方 react 插件 export default defineConfig({ root: path.join(__dirname, 'src'), // 手动指定项目根目录位置 plugins: [react()] // 注入 react 插件来提供 React 项目编译和热更新的功能 })
接入CSS工程化
原生css存在的问题
- 开发体验欠佳。比如原生 CSS 不支持选择器的嵌套。
- 样式污染问题。如果出现同样的类名,很容易造成不同的样式互相覆盖和污染。
- 浏览器兼容问题。为了兼容不同的浏览器,我们需要对一些属性(如transition)加上不同的浏览器前缀,比如 -webkit-、-moz-、-ms-、-o-,意味着开发者要针对同一个样式属性写很多的冗余代码。
- 打包后的代码体积问题。如果不用任何的 CSS 工程化方案,所有的 CSS 代码都将打包到产物中,即使有部分样式并没有在代码中使用,导致产物体积过大。
解决方案
- CSS 预处理器:主流的包括Sass/Scss、Less和Stylus。这些方案各自定义了一套语法,让 CSS 也能使用嵌套规则,甚至能像编程语言一样定义变量、写条件判断和循环语句,大大增强了样式语言的灵活性,解决原生 CSS 的开发体验问题。
- CSS Modules:能将 CSS 类名处理成哈希值,这样就可以避免同名的情况下样式污染的问题。
- CSS 后处理器PostCSS,用来解析和处理 CSS 代码,可以实现的功能非常丰富,比如将 px 转换为 rem、根据目标浏览器情况自动加上类似于--moz--、-o-的属性前缀等等。
- CSS in JS 方案,主流的包括emotion、styled-components等等,顾名思义,这类方案可以实现直接在 JS 中写样式代码,基本包含CSS 预处理器和 CSS Modules 的各项优点,非常灵活,解决了开发体验和全局样式污染的问题。
- CSS 原子化框架,如Tailwind CSS、Windi CSS,通过类名来指定样式,大大简化了样式写法,提高了样式开发的效率,主要解决了原生 CSS 开发体验的问题。
CSS 预处理器
Vite 底层会调用 CSS 预处理器的官方库进行编译,而 Vite 为了实现按需加载,并没有内置这些工具库,而是让用户根据需要安装。因此,我们首先安装 Sass 的官方库,安装命令如下shellpnpm i sass -D配置自动注入全局CSS
ts// vite.config.ts import { normalizePath } from 'vite'; // 如果类型报错,需要安装 @types/node: pnpm i @types/node -D import path from 'path'; // 全局 scss 文件的路径 // 用 normalizePath 解决 window 下的路径问题 const variablePath = normalizePath(path.resolve('./src/variable.scss')); export default defineConfig({ // css 相关的配置 css: { preprocessorOptions: { scss: { // additionalData 的内容会在每个 scss 文件的开头自动注入 additionalData: `@import "${variablePath}";` } } } })CSS Modules
CSS Modules 在 Vite 也是一个开箱即用的能力,Vite 会对后缀带有.module的样式文件自动应用 CSS Modules。tsx// index.tsx import styles from './index.module.scss'; export function Header() { return <p className={styles.header}>This is Header</p> };自定义 CSS Modules 的哈希类名
ts// vite.config.ts export default { css: { modules: { // 一般我们可以通过 generateScopedName 属性来对生成的类名进行自定义 // 其中,name 表示当前文件名,local 表示类名 generateScopedName: "[name]__[local]___[hash:base64:5]" }, preprocessorOptions: { // 省略预处理器配置 } } }PostCSS
一般你可以通过 postcss.config.js 来配置 postcss ,不过在 Vite 配置文件中已经提供了 PostCSS 的配置入口,我们可以直接在 Vite 配置文件中进行操作。shell# 安装 autoprefixer 插件 # 插件主要用来自动为不同的目标浏览器添加样式前缀,解决的是浏览器兼容性的问题 pnpm i autoprefixer -D在 Vite 中 配置该插件
ts// vite.config.ts 增加如下的配置 import autoprefixer from 'autoprefixer'; export default { css: { // 进行 PostCSS 配置 postcss: { plugins: [ autoprefixer({ // 指定目标浏览器 overrideBrowserslist: ['Chrome > 40', 'ff > 31', 'ie 11'] }) ] } } }常见的插件还包括:
- postcss-pxtorem: 用来将 px 转换为 rem 单位,在适配移动端的场景下很常用。
- postcss-preset-env: 通过它,你可以编写最新的 CSS 语法,不用担心兼容性问题。
- cssnano: 主要用来压缩 CSS 代码,跟常规的代码压缩工具不一样,它能做得更加智能,比如提取一些公共样式进行复用、缩短一些常见的属性值等等。
更多插件请访问:PostCss插件市场
CSS In JS
- 社区中有两款主流的CSS In JS 方案: styled-components和emotion。
- 对于 CSS In JS 方案,在构建侧我们需要考虑选择器命名问题、DCE(Dead Code Elimination 即无用代码删除)、代码压缩、生成 SourceMap、服务端渲染(SSR)等问题,而styled-components和emotion已经提供了对应的 babel 插件来解决这些问题,我们在 Vite 中要做的就是集成这些 babel 插件。
- 上述的两种主流 CSS in JS 方案在 Vite 中集成方式如下:ts
// vite.config.ts import { defineConfig } from 'vite' import react from '@vitejs/plugin-react' // https://vitejs.dev/config/ export default defineConfig({ plugins: [ react({ babel: { // 加入 babel 插件 // 以下插件包都需要提前安装 // 当然,通过这个配置你也可以添加其它的 Babel 插件 plugins: [ // 适配 styled-component "babel-plugin-styled-components", // 适配 emotion "@emotion/babel-plugin" ] }, // 注意: 对于 emotion,需要单独加上这个配置 // 通过 `@emotion/react` 包编译 emotion 中的特殊 jsx 语法 jsxImportSource: "@emotion/react" }) ] })
CSS 原子化框架
Windi CSS 接入
shellpnpm i windicss vite-plugin-windicss -D在配置文件中加入
ts// vite.config.ts import windi from "vite-plugin-windicss"; export default { plugins: [ // 省略其它插件 windi() ] }接着要注意在src/main.tsx中引入一个必需的 import 语句
tsx// main.tsx // 用来注入 Windi CSS 所需的样式,一定要加上! import "virtual:windi.css";测试:
tsx// src/components/Header/index.tsx import { devDependencies } from "../../../package.json"; export function Header() { return ( <div className="p-20px text-center"> <h1 className="font-bold text-2xl mb-2"> vite version: {devDependencies.vite} </h1> </div> ); }高级功能
tsimport { defineConfig } from "vite-plugin-windicss"; export default defineConfig({ // 开启 attributify 属性化, 可以用 props 的方式去定义样式属性。 attributify: true, });演示
tsx<button bg="blue-400 hover:blue-500 dark:blue-500 dark:hover:blue-600" text="sm white" font="mono light" p="y-2 x-4" border="2 rounded blue-200" > Button </button>使用 attributify 的时候需要注意类型问题,你需要添加types/shim.d.ts来增加类型声明,以防类型报错:
tsimport { AttributifyAttributes } from 'windicss/types/jsx'; declare module 'react' { type HTMLAttributes<T> = AttributifyAttributes; }shortcuts 用来封装一系列的原子化能力,尤其是一些常见的类名集合,配置如下:
ts//windi.config.ts import { defineConfig } from "vite-plugin-windicss"; export default defineConfig({ attributify: true, shortcuts: { "flex-c": "flex justify-center items-center", } });演示
tsx<div className="flex-c"></div> <!-- 等同于下面这段 --> <div className="flex justify-center items-center"></div>Tailwind CSS
shellpnpm install -D tailwindcss postcss autoprefixer新建两个配置文件tailwind.config.js和postcss.config.js
ts// tailwind.config.js module.exports = { content: [ "./index.html", "./src/**/*.{vue,js,ts,jsx,tsx}", ], theme: { extend: {}, }, plugins: [], }ts// postcss.config.js // 从中你可以看到,Tailwind CSS 的编译能力是通过 PostCSS 插件实现的 // 而 Vite 本身内置了 PostCSS,因此可以通过 PostCSS 配置接入 Tailwind CSS // 注意: Vite 配置文件中如果有 PostCSS 配置的情况下会覆盖掉 postcss.config.js 的内容! module.exports = { plugins: { tailwindcss: {}, autoprefixer: {}, }, }接着在项目的入口 CSS 中引入必要的样板代码:
scss@tailwind base; @tailwind components; @tailwind utilities;演示
tsx// App.tsx import logo from "./logo.svg"; import "./App.css"; function App() { return ( <div> <header className="App-header"> <img src={logo} className="w-20" alt="logo" /> <p className="bg-red-400">Hello Vite + React!</p> </header> </div> ); } export default App;
代码规范
ESLint
shell# 安装 pnpm i eslint -Dshell# 初始化 npx eslint --initshell# 安装依赖 pnpm i eslint-plugin-react@latest @typescript-eslint/eslint-plugin@latest @typescript-eslint/parser@latest -D核心配置解读
parser - 解析器
- ESLint 底层默认使用 Espree来进行 AST 解析,这个解析器目前已经基于 Acron 来实现,虽然说 Acron 目前能够解析绝大多数的 ECMAScript 规范的语法,但还是不支持 TypeScript ,因此需要引入其他的解析器完成 TS 的解析。
- 社区提供了@typescript-eslint/parser这个解决方案,专门为了 TypeScript 的解析而诞生,将 TS 代码转换为 Espree 能够识别的格式(即 Estree 格式),然后在 Eslint 下通过Espree进行格式检查, 以此兼容了 TypeScript 语法。
parserOptions - 解析器选项
这个配置可以对上述的解析器进行能力定制,默认情况下 ESLint 支持 ES5 语法,你可以配置这个选项,具体内容如下:
- ecmaVersion: 这个配置和 Acron 的 ecmaVersion 是兼容的,可以配置 ES + 数字(如 ES6)或者ES + 年份(如 ES2015),也可以直接配置为latest,启用最新的 ES 语法。
- sourceType: 默认为script,如果使用 ES Module 则应设置为module。
- ecmaFeatures: 为一个对象,表示想使用的额外语言特性,如开启 jsx。
rules - 具体代码规则
rules 配置即代表在 ESLint 中手动调整哪些代码规则,比如禁止在 if 语句中使用赋值语句这条规则可以像如下的方式配置:
ts// .eslintrc.js module.exports = { // 其它配置省略 rules: { // key 为规则名,value 配置内容 "no-cond-assign": ["error", "always"] } }在 rules 对象中,key 一般为规则名,value 为具体的配置内容,在上述的例子中我们设置为一个数组,数组第一项为规则的 ID,第二项为规则的配置。
这里重点说一说规则的 ID,它的语法对所有规则都适用,你可以设置以下的值:
- off 或 0: 表示关闭规则。
- warn 或 1: 表示开启规则,不过违背规则后只抛出 warning,而不会导致程序退出。
- error 或 2: 表示开启规则,不过违背规则后抛出 error,程序会退出。
具体的规则配置可能会不一样,有的是一个字符串,有的可以配置一个对象,你可以参考 ESLint 官方文档。
当然,你也能直接将 rules 对象的 value 配置成 ID,如: "no-cond-assign": "error"。
plugins
我们需要通过添加 ESLint 插件来增加一些特定的规则,比如添加@typescript-eslint/eslint-plugin 来拓展一些关于 TS 代码的规则,如下代码所示:
ts// .eslintrc.js module.exports = { // 添加 TS 规则,可省略`eslint-plugin` plugins: ['@typescript-eslint'] }值得注意的是,添加插件后只是拓展了 ESLint 本身的规则集,但 ESLint 默认并没有开启这些规则的校验!如果要开启或者调整这些规则,你需要在 rules 中进行配置,如:
ts// .eslintrc.js module.exports = { // 开启一些 TS 规则 rules: { '@typescript-eslint/ban-ts-comment': 'error', '@typescript-eslint/no-explicit-any': 'warn', } }extends - 继承配置
extends 相当于继承另外一份 ESLint 配置,可以配置为一个字符串,也可以配置成一个字符串数组。主要分如下 3 种情况:
- 从 ESLint 本身继承;
- 从类似 eslint-config-xxx 的 npm 包继承;
- 从 ESLint 插件继承。
ts// .eslintrc.js module.exports = { "extends": [ // 第1种情况 "eslint:recommended", // 第2种情况,一般配置的时候可以省略 `eslint-config` "standard", // 第3种情况,可以省略包名中的 `eslint-plugin` // 格式一般为: `plugin:${pluginName}/${configName}` "plugin:react/recommended", "plugin:@typescript-eslint/recommended", ] }有了 extends 的配置,对于之前所说的 ESLint 插件中的繁多配置,我们就不需要手动一一开启了,通过 extends 字段即可自动开启插件中的推荐规则:
jsextends: ["plugin:@typescript-eslint/recommended"]env 和 globals
这两个配置分别表示运行环境和全局变量,在指定的运行环境中会预设一些全局变量,比如:
ts// .eslint.js module.export = { "env": { "browser": "true", "node": "true" } }指定上述的 env 配置后便会启用浏览器和 Node.js 环境,这两个环境中的一些全局变量(如 window、global 等)会同时启用。
有些全局变量是业务代码引入的第三方库所声明,这里就需要在globals配置中声明全局变量了。每个全局变量的配置值有 3 种情况:
- "writable"或者 true,表示变量可重写;
- "readonly"或者false,表示变量不可重写;
- "off",表示禁用该全局变量。
举例如下:
ts// .eslintrc.js module.exports = { "globals": { // 不可重写 "$": false, "jQuery": false } }
Prettier
ESLint 的主要优势在于代码的风格检查并给出提示,而在代码格式化这一块 Prettier 做的更加专业,因此我们经常将 ESLint 结合 Prettier 一起使用。shell# 安装 pnpm i prettier -Dts// 新建.prettierrc.js配置文件 module.exports = { printWidth: 80, //一行的字符数,如果超过会进行换行,默认为80 tabWidth: 2, // 一个 tab 代表几个空格数,默认为 2 个 useTabs: false, //是否使用 tab 进行缩进,默认为false,表示用空格进行缩减 singleQuote: true, // 字符串是否使用单引号,默认为 false,使用双引号 semi: true, // 行尾是否使用分号,默认为true trailingComma: "none", // 是否使用尾逗号 bracketSpacing: true // 对象大括号直接是否有空格,默认为 true,效果:{ a: 1 } };将Prettier集成到现有的ESLint工具中,首先安装两个工具包
shell# eslint-config-prettier用来覆盖 ESLint 本身的规则配置 # eslint-plugin-prettier则是用于让 Prettier 来接管eslint --fix即修复代码的能力。 pnpm i eslint-config-prettier eslint-plugin-prettier -D在 .eslintrc.js 配置文件中接入 prettier 的相关工具链,最终的配置代码如下所示
ts// .eslintrc.js module.exports = { env: { browser: true, es2021: true }, extends: [ "eslint:recommended", "plugin:react/recommended", "plugin:@typescript-eslint/recommended", // 1. 接入 prettier 的规则 "prettier", "plugin:prettier/recommended" ], parser: "@typescript-eslint/parser", parserOptions: { ecmaFeatures: { jsx: true }, ecmaVersion: "latest", sourceType: "module" }, // 2. 加入 prettier 的 eslint 插件 plugins: ["react", "@typescript-eslint", "prettier"], rules: { // 3. 注意要加上这一句,开启 prettier 自动修复的功能 "prettier/prettier": "error", quotes: ["error", "single"], semi: ["error", "always"], "react/react-in-jsx-scope": "off" } }package.json 中定义一个脚本:
json{ "scripts": { // 省略已有 script "lint:script": "eslint --ext .js,.jsx,.ts,.tsx --fix --quiet ./src", } }执行命令
shellpnpm run lint:script这样我们就完成了 ESLint 的规则检查以及 Prettier 的自动修复。不过每次执行这个命令未免会有些繁琐,我们可以在VSCode中安装ESLint和Prettier这两个插件,并且在设置区中开启Format On Save
接下来在你按Ctrl + S保存代码的时候,Prettier 便会自动帮忙修复代码格式。
Vite 中接入 ESLint
我们可以通过 Vite 插件的方式在开发阶段进行 ESLint 扫描,以命令行的方式展示出代码中的规范问题,并能够直接定位到原文件。shell# 安装插件 pnpm i vite-plugin-eslint -Dts// 注入插件 // vite.config.ts import viteEslint from 'vite-plugin-eslint'; // 具体配置 { plugins: [ // 省略其它插件 viteEslint(), ] }由于这个插件采用另一个进程来运行 ESLint 的扫描工作,因此不会影响 Vite 项目的启动速度,这个大家不用担心。
Stylelint
Stylelint 主要专注于样式代码的规范检查,内置了 170 多个 CSS 书写规则,支持 CSS 预处理器(如 Sass、Less),提供插件化机制以供开发者扩展规则,已经被 Google、Github 等大型团队投入使用。与 ESLint 类似,在规范检查方面,Stylelint 已经做的足够专业,而在代码格式化方面,我们仍然需要结合 Prettier 一起来使用。shell# 安装套件依赖 pnpm i stylelint stylelint-prettier stylelint-config-prettier stylelint-config-recess-order stylelint-config-standard stylelint-config-standard-scss -Dts// .stylelintrc.js module.exports = { // 注册 stylelint 的 prettier 插件 plugins: ['stylelint-prettier'], // 继承一系列规则集合 extends: [ // standard 规则集合 'stylelint-config-standard', // standard 规则集合的 scss 版本 'stylelint-config-standard-scss', // 样式属性顺序规则 'stylelint-config-recess-order', // 接入 Prettier 规则 'stylelint-config-prettier', 'stylelint-prettier/recommended' ], // 配置 rules rules: { // 开启 Prettier 自动格式化功能 'prettier/prettier': true } };可以发现 Stylelint 的配置文件和 ESLint 还是非常相似的,常用的plugins、extends和rules属性在 ESLint 同样存在,并且与 ESLint 中这三个属性的功能也基本相同。不过需要强调的是在 Stylelint 中 rules 的配置会和 ESLint 有些区别,对于每个具体的 rule 会有三种配置方式:
- null,表示关闭规则。
- 一个简单值(如 true,字符串,根据不同规则有所不同),表示开启规则,但并不做过多的定制。
- 一个数组,包含两个元素,即[简单值,自定义配置],第一个元素通常为一个简单值,第二个元素用来进行更精细化的规则配置。
package.json 中,增加如下的 scripts 配置
json{ "scripts": { // 整合 lint 命令 "lint": "npm run lint:script && npm run lint:style", // stylelint 命令 "lint:style": "stylelint --fix \"src/**/*.{css,scss}\"" } }执行pnpm run lint:style即可完成样式代码的规范检查和自动格式化。当然,你也可以在 VSCode 中安装Stylelint插件,这样能够在开发阶段即时感知到代码格式问题,提前进行修复。
当然,我们也可以直接在 Vite 中集成 Stylelint。社区中提供了 Stylelint 的 Vite 插件,实现在项目开发阶段提前暴露出样式代码的规范问题。我们来安装一下这个插件:shell# Vite 2.x pnpm i @amatlash/vite-plugin-stylelint -D # Vite 3.x 及以后的版本 pnpm i vite-plugin-stylelint -D然后在 Vite 配置文件中添加如下的内容:
ts// vite.config.js import viteStylelint from '@amatlash/vite-plugin-stylelint'; // 注意: Vite 3.x 以及以后的版本需要引入 vite-plugin-stylelint // 具体配置 { plugins: [ // 省略其它插件 viteStylelint({ // 对某些文件排除检查 exclude: /windicss|node_modules/ }), ] }Husky + lint-staged 的 Git 提交工作流集成
保证规范问题能够被完美解决,我们可以在代码提交的时候进行卡点检查,也就是拦截 git commit 命令,进行代码格式检查,只有确保通过格式检查才允许正常提交代码。社区中已经有了对应的工具——Husky来完成这件事情,让我们来安装一下这个工具:shellpnpm i husky -D值得提醒的是,有很多人推荐在package.json中配置 husky 的钩子:
json// package.json { "husky": { "pre-commit": "npm run lint" } }这种做法在 Husky 4.x 及以下版本没问题,而在最新版本(7.x 版本)中是无效的!在新版 Husky 版本中,我们需要做如下的事情:
- 初始化 Husky: npx husky install,并将 husky install作为项目启动前脚本json
{ "scripts": { // 会在安装 npm 依赖后自动执行 "prepare": "husky install" } } - 添加 Husky 钩子,在终端执行如下命令:shell
npx husky add .husky/pre-commit "npm run lint"
接着你将会在项目根目录的.husky目录中看到名为pre-commit的文件,里面包含了 git commit前要执行的脚本。现在,当你执行 git commit 的时候,会首先执行 npm run lint脚本,通过 Lint 检查后才会正式提交代码记录。
Husky 中每次执行npm run lint都对仓库中的代码进行全量检查,而lint-staged就是用来解决上述全量扫描问题的,可以实现只对存入暂存区的文件进行 Lint 检查shellpnpm i -D lint-staged然后在 package.json中添加如下的配置:
json{ "lint-staged": { "**/*.{js,jsx,tsx,ts}": [ "npm run lint:script", "git add ." ], "**/*.{scss}": [ "npm run lint:style", "git add ." ] } }接下来我们需要在 Husky 中应用lint-stage,回到.husky/pre-commit脚本中,将原来的npm run lint换成如下脚本:
shellnpx --no -- lint-staged- 初始化 Husky: npx husky install,并将 husky install作为项目启动前脚本
提交时的 commit 信息规范
shell# 安装工具库 pnpm i commitlint @commitlint/cli @commitlint/config-conventional -Dts// .commitlintrc.js module.exports = { extends: ["@commitlint/config-conventional"] };一般我们直接使用@commitlint/config-conventional规范集就可以了,它所规定的 commit 信息一般由两个部分: type 和 subject 组成,结构如下:
ts// type 指提交的类型 // subject 指提交的摘要信息 <type>: <subject>常用的 type 值包括如下:
- feat: 添加新功能。
- fix: 修复 Bug。
- chore: 一些不影响功能的更改。
- docs: 专指文档的修改。
- perf: 性能方面的优化。
- refactor: 代码重构。
- test: 添加一些测试代码等等。
接下来我们将commitlint的功能集成到 Husky 的钩子当中,在终端执行如下命令即可shellnpx husky add .husky/commit-msg "npx --no-install commitlint -e $HUSKY_GIT_PARAMS"Commitizen
shell# 安装全局工具 npm install -g commitizen cz-conventional-changelog创建 ~/.czrc 文件,写入如下内容
json{ "path": "cz-conventional-changelog" }这时就可以全局使用 git cz 命令来代替 git commit 命令了
接下来在项目中安装commitizenshellpnpm i commitizen -Djson// package.json { "scripts": { "commit": "git-cz" }, "config": { "commitizen": { "path": "node_modules/cz-conventional-changelog" } } }定制提交
shell# 全局安装 npm i cz-customizable -gjson{ "scripts": { "commit": "./node_modules/cz-customizable/standalone.js" }, "config": { "commitizen": { "path": "node_modules/cz-customizable" } } }cz-customizable首先会在项目根目录中查找名为.cz-config.js的文件,也可以自定义配置文件路径,如下:
json{ "scripts": { "commit": "./node_modules/cz-customizable/standalone.js" }, "config": { "commitizen": { "path": "node_modules/cz-customizable" }, "cz-customizable": { "config": "config/path/to/my/config.js" } } }配置.cz-config.js文件
jsmodule.exports = { // 可选类型 types: [ { value: 'feat', name: 'feat: 新功能' }, { value: 'fix', name: 'fix: 修复' }, { value: 'docs', name: 'docs: 文档变更' }, { value: 'style', name: 'style: 代码格式(不影响代码运行的变动)' }, { value: 'refactor', name: 'refactor: 重构(既不是增加feature, 也不是修复bug)' }, { value: 'perf', name: 'perf: 性能优化' }, { value: 'test', name: 'test: 增加测试' }, { value: 'chore', name: 'chore: 构建过程或辅助工具的变动' }, { value: 'revert', name: 'revert: 回退' }, { value: 'build', name: 'build: 打包' }, { value: 'ci', name: 'ci: 持续集成相关文件修改' }, { value: 'release', name: 'release: 发布新版本' }, { value: 'workflow', name: 'workflow: 工作流相关文件修改' } ], // 消息步骤 messages: { type: '请选择提交类型:', customScope: '请输入修改范围(可选):', subject: '请简要描述提交(必填):', body: '请输入详细描述(可选):', footer: '请输入要关闭的issue(可选):', confirmCommit: '请确认使用以上信息提交?(y/n)' }, // 跳过问题 skipQuestions: ['body', 'footer'], // subject文字长度默认是72 subjectLimit: 72 }
处理静态资源
配置路径别名
js// vite.config.ts import path from 'path'; { resolve: { // 别名配置 alias: { '@assets': path.join(__dirname, 'src/assets') } } }使用Web Worker
js// 新建 example.js const start = () => { let count = 0; setInterval(() => { // 给主线程传值 postMessage(++count); }, 2000); }; start();引入时加上?worker后缀,告诉 Vite 这是一个Web Worker脚本文件
jsimport Worker from './example.js?worker'; // 1. 初始化 Worker 实例 const worker = new Worker(); // 2. 主线程监听 worker 的信息 worker.addEventListener('message', (e) => { console.log(e); });使用Web Assembly
js// 新建 fib.wasm 文件 export function fib(n) { var a = 0, b = 1; if (n > 0) { while (--n) { let t = a + b; a = b; b = t; } return b; } return a; }组件中导入fib.wasm文件
tsx// Header/index.tsx import init from './fib.wasm?init'; type FibFunc = (num: number) => number; init({}).then((exports) => { const fibFunc = exports.fib as FibFunc; console.log('Fib result:', fibFunc(10)); });Vite 会对.wasm文件的内容进行封装,默认导出为 init 函数,这个函数返回一个 Promise,因此我们可以在其 then 方法中拿到其导出的成员——fib方法。
其它静态资源
除了上述的一些资源格式,Vite 也对下面几类格式提供了内置的支持:- 媒体类文件,包括mp4、webm、ogg、mp3、wav、flac和aac。
- 字体类文件。包括woff、woff2、eot、ttf 和 otf。
- 文本类。包括webmanifest、pdf和txt。
也就是说,你可以在 Vite 将这些类型的文件当做一个 ES 模块来导入使用。如果你的项目中还存在其它格式的静态资源,你可以通过assetsInclude配置让 Vite 来支持加载:ts// vite.config.ts { assetsInclude: ['.gltf'] }特殊资源后缀
Vite 中引入静态资源时,也支持在路径最后加上一些特殊的 query 后缀,包括:- ?url: 表示获取资源的路径,这在只想获取文件路径而不是内容的场景将会很有用。
- ?raw: 表示获取资源的字符串内容,如果你只想拿到资源的原始内容,可以使用这个后缀。
- ?inline: 表示资源强制内联,而不是打包成单独的文件。
生产环境处理
自定义部署域名
js// vite.config.ts // 是否为生产环境,在生产环境一般会注入 NODE_ENV 这个环境变量,见下面的环境变量文件配置 const isProduction = process.env.NODE_ENV === 'production'; // 填入项目的 CDN 域名地址 const CDN_URL = 'xxxxxx'; // 具体配置 { base: isProduction ? CDN_URL: '/' }注意在项目根目录新增的两个环境变量文件.env.development和.env.production,顾名思义,即分别在开发环境和生产环境注入一些环境变量,这里为了区分不同环境我们加上了NODE_ENV,你也可以根据需要添加别的环境变量。
打包的时候 Vite 会自动将这些环境变量替换为相应的字符串。
js// .env.development NODE_ENV=developmentjs// .env.production NODE_ENV=production有时候可能项目中的某些图片需要存放到另外的存储服务,我们可以通过定义环境变量的方式来解决这个问题,在项目根目录新增.env文件:
js// 开发环境优先级: .env.development > .env // 生产环境优先级: .env.production > .env // .env 文件 VITE_IMG_BASE_URL=https://my-image-cdn.com然后进入 src/vite-env.d.ts增加类型声明:
ts/// <reference types="vite/client" /> interface ImportMetaEnv { readonly VITE_APP_TITLE: string; // 自定义的环境变量 readonly VITE_IMG_BASE_URL: string; } interface ImportMeta { readonly env: ImportMetaEnv; }如果某个环境变量要在 Vite 中通过 i
mport.meta.env 访问,那么它必须以VITE_开头,如VITE_IMG_BASE_URL。接下来我们在组件中来使用这个环境变量: tsx<img src={new URL('./logo.png', import.meta.env.VITE_IMG_BASE_URL).href} />单文件 or 内联
在 Vite 中,所有的静态资源都有两种构建方式,一种是打包成一个单文件,另一种是通过 base64 编码的格式内嵌到代码中。
对于比较小的资源,适合内联到代码中,一方面对代码体积的影响很小,另一方面可以减少不必要的网络请求,优化网络性能。而对于比较大的资源,就推荐单独打包成一个文件,而不是内联了,否则可能导致上 MB 的 base64 字符串内嵌到代码中,导致代码体积瞬间庞大,页面加载性能直线下降
Vite 中内置的优化方案是下面这样的:- 如果静态资源体积 >= 4KB,则提取成单独的文件
- 如果静态资源体积 < 4KB,则作为 base64 格式的字符串内联
上述的4 KB即为提取成单文件的临界值,当然,这个临界值你可以通过build.assetsInlineLimit自行配置,如下代码所示:
js// vite.config.ts { build: { // 8 KB assetsInlineLimit: 8 * 1024 } }svg 格式的文件不受这个临时值的影响,始终会打包成单独的文件,因为它和普通格式的图片不一样,需要动态设置一些属性
图片压缩
图片资源的体积往往是项目产物体积的大头,如果能尽可能精简图片的体积,那么对项目整体打包产物体积的优化将会是非常明显的。在 JavaScript 领域有一个非常知名的图片压缩库imagemin,作为一个底层的压缩工具,前端的项目中经常基于它来进行图片压缩,比如 Webpack 中大名鼎鼎的image-webpack-loader。社区当中也已经有了开箱即用的 Vite 插件 vite-plugin-imageminshell# 安装插件 pnpm i vite-plugin-imagemin -Dts//vite.config.ts import viteImagemin from 'vite-plugin-imagemin'; { plugins: [ // 忽略前面的插件 viteImagemin({ // 无损压缩配置,无损压缩下图片质量不会变差 optipng: { optimizationLevel: 7 }, // 有损压缩配置,有损压缩下图片质量可能会变差 pngquant: { quality: [0.8, 0.9], }, // svg 优化 svgo: { plugins: [ { name: 'removeViewBox' }, { name: 'removeEmptyAttrs', active: false } ] } }) ] }雪碧图优化
在实际的项目中我们还会经常用到各种各样的 svg 图标,虽然 svg 文件一般体积不大,但 Vite 中对于 svg 文件会始终打包成单文件,大量的图标引入之后会导致网络请求增加,大量的 HTTP 请求会导致网络解析耗时变长,页面加载性能直接受到影响。这个问题怎么解决呢?HTTP2 的多路复用设计可以解决大量 HTTP 的请求导致的网络加载性能问题,因此雪碧图技术在 HTTP2 并没有明显的优化效果,这个技术更适合在传统的 HTTP 1.1 场景下使用(比如本地的 Dev Server)。
Vite 中提供了i
mport.meta.glob的语法糖来解决批量导入的问题 jsconst icons = import.meta.glob('../../assets/icons/logo-*.svg');icons 的 value 都是动态 import,适合按需加载的场景,在这里我们只需要同步加载即可,可以使用 i
mport.meta.glob('*', { eager: true }) 来完成 jsconst icons = import.meta.glob('../../assets/icons/logo-*.svg', { eager: true })稍作解析,然后将 svg 应用到组件当中
tsx// Header/index.tsx const iconUrls = Object.values(icons).map(mod => mod.default); // 组件返回内容添加如下 { iconUrls.map((item) => ( <img src={item} key={item} width="50" alt="" /> )) }每一个svg都会发出一个请求,避免大量的请求,我们可以通过 vite-plugin-svg-icons 来实现雪碧图
shell# 安装插件 pnpm i vite-plugin-svg-icons -Djs// vite.config.ts import { createSvgIconsPlugin } from 'vite-plugin-svg-icons'; { plugins: [ // 省略其它插件 createSvgIconsPlugin({ iconDirs: [path.join(__dirname, 'src/assets/icons')] }) ] }在 src/components目录下新建SvgIcon组件
tsx// SvgIcon/index.tsx export interface SvgIconProps { name?: string; prefix: string; color: string; [key: string]: string; } export default function SvgIcon({ name, prefix = 'icon', color = '#333', ...props }: SvgIconProps) { const symbolId = `#${prefix}-${name}`; return ( <svg {...props} aria-hidden="true"> <use href={symbolId} fill={color} /> </svg> ); }现在我们回到 Header 组件中,稍作修改
tsx// index.tsx const icons = import.meta.globEager('../../assets/icons/logo-*.svg'); const iconUrls = Object.values(icons).map((mod) => { // 如 ../../assets/icons/logo-1.svg -> logo-1 const fileName = mod.default.split('/').pop(); const [svgName] = fileName.split('.'); return svgName; }); // 渲染 svg 组件 {iconUrls.map((item) => ( <SvgIcon name={item} key={item} width="50" height="50" /> ))}js// src/main.tsx import 'virtual:svg-icons-register';雪碧图包含了所有图标的具体内容,而对于页面每个具体的图标,则通过 use 属性来引用雪碧图的对应内容
预构建
- 首先 Vite 是基于浏览器原生 ES 模块规范实现的 Dev Server,不论是应用代码,还是第三方依赖的代码,理应符合 ESM 规范才能够正常运行。
- 每个import都会触发一次新的文件请求,因此在这种依赖层级深、涉及模块数量多的情况下,会触发成百上千个网络请求,巨大的请求量加上 Chrome 对同一个域名下只能同时支持 6 个 HTTP 并发请求的限制,导致页面加载十分缓慢,与 Vite 主导性能优势的初衷背道而驰。
依赖预构建主要做了两件事情
- 将其他格式(如 UMD 和 CommonJS)的产物转换为 ESM 格式,使其在浏览器通过
<script type="module"><script>的方式正常加载。 - 打包第三方库的代码,将各个第三方库分散的文件合并到一起,减少 HTTP 请求数量,避免页面加载性能劣化。
而这两件事情全部由性能优异的 Esbuild (基于 Golang 开发)完成,而不是传统的 Webpack/Rollup,所以也不会有明显的打包性能问题,反而是 Vite 项目启动飞快(秒级启动)的一个核心原因
Vite 1.x 使用了 Rollup 来进行依赖预构建,在 2.x 版本将 Rollup 换成了 Esbuild,编译速度提升了近 100 倍!
开启预构建
- 项目第一次启动时自动开启预构建,项目启动成功后,根目录下的node_modules中的.vite目录,就是预构建产物文件存放的目录。并且对于依赖的请求结果,Vite 的 Dev Server 会设置强缓存,缓存过期时间被设置为一年,表示缓存过期前浏览器对 react 预构建产物的请求不会再经过 Vite Dev Server,直接用缓存结果。
- 当然,除了 HTTP 缓存,Vite 还设置了本地文件系统的缓存,所有的预构建产物默认缓存在node_modules/.vite目录中。如果以下 3 个地方都没有改动,Vite 将一直使用缓存文件:
- package.json 的 dependencies 字段
- 各种包管理器的 lock 文件
- optimizeDeps 配置内容
手动开启
- 上面提到了预构建中本地文件系统的产物缓存机制,而少数场景下我们不希望用本地的缓存文件,比如需要调试某个包的预构建结果,我推荐使用下面任意一种方法清除缓存:
- 删除node_modules/.vite目录。
- 在 Vite 配置文件中,将server.force设为true。(注意,Vite 3.0 中配置项有所更新,你需要将 optimizeDeps.force 设为true)
- 命令行执行npx vite --force或者npx vite optimize。
Vite 项目的启动可以分为两步,第一步是依赖预构建,第二步才是 Dev Server 的启动,npx vite optimize相比于其它的方案,仅仅完成第一步的功能。
- 上面提到了预构建中本地文件系统的产物缓存机制,而少数场景下我们不希望用本地的缓存文件,比如需要调试某个包的预构建结果,我推荐使用下面任意一种方法清除缓存:
自定义配置详解
Vite 将预构建相关的配置项都集中在optimizeDeps属性上,我们来一一拆解这些子配置项背后的含义和应用场景。entries(入口文件)
项目第一次启动时,Vite 会默认抓取项目中所有的 HTML 文件(如当前脚手架项目中的index.html),将 HTML 文件作为应用入口,然后根据入口文件扫描出项目中用到的第三方依赖,最后对这些依赖逐个进行编译。
当默认扫描 HTML 文件的行为无法满足需求的时候,比如项目入口为vue格式文件时,你可以通过 entries 参数来配置:js// vite.config.ts { optimizeDeps: { // 为一个字符串数组 entries: ["./src/main.vue"]; } }entries 配置也支持 glob 语法,非常灵活
js// 将所有的 .vue 文件作为扫描入口 entries: ["**/*.vue"];不光是.vue文件,Vite 同时还支持各种格式的入口,包括: html、svelte、astro、js、jsx、ts和tsx。可以看到,只要可能存在import语句的地方,Vite 都可以解析,并通过内置的扫描机制搜集到项目中用到的依赖,通用性很强。
include(添加依赖)
它决定了可以强制预构建的依赖项,使用方式很简单js// vite.config.ts optimizeDeps: { // 配置为一个字符串数组,将 `lodash-es` 和 `vue`两个包强制进行预构建 include: ["lodash-es", "vue"]; }它在使用上并不难,真正难的地方在于,如何找到合适它的使用场景。前文中我们提到,Vite 会根据应用入口(entries)自动搜集依赖,然后进行预构建,这是不是说明 Vite 可以百分百准确地搜集到所有的依赖呢?事实上并不是,某些情况下 Vite 默认的扫描行为并不完全可靠,这就需要联合配置include来达到完美的预构建效果了。接下来,我们好好梳理一下到底有哪些需要配置include的场景。
场景一: 动态 import
在某些动态 import 的场景下,由于 Vite 天然按需加载的特性,经常会导致某些依赖只能在运行时被识别出来。
js// src/locales/zh_CN.js import objectAssign from "object-assign"; console.log(objectAssign); // main.tsx const importModule = (m) => import(`./locales/${m}.ts`); importModule("zh_CN");在这个例子中,动态 import 的路径只有运行时才能确定,无法在预构建阶段被扫描出来。因此在 Vite 运行时发现了新的依赖,随之重新进行依赖预构建,并刷新页面。这个过程也叫二次预构建。在一些比较复杂的项目中,这个过程会执行很多次。,如下面的日志信息所示:
[vite] new dependencies found: @material-ui/icons/Dehaze, @material-ui/core/Box, @material-ui/core/Checkbox, updating... [vite] ✨ dependencies updated, reloading page... [vite] new dependencies found: @material-ui/core/Dialog, @material-ui/core/DialogActions, updating... [vite] ✨ dependencies updated, reloading page... [vite] new dependencies found: @material-ui/core/Accordion, @material-ui/core/AccordionSummary, updating... [vite] ✨ dependencies updated, reloading page...然而,二次预构建的成本也比较大。我们不仅需要把预构建的流程重新运行一遍,还得重新刷新页面,并且需要重新请求所有的模块。尤其是在大型项目中,这个过程会严重拖慢应用的加载速度!因此,我们要尽力避免运行时的二次预构建。具体怎么做呢?你可以通过include参数提前声明需要按需加载的依赖:
js// vite.config.ts { optimizeDeps: { include: [ // 按需加载的依赖都可以声明到这个数组里 "object-assign", ]; } }场景二: 某些包被手动 exclude
exclude 是optimizeDeps中的另一个配置项,与include相对,用于将某些依赖从预构建的过程中排除。不过这个配置并不常用,也不推荐大家使用。如果真遇到了要在预构建中排除某个包的情况,需要注意它所依赖的包是否具有 ESM 格式
exclude 的包若是本身具有 ESM 格式的产物,但它的某个依赖包并没有提供 ESM 格式,就导致运行时加载失败。
这个时候可以使用 include 强制对这个间接依赖进行预构建,如下:js// vite.config.ts { optimizeDeps: { include: [ // 间接依赖的声明语法,通过`>`分开, 如`a > b`表示 a 中依赖的 b "@loadable/component > hoist-non-react-statics", ]; } }
自定义 Esbuild 行为
Vite 提供了esbuildOptions 参数来让我们自定义 Esbuild 本身的配置,常用的场景是加入一些 Esbuild 插件:
js// vite.config.ts { optimizeDeps: { esbuildOptions: { plugins: [ // 加入 Esbuild 插件 ]; } } }这个配置主要是处理一些特殊情况,如某个第三方包本身的代码出现问题了。
js// vite.config.ts const esbuildPatchPlugin = { name: "react-virtualized-patch", setup(build) { build.onLoad( { filter: /react-virtualized\/dist\/es\/WindowScroller\/utils\/onScroll.js$/, }, async (args) => { const text = await fs.promises.readFile(args.path, "utf8"); return { contents: text.replace( 'import { bpfrpt_proptype_WindowScroller } from "../WindowScroller.js";', "" ), }; } ); }, }; // 插件加入 Vite 预构建配置 { optimizeDeps: { esbuildOptions: { plugins: [esbuildPatchPlugin]; } } }
双引擎架构
Vite 架构图
很多人对 Vite 的双引擎架构仅仅停留在开发阶段使用 Esbuild,生产环境用 Rollup的阶段,殊不知,Vite 真正的架构远没有这么简单。一图胜千言,这里放一张 Vite 架构图:
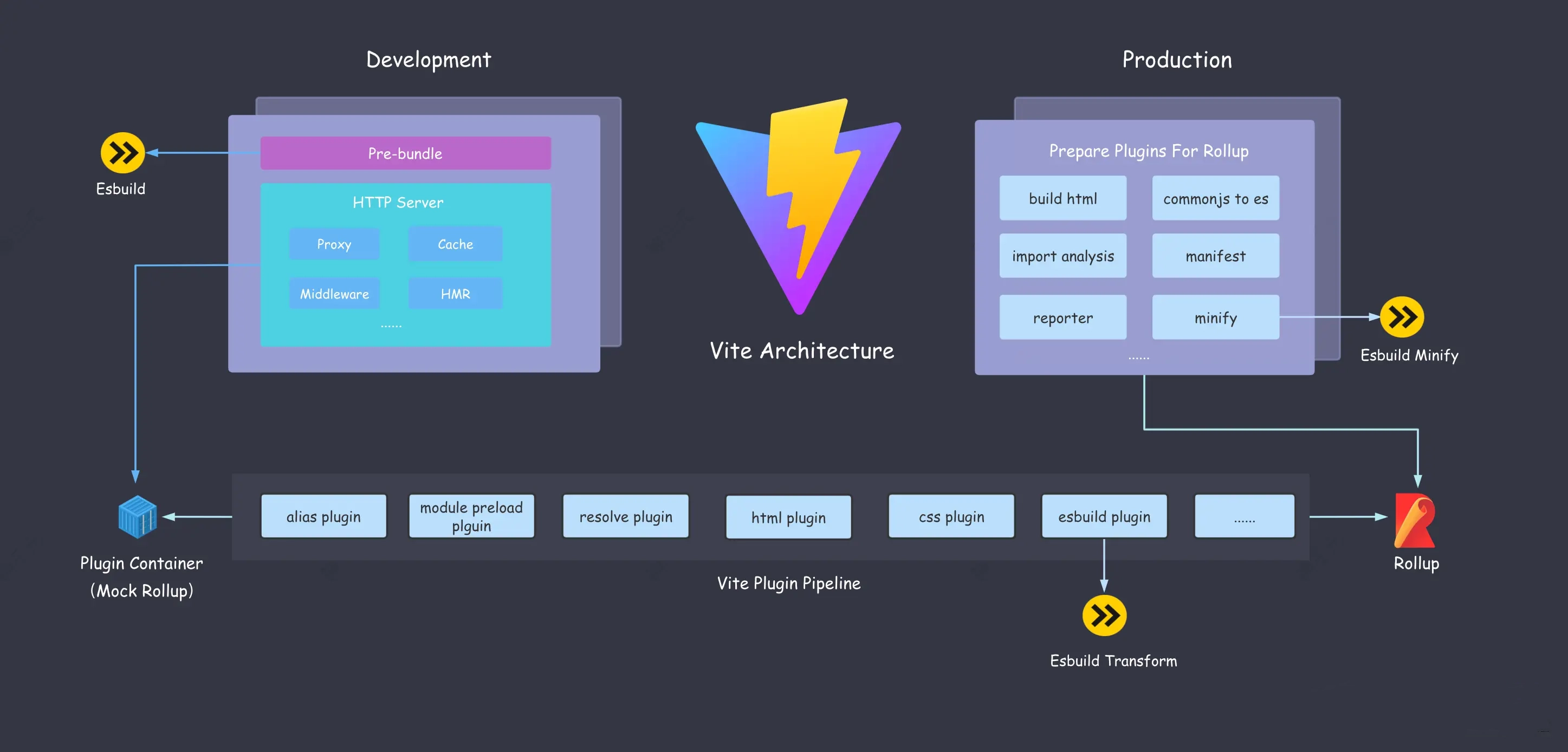
Esbuild(性能利器)
依赖预构建——作为 Bundle 工具
Esbuild是 Vite 高性能的得力助手,在很多关键的构建阶段让 Vite 获得了相当优异的性能,当然,Esbuild 作为打包工具也有一些缺点。- 不支持降级到 ES5 的代码。这意味着在低端浏览器代码会跑不起来。
- 不支持 const enum 等语法。这意味着单独使用这些语法在 esbuild 中会直接抛错。
- 不提供操作打包产物的接口,像 Rollup 中灵活处理打包产物的能力(如renderChunk钩子)在 Esbuild 当中完全没有。
- 不支持自定义 Code Splitting 策略。传统的 Webpack 和 Rollup 都提供了自定义拆包策略的 API,而 Esbuild 并未提供,从而降级了拆包优化的灵活性。
尽管 Esbuild 作为一个社区新兴的明星项目,有如此多的局限性,但依然不妨碍 Vite 在开发阶段使用它成功启动项目并获得极致的性能提升,生产环境处于稳定性考虑当然是采用功能更加丰富、生态更加成熟的 Rollup 作为依赖打包工具了。
单文件编译——作为 TS 和 JSX 编译工具
在 TS(X)/JS(X) 单文件编译上面,Vite 也使用 Esbuild 进行语法转译,也就是将 Esbuild 作为 Transformer 来用,Esbuild 转译 TS 或者 JSX 的能力通过 Vite 插件提供,这个 Vite 插件在开发环境和生产环境都会执行。
虽然 Esbuild Transfomer 能带来巨大的性能提升,但其自身也有局限性,最大的局限性就在于 TS 中的类型检查问题。这是因为 Esbuild 并没有实现 TS 的类型系统,在编译 TS(或者 TSX) 文件时仅仅抹掉了类型相关的代码,暂时没有能力实现类型检查。
vite build之前会先执行tsc命令,也就是借助 TS 官方的编译器进行类型检查。代码压缩——作为压缩工具
传统的方式都是使用 Terser 这种 JS 开发的压缩器来实现,在 Webpack 或者 Rollup 中作为一个 Plugin 来完成代码打包后的压缩混淆的工作。但 Terser 其实很慢,主要有 2 个原因。- 压缩这项工作涉及大量 AST 操作,并且在传统的构建流程中,AST 在各个工具之间无法共享,比如 Terser 就无法与 Babel 共享同一个 AST,造成了很多重复解析的过程。
- JS 本身属于解释性 + JIT(即时编译) 的语言,对于压缩这种 CPU 密集型的工作,其性能远远比不上 Golang 这种原生语言。
因此,Esbuild 这种从头到尾共享 AST 以及原生语言编写的 Minifier 在性能上能够甩开传统工具的好几十倍。
Rollup(构建基石)
Rollup 在 Vite 中的重要性一点也不亚于 Esbuild,它既是 Vite 用作生产环境打包的核心工具,也直接决定了 Vite 插件机制的设计。- 生产环境 Bundle
虽然 ESM 已经得到众多浏览器的原生支持,但生产环境做到完全no-bundle也不行,会有网络性能问题。为了在生产环境中也能取得优秀的产物性能,Vite 默认选择在生产环境中利用 Rollup 打包,并基于 Rollup 本身成熟的打包能力进行扩展和优化,主要包含 3 个方面:CSS 代码分割。如果某个异步模块中引入了一些 CSS 代码,Vite 就会自动将这些 CSS 抽取出来生成单独的文件,提高线上产物的缓存复用率。
自动预加载。Vite 会自动为入口 chunk 的依赖自动生成预加载标签 ,如:
html<head> <!-- 省略其它内容 --> <!-- 入口 chunk --> <script type="module" crossorigin src="/assets/index.250e0340.js"></script> <!-- 自动预加载入口 chunk 所依赖的 chunk--> <link rel="modulepreload" href="/assets/vendor.293dca09.js"> </head>这种适当预加载的做法会让浏览器提前下载好资源,优化页面性能。
异步 Chunk 加载优化。在异步引入的 Chunk 中,通常会有一些公用的模块,如现有两个异步引入的 Chunk: A 和 B,而且两者有一个公共依赖 C。一般情况下,Rollup 打包之后,会先请求 A,然后浏览器在加载 A 的过程中才决定请求和加载 C,但 Vite 进行优化之后,请求 A 的同时会自动预加载 C,通过优化 Rollup 产物依赖加载方式节省了不必要的网络开销。
- 兼容插件机制
无论是开发阶段还是生产环境,Vite 都根植于 Rollup 的插件机制和生态
在开发阶段,Vite 借鉴了 WMR 的思路,自己实现了一个 Plugin Container,用来模拟 Rollup 调度各个 Vite 插件的执行逻辑,而 Vite 的插件写法完全兼容 Rollup,因此在生产环境中将所有的 Vite 插件传入 Rollup 也没有问题。
反过来说,Rollup 插件却不一定能完全兼容 Vite。不过,目前仍然有不少 Rollup 插件可以直接复用到 Vite 中,你可以通过这个站点查看所有兼容 Vite 的 Rollup 插件: vite-rollup-plugins.patak.dev 。
- 生产环境 Bundle
Esbuild
Esbuild 是由 Figma 的 CTO 「Evan Wallace」基于 Golang 开发的一款打包工具,相比传统的打包工具,主打性能优势,在构建速度上可以比传统工具快 10~100 倍。那么,它是如何达到这样超高的构建性能的呢?主要原因可以概括为 4 点。
使用 Golang 开发,构建逻辑代码直接被编译为原生机器码,而不用像 JS 一样先代码解析为字节码,然后转换为机器码,大大节省了程序运行时间。
多核并行。内部打包算法充分利用多核 CPU 优势,所有的步骤尽可能并行,这也是得益于 Go 当中多线程共享内存的优势。
从零造轮子。 几乎没有使用任何第三方库,所有逻辑自己编写,大到 AST 解析,小到字符串的操作,保证极致的代码性能。
高效的内存利用。Esbuild 中从头到尾尽可能地复用一份 AST 节点数据,而不用像 JS 打包工具中频繁地解析和传递 AST 数据(如 string -> TS -> JS -> string),造成内存的大量浪费。
Esbuild 功能使用
shell# 安装 esbuild pnpm i esbuild命令行调用
shell# 安装一下所需的依赖 pnpm install react react-domjs// src/index.jsx import Server from "react-dom/server"; let Greet = () => <h1>Hello, juejin!</h1>; console.log(Server.renderToString(<Greet />));接着到package.json中添加build脚本
json{ "scripts": { "build": "./node_modules/.bin/esbuild src/index.jsx --bundle --outfile=dist/out.js" } }终端执行pnpm run build就可以完成打包工作。
代码调用
Esbuild 对外暴露了一系列的 API,主要包括两类: Build API和Transform API,我们可以在 Nodejs 代码中通过调用这些 API 来使用 Esbuild 的各种功能。项目打包——Build API
Build API主要用来进行项目打包,包括build、buildSync和serve三个方法。
首先我们来试着在 Node.js 中使用build 方法。你可以在项目根目录新建build.js文件,内容如下:tsconst { build, buildSync, serve } = require("esbuild"); async function runBuild() { // 异步方法,返回一个 Promise const result = await build({ // ---- 如下是一些常见的配置 --- // 当前项目根目录 absWorkingDir: process.cwd(), // 入口文件列表,为一个数组 entryPoints: ["./src/index.jsx"], // 打包产物目录 outdir: "dist", // 是否需要打包,一般设为 true bundle: true, // 模块格式,包括`esm`、`commonjs`和`iife` format: "esm", // 需要排除打包的依赖列表 external: [], // 是否开启自动拆包 splitting: true, // 是否生成 SourceMap 文件 sourcemap: true, // 是否生成打包的元信息文件 metafile: true, // 是否进行代码压缩 minify: false, // 是否开启 watch 模式,在 watch 模式下代码变动则会触发重新打包 watch: false, // 是否将产物写入磁盘 write: true, // Esbuild 内置了一系列的 loader,包括 base64、binary、css、dataurl、file、js(x)、ts(x)、text、json // 针对一些特殊的文件,调用不同的 loader 进行加载 loader: { '.png': 'base64', } }); console.log(result); } runBuild();执行
node build.js命令进行打包
buildSync方法的使用与build几乎相同,不过buildSync为同步执行。
并不推荐大家使用 buildSync 这种同步的 API,它们会导致两方面不良后果。一方面容易使 Esbuild 在当前线程阻塞,丧失并发任务处理的优势。另一方面,Esbuild 所有插件中都不能使用任何异步操作,这给插件开发增加了限制。
serve 有三个特点:- 开启 serve 模式后,将在指定的端口和目录上搭建一个静态文件服务,这个服务器用原生 Go 语言实现,性能比 Nodejs 更高。
- 类似 webpack-dev-server,所有的产物文件都默认不会写到磁盘,而是放在内存中,通过请求服务来访问。
- 每次请求到来时,都会进行重新构建(rebuild),永远返回新的产物。触发 rebuild 的条件并不是代码改动,而是新的请求到来。
示例:
js// build.js const { build, buildSync, serve } = require("esbuild"); function runBuild() { serve( { port: 8000, // 静态资源目录 servedir: './dist' }, { absWorkingDir: process.cwd(), entryPoints: ["./src/index.jsx"], bundle: true, format: "esm", splitting: true, sourcemap: true, ignoreAnnotations: true, metafile: true, } ).then((server) => { console.log("HTTP Server starts at port", server.port); }); } runBuild();浏览器访问localhost:8000可以看到 Esbuild 服务器返回的编译产物,后续每次在浏览器请求都会触发 Esbuild 重新构建,而每次重新构建都是一个增量构建的过程,耗时也会比首次构建少很多(一般能减少 70% 左右)。
Serve API 只适合在开发阶段使用,不适用于生产环境。
- 单文件转译——Transform API
Esbuild 还专门提供了单文件编译的能力,即Transform API,与 Build API 类似,它也包含了同步和异步的两个方法,分别是transformSync和transform。下面,我们具体使用下这些方法。jstransformSync 的用法类似,不过由于同步的 API 会使 Esbuild 丧失并发任务处理的优势(Build API的部分已经分析过),不推荐大家使用transformSync。出于性能考虑,Vite 的底层实现也是采用 transform这个异步的 API 进行 TS 及 JSX 的单文件转译的。// transform.js const { transform, transformSync } = require("esbuild"); async function runTransform() { // 第一个参数是代码字符串,第二个参数为编译配置 const content = await transform( "const isNull = (str: string): boolean => str.length > 0;", { sourcemap: true, loader: "tsx", } ); console.log(content); } runTransform();
Esbuild 插件开发
基本概念
插件开发其实就是基于原有的体系结构中进行扩展和自定义。 Esbuild 插件也不例外,通过 Esbuild 插件我们可以扩展 Esbuild 原有的路径解析、模块加载等方面的能力,并在 Esbuild 的构建过程中执行一系列自定义的逻辑。
Esbuild 插件结构被设计为一个对象,里面有name和setup两个属性,name是插件的名称,setup是一个函数,其中入参是一个 build 对象,这个对象上挂载了一些钩子可供我们自定义一些钩子函数逻辑。以下是一个简单的Esbuild插件示例:tslet envPlugin = { name: 'env', setup(build) { build.onResolve({ filter: /^env$/ }, args => ({ path: args.path, namespace: 'env-ns', })) build.onLoad({ filter: /.*/, namespace: 'env-ns' }, () => ({ contents: JSON.stringify(process.env), loader: 'json', })) }, } require('esbuild').build({ entryPoints: ['src/index.jsx'], bundle: true, outfile: 'out.js', // 应用插件 plugins: [envPlugin], }).catch(() => process.exit(1))使用插件后效果如下:
js// 应用了 env 插件后,构建时将会被替换成 process.env 对象 import { PATH } from 'env' console.log(`PATH is ${PATH}`)钩子函数的使用
onResolve 钩子 和 onLoad钩子
在 Esbuild 插件中,onResolve 和 onload是两个非常重要的钩子,分别控制路径解析和模块内容加载的过程。jsbuild.onResolve({ filter: /^env$/ }, args => ({ path: args.path, namespace: 'env-ns', })); build.onLoad({ filter: /.*/, namespace: 'env-ns' }, () => ({ contents: JSON.stringify(process.env), loader: 'json', }));可以发现这两个钩子函数中都需要传入两个参数: Options 和 Callback。
先说说Options。它是一个对象,对于onResolve 和 onload 都一样,包含filter和namespace两个属性,类型定义如下:tsinterface Options { filter: RegExp; namespace?: string; }filter 为必传参数,是一个正则表达式,它决定了要过滤出的特征文件。
namespace 为选填参数,一般在 onResolve 钩子中的回调参数返回namespace属性作为标识,我们可以在onLoad钩子中通过 namespace 将模块过滤出来。如上述插件示例就在onLoad钩子通过env-ns这个 namespace 标识过滤出了要处理的env模块。
Callback,它的类型根据不同的钩子会有所不同。相比于 Options,Callback 函数入参和返回值的结构复杂得多,涉及很多属性。
在 onResolve 钩子中函数参数和返回值梳理如下:tsbuild.onResolve({ filter: /^env$/ }, (args: onResolveArgs): onResolveResult => { // 模块路径 console.log(args.path) // 父模块路径 console.log(args.importer) // namespace 标识 console.log(args.namespace) // 基准路径 console.log(args.resolveDir) // 导入方式,如 import、require console.log(args.kind) // 额外绑定的插件数据 console.log(args.pluginData) return { // 错误信息 errors: [], // 是否需要 external external: false, // namespace 标识 namespace: 'env-ns', // 模块路径 path: args.path, // 额外绑定的插件数据 pluginData: null, // 插件名称 pluginName: 'xxx', // 设置为 false,如果模块没有被用到,模块代码将会在产物中会删除。否则不会这么做 sideEffects: false, // 添加一些路径后缀,如`?xxx` suffix: '?xxx', // 警告信息 warnings: [], // 仅仅在 Esbuild 开启 watch 模式下生效 // 告诉 Esbuild 需要额外监听哪些文件/目录的变化 watchDirs: [], watchFiles: [] } })在 onLoad 钩子中函数参数和返回值梳理如下:
tsbuild.onLoad({ filter: /.*/, namespace: 'env-ns' }, (args: OnLoadArgs): OnLoadResult => { // 模块路径 console.log(args.path); // namespace 标识 console.log(args.namespace); // 后缀信息 console.log(args.suffix); // 额外的插件数据 console.log(args.pluginData); return { // 模块具体内容 contents: '省略内容', // 错误信息 errors: [], // 指定 loader,如`js`、`ts`、`jsx`、`tsx`、`json`等等 loader: 'json', // 额外的插件数据 pluginData: null, // 插件名称 pluginName: 'xxx', // 基准路径 resolveDir: './dir', // 警告信息 warnings: [], // 同上 watchDirs: [], watchFiles: [] } })其他钩子
在 build 对象中,除了onResolve和onLoad,还有onStart和onEnd两个钩子用来在构建开启和结束时执行一些自定义的逻辑,使用上比较简单,如下面的例子所示:tslet examplePlugin = { name: 'example', setup(build) { build.onStart(() => { console.log('build started') }); build.onEnd((buildResult) => { if (buildResult.errors.length) { return; } // 构建元信息 // 获取元信息后做一些自定义的事情,比如生成 HTML console.log(buildResult.metafile) }) }, }在使用这些钩子的时候,有 2 点需要注意。
- onStart 的执行时机是在每次 build 的时候,包括触发 watch 或者 serve模式下的重新构建。
- onEnd 钩子中如果要拿到 metafile,必须将 Esbuild 的构建配置中metafile属性设为 true。
实战 1: CDN 依赖拉取插件
Esbuild 原生不支持通过 HTTP 从 CDN 服务上拉取对应的第三方依赖资源,如下代码所示:tsx// src/index.jsx // react-dom 的内容全部从 CDN 拉取 // 这段代码目前是无法运行的 import { render } from "https://cdn.skypack.dev/react-dom"; import React from 'https://cdn.skypack.dev/react' let Greet = () => <h1>Hello, juejin!</h1>; render(<Greet />, document.getElementById("root"));示例代码中我们用到了 Skypack 这个提供 npm 第三方包 ESM 产物的 CDN 服务,我们可以通过 url 访问第三方包的资源
我们需要通过 Esbuild 插件来识别这样的 url 路径,然后从网络获取模块内容并让 Esbuild 进行加载,甚至不再需要npm install安装依赖了
最简单的版本tsx// http-import-plugin.js module.exports = () => ({ name: "esbuild:http", setup(build) { let https = require("https"); let http = require("http"); // 1. 拦截 CDN 请求 build.onResolve({ filter: /^https?:\/\// }, (args) => ({ path: args.path, namespace: "http-url", })); // 2. 通过 fetch 请求加载 CDN 资源 build.onLoad({ filter: /.*/, namespace: "http-url" }, async (args) => { let contents = await new Promise((resolve, reject) => { function fetch(url) { console.log(`Downloading: ${url}`); let lib = url.startsWith("https") ? https : http; let req = lib.get(url, (res) => { if ([301, 302, 307].includes(res.statusCode)) { // 重定向 fetch(new URL(res.headers.location, url).toString()); req.abort(); } else if (res.statusCode === 200) { // 响应成功 let chunks = []; res.on("data", (chunk) => chunks.push(chunk)); res.on("end", () => resolve(Buffer.concat(chunks))); } else { reject( new Error(`GET ${url} failed: status ${res.statusCode}`) ); } }) .on("error", reject); } fetch(args.path); }); return { contents }; }); }, });然后我们新建build.js文件,内容如下:
jsconst { build } = require("esbuild"); const httpImport = require("./http-import-plugin"); async function runBuild() { build({ absWorkingDir: process.cwd(), entryPoints: ["./src/index.jsx"], outdir: "dist", bundle: true, format: "esm", splitting: true, sourcemap: true, metafile: true, plugins: [httpImport()], }).then(() => { console.log("🚀 Build Finished!"); }); } runBuild();通过node build.js执行打包脚本,发现插件不能 work,会抛出一个错误。
除了要解析 react-dom 这种直接依赖的路径,还要解析它依赖的路径,也就是间接依赖的路径。
加入这样一段onResolve钩子逻辑:js// 拦截间接依赖的路径,并重写路径 // tip: 间接依赖同样会被自动带上 `http-url`的 namespace build.onResolve({ filter: /.*/, namespace: "http-url" }, (args) => ({ // 重写路径 path: new URL(args.path, args.importer).toString(), namespace: "http-url", }));再次执行node build.js,发现依赖已经成功下载并打包
实战 2: 实现 HTML 构建插件
Esbuild 作为一个前端打包工具,本身并不具备 HTML 的构建能力。也就是说,当它把 js/css 产物打包出来的时候,并不意味着前端的项目可以直接运行了,我们还需要一份对应的入口 HTML 文件。而这份 HTML 文件当然可以手写一个,但手写显得比较麻烦,尤其是产物名称带哈希值的时候,每次打包完都要替换路径。那么,我们能不能通过 Esbuild 插件的方式来自动化地生成 HTML 呢?
在 Esbuild 插件的 onEnd 钩子中可以拿到 metafile 对象的信息。那么,这个对象究竟什么样呢?json{ "inputs": { /* 省略内容 */ }, "output": { "dist/index.js": { imports: [], exports: [], entryPoint: 'src/index.jsx', inputs: { 'http-url:https://cdn.skypack.dev/-/object-assign@v4.1.1-LbCnB3r2y2yFmhmiCfPn/dist=es2019,mode=imports/optimized/object-assign.js': { bytesInOutput: 1792 }, 'http-url:https://cdn.skypack.dev/-/react@v17.0.1-yH0aYV1FOvoIPeKBbHxg/dist=es2019,mode=imports/optimized/react.js': { bytesInOutput: 10396 }, 'http-url:https://cdn.skypack.dev/-/scheduler@v0.20.2-PAU9F1YosUNPKr7V4s0j/dist=es2019,mode=imports/optimized/scheduler.js': { bytesInOutput: 9084 }, 'http-url:https://cdn.skypack.dev/-/react-dom@v17.0.1-oZ1BXZ5opQ1DbTh7nu9r/dist=es2019,mode=imports/optimized/react-dom.js': { bytesInOutput: 183229 }, 'http-url:https://cdn.skypack.dev/react-dom': { bytesInOutput: 0 }, 'src/index.jsx': { bytesInOutput: 178 } }, bytes: 205284 }, "dist/index.js.map": { /* 省略内容 */ } } }从outputs属性中我们可以看到产物的路径,这意味着我们可以在插件中拿到所有 js 和 css 产物,然后自己组装、生成一个 HTML,实现自动化生成 HTML 的效果。
我们接着来实现一下这个插件的逻辑,首先新建html-plugin.js,内容如下:tsconst fs = require("fs/promises"); const path = require("path"); const { createScript, createLink, generateHTML } = require('./util'); module.exports = () => { return { name: "esbuild:html", setup(build) { build.onEnd(async (buildResult) => { if (buildResult.errors.length) { return; } const { metafile } = buildResult; // 1. 拿到 metafile 后获取所有的 js 和 css 产物路径 const scripts = []; const links = []; if (metafile) { const { outputs } = metafile; const assets = Object.keys(outputs); assets.forEach((asset) => { if (asset.endsWith(".js")) { scripts.push(createScript(asset)); } else if (asset.endsWith(".css")) { links.push(createLink(asset)); } }); } // 2. 拼接 HTML 内容 const templateContent = generateHTML(scripts, links); // 3. HTML 写入磁盘 const templatePath = path.join(process.cwd(), "index.html"); await fs.writeFile(templatePath, templateContent); }); }, }; } // util.js // 一些工具函数的实现 const createScript = (src) => `<script type="module" src="${src}"></script>`; const createLink = (src) => `<link rel="stylesheet" href="${src}"></link>`; const generateHTML = (scripts, links) => ` <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Esbuild App</title> ${links.join("\n")} </head> <body> <div id="root"></div> ${scripts.join("\n")} </body> </html> `; module.exports = { createLink, createScript, generateHTML };现在我们在 build.js 中引入 html 插件:
tsconst html = require("./html-plugin"); // esbuild 配置 plugins: [ // 省略其它插件 html() ]然后执行node build.js对项目进行打包,你就可以看到 index.html 已经成功输出到根目录。接着,我们通过 serve 起一个本地静态文件服务器:
shell# 1. 全局安装 serve npm i -g serve # 2. 在项目根目录执行 serve .
Rollup 基本概念及使用
Rollup 是一款基于 ES Module 模块规范实现的 JavaScript 打包工具,在前端社区中赫赫有名,同时也在 Vite 的架构体系中发挥着重要作用。不仅是 Vite 生产环境下的打包工具,其插件机制也被 Vite 所兼容,可以说是 Vite 的构建基石。因此,掌握 Rollup 也是深入学习 Vite 的必经之路。
快速上手
shell# 安装 pnpm i rollup接着新增 src/index.js 和 src/util.js 和rollup.config.js 三个文件
js// src/index.js import { add } from "./util"; console.log(add(1, 2)); // src/util.js export const add = (a, b) => a + b; export const multi = (a, b) => a * b; // rollup.config.js // 以下注释是为了能使用 VSCode 的类型提示 /** * @type { import('rollup').RollupOptions } */ const buildOptions = { input: ["src/index.js"], output: { // 产物输出目录 dir: "dist/es", // 产物格式 format: "esm", }, }; export default buildOptions;可以在package.json中加入如下的构建脚本:
json{ // rollup 打包命令,`-c` 表示使用配置文件中的配置 "build": "rollup -c" }执行
npm run build打包成功,我们可以去 dist/es 目录查看一下产物的内容:js// dist/es/index.js // 代码已经打包到一起 const add = (a, b) => a + b; console.log(add(1, 2));同时你也可以发现,util.js中的multi方法并没有被打包到产物中,这是因为 Rollup 具有天然的 Tree Shaking 功能,可以分析出未使用到的模块并自动擦除。
常用配置解读
多产物配置
打包 JavaScript 类库的场景中,我们通常需要对外暴露出不同格式的产物供他人使用,不仅包括 ESM,也需要包括诸如CommonJS、UMD等格式,保证良好的兼容性。js// rollup.config.js /** * @type { import('rollup').RollupOptions } */ const buildOptions = { input: ["src/index.js"], // 将 output 改造成一个数组 output: [ { dir: "dist/es", format: "esm", }, { dir: "dist/cjs", format: "cjs", }, ], }; export default buildOptions;从代码中可以看到,我们将output属性配置成一个数组,数组中每个元素都是一个描述对象,决定了不同产物的输出行为。
多入口配置
除了多产物配置,Rollup 中也支持多入口配置,而且通常情况下两者会被结合起来使用。接下来,就让我们继续改造之前的配置文件,将 input 设置为一个数组或者一个对象,如下所示:ts{ input: ["src/index.js", "src/util.js"] } // 或者 { input: { index: "src/index.js", util: "src/util.js" } }通过执行npm run build可以发现,所有入口的不同格式产物已经成功输出,如果不同入口对应的打包配置不一样,我们也可以默认导出一个配置数组,如下所示:
js// rollup.config.js /** * @type { import('rollup').RollupOptions } */ const buildIndexOptions = { input: ["src/index.js"], output: [ // 省略 output 配置 ], }; /** * @type { import('rollup').RollupOptions } */ const buildUtilOptions = { input: ["src/util.js"], output: [ // 省略 output 配置 ], }; export default [buildIndexOptions, buildUtilOptions];如果是比较复杂的打包场景(如 Vite 源码本身的打包),我们需要将项目的代码分成几个部分,用不同的 Rollup 配置分别打包,这种配置就很有用了。
自定义output配置
刚才我们提到了input的使用,主要用来声明入口,可以配置成字符串、数组或者对象,使用比较简单。而output与之相对,用来配置输出的相关信息,常用的配置项如下:jsoutput: { // 产物输出目录 dir: path.resolve(__dirname, 'dist'), // 以下三个配置项都可以使用这些占位符: // 1. [name]: 去除文件后缀后的文件名 // 2. [hash]: 根据文件名和文件内容生成的 hash 值 // 3. [format]: 产物模块格式,如 es、cjs // 4. [extname]: 产物后缀名(带`.`) // 入口模块的输出文件名 entryFileNames: `[name].js`, // 非入口模块(如动态 import)的输出文件名 chunkFileNames: 'chunk-[hash].js', // 静态资源文件输出文件名 assetFileNames: 'assets/[name]-[hash][extname]', // 产物输出格式,包括`amd`、`cjs`、`es`、`iife`、`umd`、`system` format: 'cjs', // 是否生成 sourcemap 文件 sourcemap: true, // 如果是打包出 iife/umd 格式,需要对外暴露出一个全局变量,通过 name 配置变量名 name: 'MyBundle', // 全局变量声明 globals: { // 项目中可以直接用`$`代替`jquery` jquery: '$' } }依赖 external
对于某些第三方包,有时候我们不想让 Rollup 进行打包,也可以通过 external 进行外部化:js{ external: ['react', 'react-dom'] }在 SSR 构建或者使用 ESM CDN 的场景中,这个配置将非常有用。
接入插件能力
Rollup 的日常使用中,我们难免会遇到一些 Rollup 本身不支持的场景,比如兼容 CommonJS 打包、注入环境变量、配置路径别名、压缩产物代码 等等。这个时候就需要我们引入相应的 Rollup 插件。
虽然 Rollup 能够打包输出出 CommonJS 格式的产物,但对于输入给 Rollup 的代码并不支持 CommonJS,仅仅支持 ESM。你可能会说,那我们直接在项目中统一使用 ESM 规范就可以了啊,这有什么问题呢?需要注意的是,我们不光要考虑项目本身的代码,还要考虑第三方依赖。目前为止,还是有不少第三方依赖只有 CommonJS 格式产物而并未提供 ESM 产物,比如项目中用到 lodash 时,打包项目会出现这样的报错:shell[!] Error: 'merge' is not exported by node_modules/-ppm/registry.npmmirror. com+Lodash@4.17.21/node_modules/Loda sh/lodash.js, imported by src/index.js https://rollupjs.org/guide/en/#error-name-is-not-exported-by-module src/index. js (6:9) 4: 5: import { add, multi } from ". /util"; 6: import { merge } from "lodash"; ^ 7: console. log (merge); 8: console. log (add (1, 2)); Error: "merge' is not exported by node_modules/ -pnpm/ reg istry.npmmirror.contlodash@4. 17-21/noce_ modula高4u2 最果 & odash. js, imported by src/index. js因此,我们需要引入额外的插件去解决这个问题。
首先需要安装两个核心的插件包:shellpnpm i @rollup/plugin-node-resolve @rollup/plugin-commonjs- @rollup/plugin-node-resolve是为了允许我们加载第三方依赖,否则像import React from 'react' 的依赖导入语句将不会被 Rollup 识别。
- @rollup/plugin-commonjs 的作用是将 CommonJS 格式的代码转换为 ESM 格式
然后让我们在配置文件中导入这些插件:js// rollup.config.js import resolve from "@rollup/plugin-node-resolve"; import commonjs from "@rollup/plugin-commonjs"; /** * @type { import('rollup').RollupOptions } */ export default { input: ["src/index.js"], output: [ { dir: "dist/es", format: "esm", }, { dir: "dist/cjs", format: "cjs", }, ], // 通过 plugins 参数添加插件 plugins: [resolve(), commonjs()], };我们以lodash这个只有 CommonJS 产物的第三方包为例测试一下:
shellpnpm i lodashjs// src/index.js import { merge } from "lodash"; console.log(merge);执行 npm run build,你可以发现产物已经正常生成了
Rollup 配置文件中,plugins除了可以与 output 配置在同一级,也可以配置在 output 参数里面,如:js// rollup.config.js import { terser } from 'rollup-plugin-terser' import resolve from "@rollup/plugin-node-resolve"; import commonjs from "@rollup/plugin-commonjs"; export default { output: { // 加入 terser 插件,用来压缩代码 plugins: [terser()] }, plugins: [resolve(), commonjs()] }需要注意的是,output.plugins中配置的插件是有一定限制的,只有使用Output 阶段相关钩子的插件才能够放到这个配置中,大家可以去这个站点查看 Rollup 的 Output 插件列表。
比较常用的 Rollup 插件库:- @rollup/plugin-json: 支持.json的加载,并配合rollup的Tree Shaking机制去掉未使用的部分,进行按需打包。
- @rollup/plugin-babel:在 Rollup 中使用 Babel 进行 JS 代码的语法转译。
- @rollup/plugin-typescript: 支持使用 TypeScript 开发。
- @rollup/plugin-alias:支持别名配置。
- @rollup/plugin-replace:在 Rollup 进行变量字符串的替换。
- rollup-plugin-visualizer: 对 Rollup 打包产物进行分析,自动生成产物体积可视化分析图。
JavaScript API 方式调用
以上我们通过Rollup的配置文件结合rollup -c完成了 Rollup 的打包过程,但有些场景下我们需要基于 Rollup 定制一些打包过程,配置文件就不够灵活了,这时候我们需要用到对应 JavaScript API 来调用 Rollup,主要分为rollup.rollup和rollup.watch两个 API
首先是 rollup.rollup,用来一次性地进行 Rollup 打包,你可以新建build.js,内容如下:js// build.js const rollup = require("rollup"); // 常用 inputOptions 配置 const inputOptions = { input: "./src/index.js", external: [], plugins:[] }; const outputOptionsList = [ // 常用 outputOptions 配置 { dir: 'dist/es', entryFileNames: `[name].[hash].js`, chunkFileNames: 'chunk-[hash].js', assetFileNames: 'assets/[name]-[hash][extname]', format: 'es', sourcemap: true, globals: { lodash: '_' } } // 省略其它的输出配置 ]; async function build() { let bundle; let buildFailed = false; try { // 1. 调用 rollup.rollup 生成 bundle 对象 bundle = await rollup.rollup(inputOptions); for (const outputOptions of outputOptionsList) { // 2. 拿到 bundle 对象,根据每一份输出配置,调用 generate 和 write 方法分别生成和写入产物 const { output } = await bundle.generate(outputOptions); await bundle.write(outputOptions); } } catch (error) { buildFailed = true; console.error(error); } if (bundle) { // 最后调用 bundle.close 方法结束打包 await bundle.close(); } process.exit(buildFailed ? 1 : 0); } build();主要的执行步骤如下:
- 通过 rollup.rollup方法,传入 inputOptions,生成 bundle 对象;
- 调用 bundle 对象的 generate 和 write 方法,传入outputOptions,分别完成产物和生成和磁盘写入。
- 调用 bundle 对象的 close 方法来结束打包。
接着你可以执行node build.js,这样,我们就可以完成了以编程的方式来调用 Rollup 打包的过程。
除了通过rollup.rollup完成一次性打包,我们也可以通过rollup.watch来完成watch模式下的打包,即每次源文件变动后自动进行重新打包。你可以新建watch.js文件,内容入下:js// watch.js const rollup = require("rollup"); const watcher = rollup.watch({ // 和 rollup 配置文件中的属性基本一致,只不过多了`watch`配置 input: "./src/index.js", output: [ { dir: "dist/es", format: "esm", }, { dir: "dist/cjs", format: "cjs", }, ], watch: { exclude: ["node_modules/**"], include: ["src/**"], }, }); // 监听 watch 各种事件 watcher.on("restart", () => { console.log("重新构建..."); }); watcher.on("change", (id) => { console.log("发生变动的模块id: ", id); }); watcher.on("event", (e) => { if (e.code === "BUNDLE_END") { console.log("打包信息:", e); } });通过执行node watch.js开启 Rollup 的 watch 打包模式,当你改动一个文件后可以看到如下的日志,说明 Rollup 自动进行了重新打包,并触发相应的事件回调函数:
js发生变动的模块id: /xxx/src/index.js 重新构建... 打包信息: { code: 'BUNDLE_END', duration: 10, input: './src/index.js', output: [ // 输出产物路径 ], result: { cache: { /* 产物具体信息 */ }, close: [AsyncFunction: close], closed: false, generate: [AsyncFunction: generate], watchFiles: [ // 监听文件列表 ], write: [AsyncFunction: write] } }基于如上的两个 JavaScript API 我们可以很方便地在代码中调用 Rollup 的打包流程,相比于配置文件有了更多的操作空间,你可以在代码中通过这些 API 对 Rollup 打包过程进行定制,甚至是二次开发。
深入理解 Rollup 的插件机制
仅仅使用 Rollup 内置的打包能力很难满足项目日益复杂的构建需求。对于一个真实的项目构建场景来说,我们还需要考虑到模块打包之外的问题,比如路径别名(alias) 、全局变量注入和代码压缩等等。
可要是把这些场景的处理逻辑与核心的打包逻辑都写到一起,一来打包器本身的代码会变得十分臃肿,二来也会对原有的核心代码产生一定的侵入性,混入很多与核心流程无关的代码,不易于后期的维护。因此 ,Rollup 设计出了一套完整的插件机制,将自身的核心逻辑与插件逻辑分离,让你能按需引入插件功能,提高了 Rollup 自身的可扩展性。
Rollup 的打包过程中,会定义一套完整的构建生命周期,从开始打包到产物输出,中途会经历一些标志性的阶段,并且在不同阶段会自动执行对应的插件钩子函数(Hook)。对 Rollup 插件来讲,最重要的部分是钩子函数,一方面它定义了插件的执行逻辑,也就是"做什么";另一方面也声明了插件的作用阶段,即"什么时候做",这与 Rollup 本身的构建生命周期息息相关。
因此,要真正理解插件的作用范围和阶段,首先需要了解 Rollup 整体的构建过程中到底做了些什么。
Rollup 整体构建阶段
在执行 rollup 命令之后,在 cli 内部的主要逻辑简化如下:js// Build 阶段 const bundle = await rollup.rollup(inputOptions); // Output 阶段 await Promise.all(outputOptions.map(bundle.write)); // 构建结束 await bundle.close();首先,Build 阶段主要负责创建模块依赖图,初始化各个模块的 AST 以及模块之间的依赖关系。下面我们用一个简单的例子来感受一下:
js// src/index.js import { a } from './module-a'; console.log(a); // src/module-a.js export const a = 1;执行如下构建脚本:
jsconst rollup = require('rollup'); const util = require('util'); async function build() { const bundle = await rollup.rollup({ input: ['./src/index.js'], }); console.log(util.inspect(bundle)); } build();可以看到这样的 bundle 对象信息:
js{ cache: { modules: [ { ast: 'AST 节点信息,具体内容省略', code: 'export const a = 1;', dependencies: [], id: '/Users/code/rollup-demo/src/data.js', // 其它属性省略 }, { ast: 'AST 节点信息,具体内容省略', code: "import { a } from './data';\n\nconsole.log(a);", dependencies: [ '/Users/code/rollup-demo/src/data.js' ], id: '/Users/code/rollup-demo/src/index.js', // 其它属性省略 } ], plugins: {} }, closed: false, // 挂载后续阶段会执行的方法 close: [AsyncFunction: close], generate: [AsyncFunction: generate], write: [AsyncFunction: write] }从上面的信息中可以看出,目前经过 Build 阶段的 bundle 对象其实并没有进行模块的打包,这个对象的作用在于存储各个模块的内容及依赖关系,同时暴露generate和write方法,以进入到后续的 Output 阶段(write和generate方法唯一的区别在于前者打包完产物会写入磁盘,而后者不会)。
所以,真正进行打包的过程会在 Output 阶段进行,即在bundle对象的 generate或者write方法中进行。还是以上面的 demo 为例,我们稍稍改动一下构建逻辑:tsconst rollup = require('rollup'); async function build() { const bundle = await rollup.rollup({ input: ['./src/index.js'], }); const result = await bundle.generate({ format: 'es', }); console.log('result:', result); } build();执行后可以得到如下的输出:
js{ output: [ { exports: [], facadeModuleId: '/Users/code/rollup-demo/src/index.js', isEntry: true, isImplicitEntry: false, type: 'chunk', code: 'const a = 1;\n\nconsole.log(a);\n', dynamicImports: [], fileName: 'index.js', // 其余属性省略 } ] }这里可以看到所有的输出信息,生成的output数组即为打包完成的结果。当然,如果使用 bundle.write 会根据配置将最后的产物写入到指定的磁盘目录中。
因此,对于一次完整的构建过程而言, Rollup 会先进入到 Build 阶段,解析各模块的内容及依赖关系,然后进入Output阶段,完成打包及输出的过程。对于不同的阶段,Rollup 插件会有不同的插件工作流程,接下来我们就来拆解一下 Rollup 插件在 Build 和 Output 两个阶段的详细工作流程。拆解插件工作流
插件的各种 Hook 可以根据这两个构建阶段分为两类: Build Hook 与 Output Hook。- Build Hook即在Build阶段执行的钩子函数,在这个阶段主要进行模块代码的转换、AST 解析以及模块依赖的解析,那么这个阶段的 Hook 对于代码的操作粒度一般为模块级别,也就是单文件级别。
- Output Hook(官方称为Output Generation Hook),则主要进行代码的打包,对于代码而言,操作粒度一般为 chunk级别(一个 chunk 通常指很多文件打包到一起的产物)。
除了根据构建阶段可以将 Rollup 插件进行分类,根据不同的 Hook 执行方式也会有不同的分类,主要包括Async、Sync、Parallel、Sequential、First这五种。在后文中我们将接触各种各样的插件 Hook,但无论哪个 Hook 都离不开这五种执行方式。
Async & Sync
两者是相对的,分别代表异步和同步的钩子函数,两者最大的区别在于同步钩子里面不能有异步逻辑,而异步钩子可以有。
Parallel
指并行的钩子函数。如果有多个插件实现了这个钩子的逻辑,一旦有钩子函数是异步逻辑,则并发执行钩子函数,不会等待当前钩子完成(底层使用 Promise.all)。
比如对于Build阶段的buildStart钩子,它的执行时机其实是在构建刚开始的时候,各个插件可以在这个钩子当中做一些状态的初始化操作,但其实插件之间的操作并不是相互依赖的,也就是可以并发执行,从而提升构建性能。反之,对于需要依赖其他插件处理结果的情况就不适合用 Parallel 钩子了,比如 transform。Sequential
指串行的钩子函数。这种 Hook 往往适用于插件间处理结果相互依赖的情况,前一个插件 Hook 的返回值作为后续插件的入参,这种情况就需要等待前一个插件执行完 Hook,获得其执行结果,然后才能进行下一个插件相应 Hook 的调用,如transform。
First
如果有多个插件实现了这个 Hook,那么 Hook 将依次运行,直到返回一个非 null 或非 undefined 的值为止。比较典型的 Hook 是 resolveId,一旦有插件的 resolveId 返回了一个路径,将停止执行后续插件的 resolveId 逻辑。
实际上不同的类型是可以叠加的,Async/Sync 可以搭配后面三种类型中的任意一种,比如一个 Hook既可以是 Async 也可以是 First 类型,接着我们将来具体分析 Rollup 当中的插件工作流程,里面会涉及到具体的一些 Hook,大家可以具体地感受一下。Build 阶段工作流
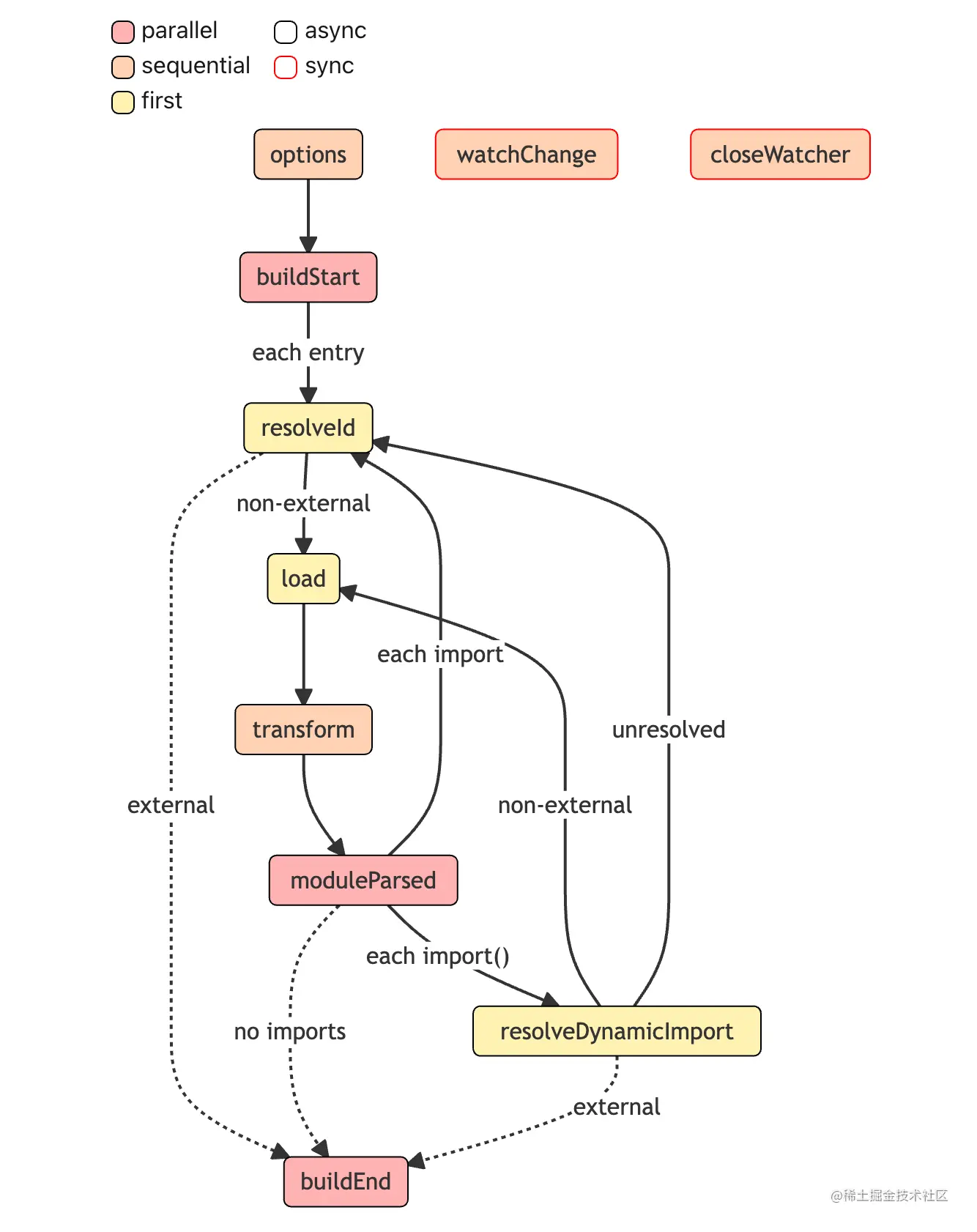
分析
Build Hooks的工作流程:首先经历 options 钩子进行配置的转换,得到处理后的配置对象。
随之
Rollup会调用buildStart钩子,正式开始构建流程。Rollup先进入到resolveId钩子中解析文件路径。(从input配置指定的入口文件开始)。Rollup通过调用load钩子加载模块内容。紧接着
Rollup执行所有的transform钩子来对模块内容进行进行自定义的转换,比如babel转译。现在
Rollup拿到最后的模块内容,进行AST分析,得到所有的import内容,调用moduleParsed钩子:- 如果是普通的
import,则执行resolveId钩子,继续回到步骤3。 - 如果是动态
import,则执行resolveDynamicImport钩子解析路径,如果解析成功,则回到步骤4加载模块,否则回到步骤3通过resolveId解析路径。
- 如果是普通的
直到所有的
import都解析完毕,Rollup执行buildEnd钩子,Build阶段结束。随后会调用
generateBundle钩子,这个钩子的入参里面会包含所有的打包产物信息,包括 chunk (打包后的代码)、asset(最终的静态资源文件)。你可以在这里删除一些chunk或者asset,最终这些内容将不会作为产物输出。前面提到了
rollup.rollup方法会返回一个bundle对象,这个对象是包含generate和write两个方法,两个方法唯一的区别在于后者会将代码写入到磁盘中,同时会触发writeBundle钩子,传入所有的打包产物信息,包括chunk和asset,和generateBundle钩子非常相似。不过值得注意的是,这个钩子执行的时候,产物已经输出了,而generateBundle执行的时候产物还并没有输出。顺序如下图所示:
当上述的
bundle的close方法被调用时,会触发closeBundle钩子,到这里Output阶段正式结束。
注意: 当打包过程中任何阶段出现错误,会触发 renderError 钩子,然后执行 closeBundle 钩子结束打包。
常用 Hook 实战
实际上开发 Rollup 插件就是在编写一个个 Hook 函数,你可以理解为一个 Rollup 插件基本就是各种 Hook 函数的组合。
路径解析: resolveId
resolveId 钩子一般用来解析模块路径,为Async + First类型即异步优先的钩子。这里我们拿官方的 alias 插件 来说明,这个插件用法演示如下:
js// rollup.config.js import alias from '@rollup/plugin-alias'; module.exports = { input: 'src/index.js', output: { dir: 'output', format: 'cjs' }, plugins: [ alias({ entries: [ // 将把 import xxx from 'module-a' // 转换为 import xxx from './module-a' { find: 'module-a', replacement: './module-a.js' }, ] }) ] };插件的代码简化后如下:
jsexport default alias(options) { // 获取 entries 配置 const entries = getEntries(options); return { // 传入三个参数,当前模块路径、引用当前模块的模块路径、其余参数 resolveId(importee, importer, resolveOptions) { // 先检查能不能匹配别名规则 const matchedEntry = entries.find((entry) => matches(entry.find, importee)); // 如果不能匹配替换规则,或者当前模块是入口模块,则不会继续后面的别名替换流程 if (!matchedEntry || !importerId) { // return null 后,当前的模块路径会交给下一个插件处理 return null; } // 正式替换路径 const updatedId = normalizeId( importee.replace(matchedEntry.find, matchedEntry.replacement) ); // 每个插件执行时都会绑定一个上下文对象作为 this // 这里的 this.resolve 会执行所有插件(除当前插件外)的 resolveId 钩子 return this.resolve( updatedId, importer, Object.assign({ skipSelf: true }, resolveOptions) ).then((resolved) => { // 替换后的路径即 updateId 会经过别的插件进行处理 let finalResult: PartialResolvedId | null = resolved; if (!finalResult) { // 如果其它插件没有处理这个路径,则直接返回 updateId finalResult = { id: updatedId }; } return finalResult; }); } } }从这里你可以看到
resolveId钩子函数的一些常用使用方式,它的入参分别是当前模块路径、引用当前模块的模块路径、解析参数,返回值可以是 null、string 或者一个对象,我们分情况讨论。- 返回值为
null时,会默认交给下一个插件的resolveId钩子处理。 - 返回值为
string时,则停止后续插件的处理。这里为了让替换后的路径能被其他插件处理,特意调用了this.resolve来交给其它插件处理,否则将不会进入到其它插件的处理。 - 返回值为一个对象,也会停止后续插件的处理,不过这个对象就可以包含更多的信息了,包括解析后的路径、是否被 external、是否需要
tree-shaking等等,不过大部分情况下返回一个 string 就够用了。
- 返回值为
load
load
为Async + First类型,即异步优先的钩子,和resolveId类似。它的作用是通过resolveId解析后的路径来加载模块内容。这里,我们以官方的 image 插件 为例来介绍一下 load 钩子的使用。源码简化后如下所示:jsconst mimeTypes = { '.jpg': 'image/jpeg', // 后面图片类型省略 }; export default function image(opts = {}) { const options = Object.assign({}, defaults, opts); return { name: 'image', load(id) { const mime = mimeTypes[extname(id)]; if (!mime) { // 如果不是图片类型,返回 null,交给下一个插件处理 return null; } // 加载图片具体内容 const isSvg = mime === mimeTypes['.svg']; const format = isSvg ? 'utf-8' : 'base64'; const source = readFileSync(id, format).replace(/[\r\n]+/gm, ''); const dataUri = getDataUri({ format, isSvg, mime, source }); const code = options.dom ? domTemplate({ dataUri }) : constTemplate({ dataUri }); return code.trim(); } }; }从中可以看到,load 钩子的入参是模块 id,返回值一般是 null、string 或者一个对象:
- 如果返回值为 null,则交给下一个插件处理;
- 如果返回值为 string 或者对象,则终止后续插件的处理,如果是对象可以包含 SourceMap、AST 等更详细的信息。
代码转换: transform
transform钩子也是非常常见的一个钩子函数,为Async + Sequential类型,也就是异步串行钩子,作用是对加载后的模块内容进行自定义的转换。我们以官方的replace插件为例,这个插件的使用方式如下:ts// rollup.config.js import replace from '@rollup/plugin-replace'; module.exports = { input: 'src/index.js', output: { dir: 'output', format: 'cjs' }, plugins: [ // 将会把代码中所有的 __TEST__ 替换为 1 replace({ __TEST__: 1 }) ] };内部实现也并不复杂,主要通过字符串替换来实现,核心逻辑简化如下:
tsimport MagicString from 'magic-string'; export default function replace(options = {}) { return { name: 'replace', transform(code, id) { // 省略一些边界情况的处理 // 执行代码替换的逻辑,并生成最后的代码和 SourceMap return executeReplacement(code, id); } } } function executeReplacement(code, id) { const magicString = new MagicString(code); // 通过 magicString.overwrite 方法实现字符串替换 if (!codeHasReplacements(code, id, magicString)) { return null; } const result = { code: magicString.toString() }; if (isSourceMapEnabled()) { result.map = magicString.generateMap({ hires: true }); } // 返回一个带有 code 和 map 属性的对象 return result; }transform 钩子的入参分别为
模块代码、模块 ID,返回一个包含code(代码内容) 和map(SourceMap 内容) 属性的对象,当然也可以返回null来跳过当前插件的transform处理。需要注意的是,当前插件返回的代码会作为下一个插件 transform 钩子的第一个入参,实现类似于瀑布流的处理。Chunk 级代码修改: renderChunk
这里我们继续以 replace插件举例,在这个插件中,也同样实现了 renderChunk 钩子函数:
tsexport default function replace(options = {}) { return { name: 'replace', transform(code, id) { // transform 代码省略 }, renderChunk(code, chunk) { const id = chunk.fileName; // 省略一些边界情况的处理 // 拿到 chunk 的代码及文件名,执行替换逻辑 return executeReplacement(code, id); }, } }可以看到这里
replace插件为了替换结果更加准确,在renderChunk钩子中又进行了一次替换,因为后续的插件仍然可能在transform中进行模块内容转换,进而可能出现符合替换规则的字符串。
这里我们把关注点放到renderChunk函数本身,可以看到有两个入参,分别为chunk 代码内容、chunk 元信息,返回值跟transform钩子类似,既可以返回包含 code 和 map 属性的对象,也可以通过返回 null 来跳过当前钩子的处理。产物生成最后一步: generateBundle
generateBundle 也是异步串行的钩子,你可以在这个钩子里面自定义删除一些无用的 chunk 或者静态资源,或者自己添加一些文件。这里我们以 Rollup 官方的
html 插件来具体说明,这个插件的作用是通过拿到 Rollup 打包后的资源来生成包含这些资源的 HTML 文件,源码简化后如下所示:tsexport default function html(opts: RollupHtmlOptions = {}): Plugin { // 初始化配置 return { name: 'html', async generateBundle(output: NormalizedOutputOptions, bundle: OutputBundle) { // 省略一些边界情况的处理 // 1. 获取打包后的文件 const files = getFiles(bundle); // 2. 组装 HTML,插入相应 meta、link 和 script 标签 const source = await template({ attributes, bundle, files, meta, publicPath, title}); // 3. 通过上下文对象的 emitFile 方法,输出 html 文件 const htmlFile: EmittedAsset = { type: 'asset', source, name: 'Rollup HTML Asset', fileName }; this.emitFile(htmlFile); } } }相信从插件的具体实现中,你也能感受到这个钩子的强大作用了。入参分别为
output 配置、所有打包产物的元信息对象,通过操作元信息对象你可以删除一些不需要的 chunk 或者静态资源,也可以通过 插件上下文对象的emitFile 方法输出自定义文件。
Vite 高级应用
虽然 Vite 的插件机制是基于 Rollup 来设计的,并且前面我们也已经对 Rollup 的插件机制进行了详细的解读,但实际上 Vite 的插件机制也包含了自己独有的一部分,与 Rollup 的各个插件 Hook 并非完全兼容,因此本节我们将重点关注 Vite 独有的部分以及和 Rollup 所区别的部分。
简单的插件示例
Vite 插件与 Rollup 插件结构类似,为一个name和各种插件 Hook 的对象:
ts{ // 插件名称 name: 'vite-plugin-xxx', load(code) { // 钩子逻辑 }, }如果插件是一个 npm 包,在package.json中的包命名也推荐以vite-plugin开头
一般情况下因为要考虑到外部传参,我们不会直接写一个对象,而是实现一个返回插件对象的工厂函数,如下代码所示:
ts// myPlugin.js export function myVitePlugin(options) { console.log(options) return { name: 'vite-plugin-xxx', load(id) { // 在钩子逻辑中可以通过闭包访问外部的 options 传参 } } } // 使用方式 // vite.config.ts import { myVitePlugin } from './myVitePlugin'; export default { plugins: [myVitePlugin({ /* 给插件传参 */ })] }插件 Hook 介绍
通用 Hook
Vite 开发阶段会模拟 Rollup 的行为,其中 Vite 会调用一系列与 Rollup 兼容的钩子,这个钩子主要分为三个阶段:
- 服务器启动阶段: options和buildStart钩子会在服务启动时被调用。
- 请求响应阶段: 当浏览器发起请求时,Vite 内部依次调用resolveId、load和transform钩子。
- 服务器关闭阶段: Vite 会依次执行buildEnd和closeBundle钩子。
除了以上钩子,其他 Rollup 插件钩子(如moduleParsed、renderChunk)均不会在 Vite 开发阶段调用。而生产环境下,由于 Vite 直接使用 Rollup,Vite 插件中所有 Rollup 的插件钩子都会生效。
独有 Hook
Vite 中特有的一些 Hook,这些 Hook 只会在 Vite 内部调用,而放到 Rollup 中会被直接忽略。
给配置再加点料:config
Vite 在读取完配置文件(即vite.config.ts)之后,会拿到用户导出的配置对象,然后执行 config 钩子。在这个钩子里面,你可以对配置文件导出的对象进行自定义的操作,如下代码所示:
ts// 返回部分配置(推荐) const editConfigPlugin = () => ({ name: 'vite-plugin-modify-config', config: () => ({ alias: { react: require.resolve('react') } }) })官方推荐的姿势是在 config 钩子中返回一个配置对象,这个配置对象会和 Vite 已有的配置进行深度的合并。不过你也可以通过钩子的入参拿到 config 对象进行自定义的修改,如下代码所示:
tsconst mutateConfigPlugin = () => ({ name: 'mutate-config', // command 为 `serve`(开发环境) 或者 `build`(生产环境) config(config, { command }) { // 生产环境中修改 root 参数 if (command === 'build') { config.root = __dirname; } } })在一些比较深层的对象配置中,这种直接修改配置的方式会显得比较麻烦,如 optimizeDeps.esbuildOptions.plugins,需要写很多的样板代码,类似下面这样:
ts// 防止出现 undefined 的情况 config.optimizeDeps = config.optimizeDeps || {} config.optimizeDeps.esbuildOptions = config.optimizeDeps.esbuildOptions || {} config.optimizeDeps.esbuildOptions.plugins = config.optimizeDeps.esbuildOptions.plugins || []因此这种情况下,建议直接返回一个配置对象,这样会方便很多:
tsconfig() { return { optimizeDeps: { esbuildOptions: { plugins: [] } } } }记录最终配置:configResolved
Vite 在解析完配置之后会调用configResolved钩子,这个钩子一般用来记录最终的配置信息,而不建议再修改配置,用法如下图所示:
tsconst exmaplePlugin = () => { let config return { name: 'read-config', configResolved(resolvedConfig) { // 记录最终配置 config = resolvedConfig }, // 在其他钩子中可以访问到配置 transform(code, id) { console.log(config) } } }获取 Dev Server 实例: configureServer
这个钩子仅在开发阶段会被调用,用于扩展 Vite 的 Dev Server,一般用于增加自定义 server 中间件,如下代码所示:
tsconst myPlugin = () => ({ name: 'configure-server', configureServer(server) { // 姿势 1: 在 Vite 内置中间件之前执行 server.middlewares.use((req, res, next) => { // 自定义请求处理逻辑 }) // 姿势 2: 在 Vite 内置中间件之后执行 return () => { server.middlewares.use((req, res, next) => { // 自定义请求处理逻辑 }) } } })转换 HTML 内容: transformIndexHtml
这个钩子用来灵活控制 HTML 的内容,你可以拿到原始的 html 内容后进行任意的转换:
tsconst htmlPlugin1 = () => { return { name: 'html-transform', transformIndexHtml(html) { return html.replace( /<title>(.*?)</title>/, `<title>换了个标题</title>` ) } } } // 也可以返回如下的对象结构,一般用于添加某些标签 const htmlPlugin2 = () => { return { name: 'html-transform', transformIndexHtml(html) { return { html, // 注入标签 tags: [ { // 放到 body 末尾,可取值还有`head`|`head-prepend`|`body-prepend`,顾名思义 injectTo: 'body', // 标签属性定义 attrs: { type: 'module', src: './index.ts' }, // 标签名 tag: 'script', }, ], } } } }热更新处理: handleHotUpdate
这个钩子会在 Vite 服务端处理热更新时被调用,你可以在这个钩子中拿到热更新相关的上下文信息,进行热更模块的过滤,或者进行自定义的热更处理。下面是一个简单的例子:
tsconst handleHmrPlugin = () => { return { async handleHotUpdate(ctx) { // 需要热更的文件 console.log(ctx.file) // 需要热更的模块,如一个 Vue 单文件会涉及多个模块 console.log(ctx.modules) // 时间戳 console.log(ctx.timestamp) // Vite Dev Server 实例 console.log(ctx.server) // 读取最新的文件内容 console.log(await read()) // 自行处理 HMR 事件 ctx.server.ws.send({ type: 'custom', event: 'special-update', data: { a: 1 } }) return [] } } } // 前端代码中加入 if (import.meta.hot) { import.meta.hot.on('special-update', (data) => { // 执行自定义更新 // { a: 1 } console.log(data) window.location.reload(); }) }
以上就是 Vite 独有的五个钩子,我们来重新梳理一下:- config: 用来进一步修改配置。
- configResolved: 用来记录最终的配置信息。
- configureServer: 用来获取 Vite Dev Server 实例,添加中间件。
- transformIndexHtml: 用来转换 HTML 的内容。
- handleHotUpdate: 用来进行热更新模块的过滤,或者进行自定义的热更新处理。
插件 Hook 执行顺序
下面我们来复盘一下上述的两类钩子,并且通过一个具体的代码示例来汇总一下所有的钩子:
ts// test-hooks-plugin.ts // 注: 请求响应阶段的钩子 // 如 resolveId, load, transform, transformIndexHtml在下文介绍 // 以下为服务启动和关闭的钩子 export default function testHookPlugin () { return { name: 'test-hooks-plugin', // Vite 独有钩子 config(config) { console.log('config'); }, // Vite 独有钩子 configResolved(resolvedCofnig) { console.log('configResolved'); }, // 通用钩子 options(opts) { console.log('options'); return opts; }, // Vite 独有钩子 configureServer(server) { console.log('configureServer'); setTimeout(() => { // 手动退出进程 process.kill(process.pid, 'SIGTERM'); }, 3000) }, // 通用钩子 buildStart() { console.log('buildStart'); }, // 通用钩子 buildEnd() { console.log('buildEnd'); }, // 通用钩子 closeBundle() { console.log('closeBundle'); } } }将插件加入到 Vite 配置文件中,然后启动,你可以观察到各个
Hook的执行顺序:- 服务启动阶段:
config、configResolved、options、configureServer、buildStart - 请求响应阶段: 如果是
html文件,仅执行transformIndexHtml钩子;对于非HTML文件,则依次执行resolveId、load和transform钩子。 - 热更新阶段: 执行
handleHotUpdate钩子。 - 服务关闭阶段: 依次执行
buildEnd和closeBundle钩子。
- 服务启动阶段:
插件应用位置
默认情况下 Vite 插件同时被用于开发环境和生产环境,你可以通过
apply属性来决定应用场景:ts{ // 'serve' 表示仅用于开发环境,'build'表示仅用于生产环境 apply: 'serve' }apply参数还可以配置成一个函数,进行更灵活的控制:tsapply(config, { command }) { // 只用于非 SSR 情况下的生产环境构建 return command === 'build' && !config.build.ssr }也可以通过enforce属性来指定插件的执行顺序:
ts{ // 默认为`normal`,可取值还有`pre`和`post` enforce: 'pre' }Vite 会依次执行如下的插件(⭐️表示用户插件):
- Alias (路径别名)相关的插件。
- ⭐️ 带有
enforce: 'pre'的用户插件。 - Vite 核心插件。
- ⭐️ 没有
enforce值的用户插件,也叫普通插件。 - Vite 生产环境构建用的插件。
- ⭐️ 带有
enforce: 'post'的用户插件。 - Vite 后置构建插件(如压缩插件)。
插件开发实战
虚拟模块加载
作为构建工具,一般需要处理两种形式的模块,一种存在于真实的磁盘文件系统中,另一种并不在磁盘而在内存当中,也就是虚拟模块。通过虚拟模块,我们既可以把自己手写的一些代码字符串作为单独的模块内容,又可以将内存中某些经过计算得出的变量作为模块内容进行加载,非常灵活和方便。
shell# 初始化一个 react + ts 项目 npm init vite通过pnpm i安装依赖,接着新建plugins目录,开始插件的开发:
ts// plugins/virtual-module.ts import { Plugin } from 'vite'; // 虚拟模块名称 const virtualFibModuleId = 'virtual:fib'; // Vite 中约定对于虚拟模块,解析后的路径需要加上`\0`前缀 const resolvedFibVirtualModuleId = '\0' + virtualFibModuleId; export default function virtualFibModulePlugin(): Plugin { let config: ResolvedConfig | null = null; return { name: 'vite-plugin-virtual-module', resolveId(id) { if (id === virtualFibModuleId) { return resolvedFibVirtualModuleId; } }, load(id) { // 加载虚拟模块 if (id === resolvedFibVirtualModuleId) { return 'export default function fib(n) { return n <= 1 ? n : fib(n - 1) + fib(n - 2); }'; } } } }在项目中来使用这个插件:
ts// vite.config.ts import virtual from './plugins/virtual-module.ts' // 配置插件 { plugins: [react(), virtual()] }然后在main.tsx中加入如下的代码:
tsimport fib from 'virtual:fib'; alert(`结果: ${fib(10)}`)这里我们使用了
virtual:fib这个虚拟模块,虽然这个模块不存在真实的文件系统中,但你打开浏览器后可以发现这个模块导出的函数是可以正常执行的。
通过虚拟模块来读取内存中的变量,在virtual-module.ts中增加如下代码:diffimport { Plugin, ResolvedConfig } from 'vite'; const virtualFibModuleId = 'virtual:fib'; const resolvedFibVirtualModuleId = '\0' + virtualFibModuleId; + const virtualEnvModuleId = 'virtual:env'; + const resolvedEnvVirtualModuleId = '\0' + virtualEnvModuleId; export default function virtualFibModulePlugin(): Plugin { + let config: ResolvedConfig | null = null; return { name: 'vite-plugin-virtual-fib-module', + configResolved(c: ResolvedConfig) { + config = c; + }, resolveId(id) { if (id === virtualFibModuleId) { return resolvedFibVirtualModuleId; } + if (id === virtualEnvModuleId) { + return resolvedEnvVirtualModuleId; + } }, load(id) { if (id === resolvedFibVirtualModuleId) { return 'export default function fib(n) { return n <= 1 ? n : fib(n - 1) + fib(n - 2); }'; } + if (id === resolvedEnvVirtualModuleId) { + return `export default ${JSON.stringify(config!.env)}`; + } } } }在新增的这些代码中,我们注册了一个新的虚拟模块
virtual:env,紧接着我们去项目去使用:ts// main.tsx import env from 'virtual:env'; console.log(env)virtual:env一般情况下会有类型问题,我们需要增加一个类型声明文件来声明这个模块:ts// types/shim.d.ts declare module 'virtual:*' { export default any; }浏览器观察一下输出的情况:
js{ BASE_URL: "/", DEV: true, MODE: "development", PROD: false }Vite 环境变量能正确地在浏览器中打印出来,说明在内存中计算出来的
virtual:env模块的确被成功地加载了。社区当中也有不少知名的插件(如vite-plugin-windicss、vite-plugin-svg-icons等)也使用了虚拟模块的技术。Svg 组件形式加载
在一般的项目开发过程中,我们有时候希望能将 svg 当做一个组件来引入,这样我们可以很方便地修改 svg 的各种属性,相比于img标签的引入方式也更加优雅。但 Vite 本身并不支持将 svg 转换为组件的代码,需要我们通过插件来实现。
shell# 安装依赖 pnpm i resolve @svgr/core -D在
plugins目录新建svgr.ts:tsimport { Plugin } from 'vite'; import * as fs from 'fs'; import * as resolve from 'resolve'; interface SvgrOptions { // svg 资源模块默认导出,url 或者组件 defaultExport: 'url' | 'component'; } export default function viteSvgrPlugin(options: SvgrOptions) { const { defaultExport='url' } = options; return { name: 'vite-plugin-svgr', async transform(code ,id) { // 转换逻辑: svg -> React 组件 } } }先来梳理一下开发需求,用户通过传入
defaultExport可以控制 svg 资源的默认导出:当
defaultExport为component,默认当做组件来使用,即:tsximport Logo from './Logo.svg'; // 在组件中直接使用 <Logo />当
defaultExports为 url,默认当做 url 使用,如果需要用作组件,可以通过具名导入的方式来支持:tsximport logoUrl, { ReactComponent as Logo } from './logo.svg'; // url 使用 <img src={logoUrl} /> // 组件方式使用 <Logo />
接下来整理一下插件开发的整体思路,主要逻辑在
transform钩子中完成,流程如下:- 根据
id入参过滤出svg资源; - 读取
svg文件内容; - 利用
@svgr/core将svg转换为React组件代码; - 处理默认导出为
url的情况; - 将组件的
jsx代码转译为浏览器可运行的代码。
完整的代码如下:
tsimport { Plugin } from 'vite'; import * as fs from 'fs'; import * as resolve from 'resolve'; interface SvgrOptions { defaultExport: 'url' | 'component'; } export default function viteSvgrPlugin(options: SvgrOptions): Plugin { const { defaultExport='component' } = options; return { name: 'vite-plugin-svgr', async transform(code, id) { // 1. 根据 id 入参过滤出 svg 资源; if (!id.endsWith('.svg')) { return code; } const svgrTransform = require('@svgr/core').transform; // 解析 esbuild 的路径,后续转译 jsx 会用到,我们这里直接拿 vite 中的 esbuild 即可 const esbuildPackagePath = resolve.sync('esbuild', { basedir: require.resolve('vite') }); const esbuild = require(esbuildPackagePath); // 2. 读取 svg 文件内容; const svg = await fs.promises.readFile(id, 'utf8'); // 3. 利用 `@svgr/core` 将 svg 转换为 React 组件代码 const svgrResult = await svgrTransform( svg, {}, { componentName: 'ReactComponent' } ); // 4. 处理默认导出为 url 的情况 let componentCode = svgrResult; if (defaultExport === 'url') { // 加上 Vite 默认的 `export default 资源路径` componentCode += code; componentCode = componentCode.replace('export default ReactComponent', 'export { ReactComponent }'); } // 5. 利用 esbuild,将组件中的 jsx 代码转译为浏览器可运行的代码; const result = await esbuild.transform(componentCode, { loader: 'jsx', }); return { code: result.code, map: null // TODO }; }, }; }在
vite.config.ts中引入插件:ts// vite.config.ts import svgr from './plugins/svgr'; // 返回的配置 { plugins: [ // 省略其它插件 svgr() ] }项目中用组件的方式引入
svg:tsx// App.tsx import Logo from './logo.svg' function App() { return ( <> <Logo /> </> ) } export default App;打开浏览器,查看组件是否正常显示
调试技巧
本地装上vite-plugin-inspect插件:
ts// vite.config.ts import inspect from 'vite-plugin-inspect'; // 返回的配置 { plugins: [ // 省略其它插件 inspect() ] }再次启动项目时,会多出一个调试地址,通过这个地址来查看项目中各个模块的编译结果。
HMR
HMR 的全称叫做Hot Module Replacement,即模块热替换或者模块热更新。在计算机领域当中也有一个类似的概念叫热插拔,我们经常使用的 USB 设备就是一个典型的代表,当我们插入 U 盘的时候,系统驱动会加载在新增的 U 盘内容,不会重启系统,也不会修改系统其它模块的内容。HMR 的作用其实一样,就是在页面模块更新的时候,直接把页面中发生变化的模块替换为新的模块,同时不会影响其它模块的正常运作。
深入 HMR API
Vite 作为一个完整的构建工具,本身实现了一套 HMR 系统,值得注意的是,这套 HMR 系统基于原生的 ESM 模块规范来实现,在文件发生改变时 Vite 会侦测到相应 ES 模块的变化,从而触发相应的 API,实现局部的更新。
HMR API 的类型定义:
tsinterface ImportMeta { readonly hot?: { readonly data: any accept(): void accept(cb: (mod: any) => void): void accept(dep: string, cb: (mod: any) => void): void accept(deps: string[], cb: (mods: any[]) => void): void prune(cb: () => void): void dispose(cb: (data: any) => void): void decline(): void invalidate(): void on(event: string, cb: (...args: any[]) => void): void } }i
mport.meta 对象为现代浏览器原生的一个内置对象,Vite 所做的事情就是在这个对象上的 hot 属性中定义了一套完整的属性和方法。因此,在 Vite 当中,你就可以通过i来访问关于 HMR 的这些属性和方法,比如mport.meta.hot i。mport.meta.hot.accept() 模块更新时逻辑: hot.accept
i对象上有一个非常关键的方法mport.meta.hot accept,因为它决定了 Vite 进行热更新的边界。它就是用来接受模块更新的。 一旦 Vite 接受了这个更新,当前模块就会被认为是 HMR 的边界。那么,Vite 接受谁的更新呢?这里会有三种情况:- 接受自身模块的更新
- 接受某个子模块的更新
- 接受多个子模块的更新
1. 接受自身更新
当模块接受自身的更新时,则当前模块会被认为 HMR 的边界。也就是说,除了当前模块,其他的模块均未受到任何影响。示例如下:
html<!-- index.html --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <link rel="icon" type="image/svg+xml" href="favicon.svg" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Vite App</title> </head> <body> <div id="app"></div> <p> count: <span id="count">0</span> </p> <script type="module" src="/src/main.ts"></script> </body> </html>ts// src/main.ts import { render } from './render'; import { initState } from './state'; render(); initState();ts// src/render.ts // 负责渲染文本内容 import './style.css' export const render = () => { const app = document.querySelector<HTMLDivElement>('#app')! app.innerHTML = ` <h1>Hello Vite!</h1> <p target="_blank">This is hmr test.123</p> ` } // src/state.ts // 负责记录当前的页面状态 export function initState() { let count = 0; setInterval(() => { let countEle = document.getElementById('count'); countEle!.innerText = ++count + ''; }, 1000); }执行
pnpm i安装依赖,然后npm run dev启动项目,在浏览器中查看,每隔一秒钟,你可以看到这里的count值会加 1。
下面改动一下 render.ts 的渲染内容:ts// render.ts export const render = () => { const app = document.querySelector<HTMLDivElement>('#app')! app.innerHTML = ` <h1>Hello Vite!</h1> <p target="_blank">This is hmr test.123 这是增加的文本</p> ` }页面的渲染内容更新了,但count值瞬间被置零了,并且查看控制台,也有这样的 log:
shell[vite] page reload src/render.ts很明显,当 render.ts 模块发生变更时,Vite 发现并没有 HMR 相关的处理,然后直接刷新页面了。现在让我们在render.ts中加上如下的代码:
ts// 条件守卫 if (import.meta.hot) { import.meta.hot.accept((mod) => mod.render()) }i对象只有在开发阶段才会被注入到全局,生产环境是访问不到的,另外增加条件守卫之后,打包时识别到 if 条件不成立,会自动把这部分代码从打包产物中移除,来优化资源体积。因此,我们需要增加这个条件守卫语句。mport.meta.hot i中传入了一个回调函数作为参数,入参即为 Vite 给我们提供的更新后的模块内容,在浏览器中打印mod内容如下,正好是render模块最新的内容。mport.meta.hot.accept
回调中调用了一下mod.render方法,也就是当模块变动后,每次都重新渲染一遍内容。这时你可以试着改动一下渲染的内容,然后到浏览器中注意一下count的情况,并没有被重新置零,而是保留了原有的状态。
现在 render 模块更新后,只会重新渲染这个模块的内容,而对于 state 模块的内容并没有影响,并且控制台的 log 也发生了变化:shell[vite] hmr update /src/render.ts现在我们算是实现了初步的 HMR,也在实际的代码中体会到了 accept 方法的用途。当然,在这个例子中我们传入了一个回调函数来手动调用
render逻辑,但事实上你也可以什么参数都不传,这样 Vite 只会把render模块的最新内容执行一遍,但 render 模块内部只声明了一个函数,因此直接调用i并不会重新渲染页面。mport.meta.hot.accept()
2. 接受依赖模块的更新举例: main模块依赖render 模块,也就是说,main模块是render父模块,那么我们也可以在 main 模块中接受render模块的更新,此时 HMR 边界就是main模块了。
diff// 移除 render.ts 中 accept 相关代码 - if (import.meta.hot) { - import.meta.hot.accept((mod) => mod.render()) - }diff// main.ts 中添加以下代码 import { render } from './render'; import './state'; render(); +if (import.meta.hot) { + import.meta.hot.accept('./render.ts', (newModule) => { + newModule.render(); + }) +}在这里我们同样是调用
accept方法,与之前不同的是,第一个参数传入一个依赖的路径,也就是render模块的路径,这就相当于告诉 Vite: 我监听了 render 模块的更新,当它的内容更新的时候,请把最新的内容传给我。同样的,第二个参数中定义了模块变化后的回调函数,这里拿到了 render 模块最新的内容,然后执行其中的渲染逻辑,让页面展示最新的内容。通过接受一个依赖模块的更新,我们同样又实现了
HMR功能,你可以试着改动 render模块的内容,可以发现页面内容正常更新,并且状态依然保持着原样。
3. 接受多个子模块的更新父模块可以接受多个子模块的更新,当其中任何一个子模块更新之后,父模块会成为 HMR 边界。示例:
diff// 更改 main.ts 代码 import { render } from './render'; import { initState } from './state'; render(); initState(); +if (import.meta.hot) { + import.meta.hot.accept(['./render.ts', './state.ts'], (modules) => { + console.log(modules); + }) +}在代码中我们通过
accept方法接受了render和state两个模块的更新,接着让我们手动改动一下某一个模块的代码,观察一下回调中modules的打印内容。可以看到 Vite 给我们的回调传来的参数
modules其实是一个数组,和我们第一个参数声明的子模块数组一一对应。因此modules数组第一个元素是undefined,表示render模块并没有发生变化,第二个元素为一个Module对象,也就是经过变动后state模块的最新内容。于是在这里,我们根据modules进行自定义的更新,修改 main.ts:ts// main.ts import { render } from './render'; import { initState } from './state'; render(); initState(); if (import.meta.hot) { import.meta.hot.accept(['./render.ts', './state.ts'], (modules) => { // 自定义更新 const [renderModule, stateModule] = modules; if (renderModule) { renderModule.render(); } if (stateModule) { stateModule.initState(); } }) }现在,你可以改动两个模块的内容,可以发现,页面的相应模块会更新,并且对其它的模块没有影响。但实际上你会发现另外一个问题,当改动了state模块的内容之后,页面的内容会变得错乱。
我们快速回顾一下
state模块的内容:ts// state.ts export function initState() { let count = 0; setInterval(() => { let countEle = document.getElementById('count'); countEle!.innerText = ++count + ''; }, 1000); }其中设置了一个定时器,但当模块更改之后,这个定时器并没有被销毁,紧接着我们在
accept方法调用initState方法又创建了一个新的定时器,导致count的值错乱。那如何来解决这个问题呢?这就涉及到新的 HMR 方法——dispose方法了。模块销毁时逻辑: hot.dispose
代表在模块更新、旧模块需要销毁时需要做的一些事情,拿刚刚的场景来说,我们可以通过在state模块中调用
dispose方法来轻松解决定时器共存的问题,代码改动如下:ts// state.ts let timer: number | undefined; if (import.meta.hot) { import.meta.hot.dispose(() => { if (timer) { clearInterval(timer); } }) } export function initState() { let count = 0; timer = setInterval(() => { let countEle = document.getElementById('count'); countEle!.innerText = ++count + ''; }, 1000); }可以看到,当我稍稍改动一下state模块的内容(比如加个空格),页面确实会更新,而且也没有状态错乱的问题,说明我们在模块销毁前清除定时器的操作是生效的。但你又可以很明显地看到一个新的问题: 原来的状态丢失了,
count的内容从64突然变成1。这又是为什么呢?当我们改动了state模块的代码,main模块接受更新,执行
accept方法中的回调,接着会执行 state 模块的initState方法。注意了,此时新建的initState方法的确会初始化定时器,但同时也会初始化count变量,也就是count从 0 开始计数了!这显然是不符合预期的,我们期望的是每次改动state模块,之前的状态都保存下来。这就要使用到共享数据:
hot.data属性共享数据: hot.data 属性
这个属性用来在不同的模块实例间共享一些数据。使用上也非常简单,让我们来重构一下 state 模块:
diff// state.ts let timer: number | undefined; if (import.meta.hot) { + // 初始化 count + if (!import.meta.hot.data.count) { + import.meta.hot.data.count = 0; + } import.meta.hot.dispose(() => { if (timer) { clearInterval(timer); } }) } export function initState() { + const getAndIncCount = () => { + const data = import.meta.hot?.data || { + count: 0 + }; + data.count = data.count + 1; + return data.count; + }; timer = setInterval(() => { let countEle = document.getElementById('count'); + countEle!.innerText = getAndIncCount() + ''; }, 1000); }我们在
i对象上挂载了一个mport.meta.hot.data count属性,在二次执行initState的时候便会复用i上记录的mport.meta.hot.data count值,从而实现状态的保存。其它方法
i
mport.meta.hot.decline() 这个方法调用之后,相当于表示此模块不可热更新,当模块更新时会强制进行页面刷新。
i
mport.meta.hot.invalidate() 用来强制刷新页面。
自定义事件
你还可以通过
i来监听 HMR 的自定义事件,内部有这么几个事件会自动触发:mport.meta.hot.on vite:beforeUpdate当模块更新时触发;vite:beforeFullReload当即将重新刷新页面时触发;vite:beforePrune当不再需要的模块即将被剔除时触发;vite:error当发生错误时(例如,语法错误)触发。
自定义事件可以通过上面提到的
handleHotUpdate这个插件Hook来进行触发:ts// 插件 Hook handleHotUpdate({ server }) { server.ws.send({ type: 'custom', event: 'custom-update', data: {} }) return [] } // 前端代码 import.meta.hot.on('custom-update', (data) => { // 自定义更新逻辑 })
代码分割
随着前端工程的日渐复杂,单份的打包产物体积越来越庞大,会出现一系列应用加载性能问题,而代码分割可以很好地解决它们。
需要注意的是,下面会多次提到 bundle、chunk、vendor 这些构建领域的专业概念,这里给大家提前解释一下:
bundle指的是整体的打包产物,包含 JS 和各种静态资源。chunk指的是打包后的 JS 文件,是bundle的子集。vendor是指第三方包的打包产物,是一种特殊的 chunk。
Code Splitting 解决的问题
在传统的单 chunk 打包模式下,当项目代码越来越庞大,最后会导致浏览器下载一个巨大的文件,从页面加载性能的角度来说,主要会导致两个问题:
- 无法做到按需加载,即使是当前页面不需要的代码也会进行加载。
- 线上缓存复用率极低,改动一行代码即可导致整个
bundle产物缓存失效。
首先说第一个问题,一般而言,一个前端页面中的 JS 代码可以分为两个部分: Initial Chunk 和 Async Chunk,前者指页面首屏所需要的 JS 代码,而后者当前页面并不一定需要,一个典型的例子就是 路由组件,与当前路由无关的组件并不用加载。而项目被打包成单 bundle 之后,无论是 Initial Chunk 还是 Async Chunk,都会打包进同一个产物,也就是说,浏览器加载产物代码的时候,会将两者一起加载,导致许多冗余的加载过程,从而影响页面性能。而通过 Code Splitting 我们可以将按需加载的代码拆分出单独的 chunk,这样应用在首屏加载时只需要加载 Initial Chunk 即可,避免了冗余的加载过程,使页面性能得到提升。
其次,线上的缓存命中率是一个重要的性能衡量标准。对于线上站点而言,服务端一般在响应资源时加上一些 HTTP 响应头,最常见的响应头之一就是cache-control,它可以指定浏览器的强缓存,比如设置为下面这样:
cache-control: max-age=31536000表示资源过期时间为一年,在过期之前,访问相同的资源 url,浏览器直接利用本地的缓存,并不用给服务端发请求,这就大大降低了页面加载的网络开销。不过,在单 chunk 打包模式下面,一旦有一行代码变动,整个 chunk 的 url 地址都会变化
由于构建工具一般会根据产物的内容生成哈希值,一旦内容变化就会导致整个 chunk 产物的强缓存失效,所以单 chunk 打包模式下的缓存命中率极低,基本为零。
而进行Code Splitting之后,代码的改动只会影响部分的 chunk 哈希改动。好比入口文件引用了A、B、C、D四个组件,当我们修改 A 的代码后,变动的 Chunk 就只有 A 以及依赖 A 的 Chunk 中,A 对应的 chunk 会变动,这很好理解,后者也会变动是因为相应的引入语句会变化,如这里的入口文件会发生如下内容变动:
import CompA from './A.d3e2f17a.js'
// 更新 import 语句
import CompA from './A.a5d2f82b.js'也就是说,在改动 A 的代码后,B、C、D的 chunk 产物 url 并没有发生变化,从而可以让浏览器复用本地的强缓存,大大提升线上应用的加载性能。
Vite 默认拆包策略 Vite 中已经内置了一份拆包的策略。在生产环境下 Vite 完全利用 Rollup 进行构建,因此拆包也是基于 Rollup 来完成的,但 Rollup 本身是一个专注 JS 库打包的工具,对应用构建的能力还尚为欠缺,Vite 正好是补足了 Rollup 应用构建的能力,在拆包能力这一块的扩展就是很好的体现。
新建一个示例项目进行:npm run build
项目示例使用 Vite 2.9 之前的版本。Vite 2.9 及以后的版本拆包策略会有所不同,后文会介绍。
产物结构:
dist
├── assets
│ ├── Dynamic.3df51f7a.js // Async Chunk
│ ├── Dynamic.f2cbf023.css // Async Chunk (CSS)
│ ├── favicon.17e50649.svg // 静态资源
│ ├── index.1e236845.css // Initial Chunk (CSS)
│ ├── index.6773c114.js // Initial Chunk
│ └── vendor.ab4b9e1f.js // 第三方包产物 Chunk
└── index.html // 入口 HTML一方面 Vite 实现了自动 CSS 代码分割的能力,即实现一个 chunk 对应一个 css 文件,比如上面产物中index.js对应一份index.css,而按需加载的 chunk Dynamic.js也对应单独的一份 Dynamic.css文件,与 JS 文件的代码分割同理,这样做也能提升 CSS 文件的缓存复用率。
而另一方面, Vite 基于 Rollup 的 manualChunks API 实现了应用拆包的策略:
- 对于
Initial Chunk而言,业务代码和第三方包代码分别打包为单独的 chunk,在上述的例子中分别对应index.js和vendor.js。需要说明的是,这是 Vite 2.9 版本之前的做法,而在 Vite 2.9 及以后的版本,默认打包策略更加简单粗暴,将所有的 js 代码全部打包到 index.js 中。 - 对于
Async Chunk而言 ,动态 import 的代码会被拆分成单独的 chunk,如上述的Dynamic组件。
自定义拆包策略 针对更细粒度的拆包,Vite 的底层打包引擎 Rollup 提供了 manualChunks,让我们能自定义拆包策略,它属于 Vite 配置的一部分,示例如下:
// vite.config.ts
export default {
build: {
rollupOptions: {
output: {
// manualChunks 配置
manualChunks: {},
},
}
},
}manualChunks 主要有两种配置的形式,可以配置为一个对象或者一个函数。我们先来看看对象的配置,也是最简单的配置方式,你可以在上述的示例项目中添加如下的manualChunks配置代码:
// vite.config.ts
export default {
build: {
rollupOptions: {
output: {
// manualChunks 配置
manualChunks: {
// 将 React 相关库打包成单独的 chunk 中
'react-vendor': ['react', 'react-dom'],
// 将 Lodash 库的代码单独打包
'lodash': ['lodash-es'],
// 将组件库的代码打包
'library': ['antd', '@arco-design/web-react'],
},
},
}
},
}在对象格式的配置中,key代表 chunk 的名称,value为一个字符串数组,每一项为第三方包的包名。在进行了如上的配置之后,我们可以执行npm run build尝试一下打包。
可以看到原来的 vendor 大文件被拆分成了我们手动指定的几个小 chunk,每个 chunk 大概 200 KB 左右,是一个比较理想的 chunk 体积。这样,当第三方包更新的时候,也只会更新其中一个 chunk 的 url,而不会全量更新,从而提高了第三方包产物的缓存命中率。
我们还可以通过函数进行更加灵活的配置,而 Vite 中的默认拆包策略也是通过函数的方式来进行配置的,我们可以在 Vite 的实现中瞧一瞧:
// Vite 部分源码
function createMoveToVendorChunkFn(config: ResolvedConfig): GetManualChunk {
const cache = new Map<string, boolean>()
// 返回值为 manualChunks 的配置
return (id, { getModuleInfo }) => {
// Vite 默认的配置逻辑其实很简单
// 主要是为了把 Initial Chunk 中的第三方包代码单独打包成`vendor.[hash].js`
if (
id.includes('node_modules') &&
!isCSSRequest(id) &&
// 判断是否为 Initial Chunk
staticImportedByEntry(id, getModuleInfo, cache)
) {
return 'vendor'
}
}
}Rollup 会对每一个模块调用 manualChunks 函数,在 manualChunks 的函数入参中你可以拿到模块 id 及模块详情信息,经过一定的处理后返回 chunk 文件的名称,这样当前 id 代表的模块便会打包到你所指定的 chunk 文件中。
把刚才的拆包逻辑用函数来实现一遍:
// vite.config.ts
export default {
build: {
rollupOptions: {
output: {
// manualChunks 配置
manualChunks(id) {
if (id.includes('antd') || id.includes('@arco-design/web-react')) {
return 'library';
}
if (id.includes('lodash')) {
return 'lodash';
}
if (id.includes('react')) {
return 'react';
}
}
},
}
},
}打包后各个第三方包的 chunk (如lodash、react等等)都能拆分出来,但实际上运行 npx vite preview 命令预览产物,会发现产物根本没有办法运行起来,页面出现白屏,同时控制台出现如下的报错:
Uncaught TypeError: l$1 is not a function at react-vendor.e2c4883f.js:77:1函数配置虽然灵活而方便,但稍不注意就陷入此类的产物错误问题当中,上面报错是循环引用的问题。
解决循环引用问题
从报错信息追溯到产物中,可以发现react-vendor.js与index.js发生了循环引用:
// react-vendor.e2c4883f.js
import { q as objectAssign } from "./index.37a7b2eb.js";
// index.37a7b2eb.js
import { R as React } from "./react-vendor.e2c4883f.js";这是很典型的 ES 模块循环引用的场景,我们可以用一个最基本的例子来复原这个场景:
// a.js
import { funcB } from './b.js';
funcB();
export var funcA = () => {
console.log('a');
}
// b.js
import { funcA } from './a.js';
funcA();
export var funcB = () => {
console.log('b')
}接着我们可以执行一下a.js文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<script type="module" src="/a.js"></script>
</body>
</html>在浏览器中打开会出现类似的报错:
Uncaught TypeError: funcA is not a function at b.js:3:1代码的执行原理如下:
- JS 引擎执行
a.js时,发现引入了b.js,于是去执行b.js - 引擎执行
b.js,发现里面引入了a.js(出现循环引用),认为a.js已经加载完成,继续往下执行 - 执行到
funcA()语句时发现funcA并没有定义,于是报错。
a.js ---> b.js ---> b.js发现a.js的变量未定义打包产物的执行过程也是同理
index.js ---> react-vendor.js ---> react-vendor.js发现index.js的变量未定义react-vendor为什么需要引用index.js的代码呢?其实也很好理解,我们之前在manualChunks中仅仅将路径包含 react 的模块打包到react-vendor中,殊不知,像object-assign这种 react 本身的依赖并没有打包进react-vendor中,而是打包到另外的 chunk 当中,从而导致如下的循环依赖关系
index.js ---引入React---> react-vendor.js ---引入object-assign等依赖---> index.js之前的 manualChunks 逻辑过于简单粗暴,仅仅通过路径 id 来决定打包到哪个 chunk 中,而漏掉了间接依赖的情况。如果针对像object-assign这种间接依赖,我们也能识别出它属于 react 的依赖,将其自动打包到react-vendor中,这样就可以避免循环引用的问题。
我们来梳理一下解决的思路:
- 确定 react 相关包的入口路径。
- 在
manualChunks中拿到模块的详细信息,向上追溯它的引用者,如果命中 react 的路径,则将模块放到react-vendor中。
实际代码的实现:
// 确定 react 相关包的入口路径
const chunkGroups = {
'react-vendor': [
require.resolve('react'),
require.resolve('react-dom')
],
}
// Vite 中的 manualChunks 配置
function manualChunks(id, { getModuleInfo }) {
for (const group of Object.keys(chunkGroups)) {
const deps = chunkGroups[group];
if (
id.includes('node_modules') &&
// 递归向上查找引用者,检查是否命中 chunkGroups 声明的包
isDepInclude(id, deps, [], getModuleInfo)
) {
return group;
}
}
}实际上核心逻辑包含在isDepInclude函数,用来递归向上查找引用者模块:
// 缓存对象
const cache = new Map();
function isDepInclude (id: string, depPaths: string[], importChain: string[], getModuleInfo): boolean | undefined {
const key = `${id}-${depPaths.join('|')}`;
// 出现循环依赖,不考虑
if (importChain.includes(id)) {
cache.set(key, false);
return false;
}
// 验证缓存
if (cache.has(key)) {
return cache.get(key);
}
// 命中依赖列表
if (depPaths.includes(id)) {
// 引用链中的文件都记录到缓存中
importChain.forEach(item => cache.set(`${item}-${depPaths.join('|')}`, true));
return true;
}
const moduleInfo = getModuleInfo(id);
if (!moduleInfo || !moduleInfo.importers) {
cache.set(key, false);
return false;
}
// 核心逻辑,递归查找上层引用者
const isInclude = moduleInfo.importers.some(
importer => isDepInclude(importer, depPaths, importChain.concat(id), getModuleInfo)
);
// 设置缓存
cache.set(key, isInclude);
return isInclude;
};对于这个函数的实现,有两个地方需要注意:
- 我们可以通过 manualChunks 提供的入参
getModuleInfo来获取模块的详情moduleInfo,然后通过moduleInfo.importers拿到模块的引用者,针对每个引用者又可以递归地执行这一过程,从而获取引用链的信息。 - 尽量使用缓存。由于第三方包模块数量一般比较多,对每个模块都向上查找一遍引用链会导致开销非常大,并且会产生很多重复的逻辑,使用缓存会极大加速这一过程。
完成上述manualChunks的完整逻辑后,现在我们来执行npm run build来进行打包,react-vendor可以正常拆分出来,react的一些间接依赖已经成功打包到了react-vendor当中,执行npx view preview预览产物页面也能正常渲染了
终极解决方案
自定义拆包插件:vite-plugin-chunk-split
# 安装插件
pnpm i vite-plugin-chunk-split -D// vite.config.ts
import { chunkSplitPlugin } from 'vite-plugin-chunk-split';
export default {
chunkSplitPlugin({
// 指定拆包策略
customSplitting: {
// 1. 支持填包名。`react` 和 `react-dom` 会被打包到一个名为`render-vendor`的 chunk 里面(包括它们的依赖,如 object-assign)
'react-vendor': ['react', 'react-dom'],
// 2. 支持填正则表达式。src 中 components 和 utils 下的所有文件被会被打包为`component-util`的 chunk 中
'components-util': [/src\/components/, /src\/utils/]
}
})
}这个插件还可以支持多种打包策略,包括 unbundle 模式打包,你可以去 使用文档 探索更多使用姿势。
语法降级&Polyfill
某些低版本浏览器并没有提供 Promise 语法环境以及对象和数组的各种 API,甚至不支持箭头函数语法,代码直接报错,从而导致线上白屏事故的发生,尤其是需要兼容到IE 11、iOS 9以及Android 4.4的场景中很容易会遇到。
旧版浏览器的语法兼容问题主要分两类: 语法降级问题和 Polyfill 缺失问题。前者比较好理解,比如某些浏览器不支持箭头函数,我们就需要将其转换为function(){}语法;而对后者来说,Polyfill本身可以翻译为垫片,也就是为浏览器提前注入一些 API 的实现代码,如Object.entries方法的实现,这样可以保证产物可以正常使用这些 API,防止报错。
这两类问题本质上是通过前端的编译工具链(如Babel)及 JS 的基础 Polyfill 库(如corejs)来解决的,不会跟具体的构建工具所绑定。也就是说,对于这些本质的解决方案,在其它的构建工具(如 Webpack)能使用,在 Vite 当中也完全可以使用。
构建工具考虑的仅仅是如何将这些底层基础设施接入到构建过程的问题,自己并不需要提供底层的解决方案,正所谓术业有专攻,把专业的事情交给专业的工具去做。
底层工具链
- 工具概览
解决上述提到的两类语法兼容问题,主要需要用到两方面的工具,分别包括:
- 编译时工具。代表工具有
@babel/preset-env和@babel/plugin-transform-runtime。 - 运行时基础库。代表库包括
core-js和regenerator-runtime。
编译时工具的作用是在代码编译阶段进行语法降级及添加 polyfill 代码的引用语句,如:
import "core-js/modules/es6.set.js"由于这些工具只是编译阶段用到,运行时并不需要,我们需要将其放入package.json中的devDependencies中。
而运行时基础库是根据 ESMAScript官方语言规范提供各种Polyfill实现代码,主要包括core-js和regenerator-runtime两个基础库,不过在 babel 中也会有一些上层的封装,包括:
看似各种运行时库眼花缭乱,其实都是core-js和regenerator-runtime不同版本的封装罢了(@babel/runtime是个特例,不包含 core-js 的 Polyfill)。这类库是项目运行时必须要使用到的,因此一定要放到package.json中的dependencies中!
- 实际使用 初始化项目:
mkdir babel-test
npm init -y安装一些必要的依赖:
pnpm i @babel/cli @babel/core @babel/preset-env各个依赖的作用:
@babel/cli: 为 babel 官方的脚手架工具,很适合我们练习用。@babel/core: babel 核心编译库。@babel/preset-env: babel 的预设工具集,基本为 babel 必装的库。
新建 src 目录,在目录下增加index.js文件:
const func = async () => {
console.log(12123)
}
Promise.resolve().finally();示例代码中既包含了高级语法也包含现代浏览器的API,正好可以针对语法降级和 Polyfill 注入两个功能进行测试。
新建.babelrc.json即 babel 的配置文件,内容如下:
{
"presets": [
[
"@babel/preset-env",
{
// 指定兼容的浏览器版本
"targets": {
"ie": "11"
},
// 基础库 core-js 的版本,一般指定为最新的大版本
"corejs": 3,
// Polyfill 注入策略,后文详细介绍
"useBuiltIns": "usage",
// 不将 ES 模块语法转换为其他模块语法
"modules": false
}
]
]
}通过 targets 参数指定要兼容的浏览器版本,也可以用 Browserslist 配置语法:
{
// ie 不低于 11 版本,全球超过 0.5% 使用,且还在维护更新的浏览器
"targets": "ie >= 11, > 0.5%, not dead"
}Browserslist 是一个帮助我们设置目标浏览器的工具,不光是 Babel 用到,其他的编译工具如postcss-preset-env、autoprefix中都有所应用。对于Browserslist的配置内容,你既可以放到 Babel 这种特定工具当中,也可以在package.json中通过browserslist声明:
// package.json
{
"browserslist": "ie >= 11"
}或者通过.browserslistrc进行声明:
// .browserslistrc
ie >= 11在实际的项目中,一般我们可以将使用下面这些最佳实践集合来描述不同的浏览器类型,减轻配置负担:
// 现代浏览器
last 2 versions and since 2018 and > 0.5%
// 兼容低版本 PC 浏览器
IE >= 11, > 0.5%, not dead
// 兼容低版本移动端浏览器
iOS >= 9, Android >= 4.4, last 2 versions, > 0.2%, not dead另外一个重要的配置useBuiltIns,它决定了添加 Polyfill 策略,默认是 false,即不添加任何的 Polyfill。你可以手动将useBuiltIns配置为entry或者usage
首先你可以将这个字段配置为entry,需要注意的是,entry配置规定你必须在入口文件手动添加一行这样的代码:
// index.js 开头加上
import 'core-js';接着在终端执行下面的命令进行 Babel 编译:
npx babel src --out-dir dist产物输出在dist目录中,Babel 已经根据目标浏览器的配置为我们添加了大量的 Polyfill 代码,index.js文件简单的几行代码被编译成近 300 行。实际上,Babel 所做的事情就是将你的import "core-js"代码替换成了产物中的这些具体模块的导入代码。
但这个配置有一个问题,即无法做到按需导入,上面的产物代码其实有大部分的 Polyfill 的代码我们并没有用到。接下来我们试试useBuiltIns: usage这个按需导入的配置,改动配置后执行编译命令:
npx babel src --out-dir dist同样可以看到产物输出在了dist/index.js中
Polyfill 代码主要来自
corejs和regenerator-runtime,因此如果要运行起来,必须要装这两个库。
Polyfill 的代码精简了许多,真正地实现了按需 Polyfill 导入。因此,在实际的使用当中,还是推荐大家尽量使用useBuiltIns: "usage",进行按需的 Polyfill 注入。
梳理一下,上面我们利用@babel/preset-env进行了目标浏览器语法的降级和Polyfill注入,同时用到了core-js和regenerator-runtime两个核心的运行时库。但@babel/preset-env 的方案也存在一定局限性:
- 如果使用新特性,往往是通过基础库(如 core-js)往全局环境添加 Polyfill,如果是开发应用没有任何问题,如果是开发第三方工具库,则很可能会对
全局空间造成污染。 - 很多工具函数的实现代码(如上面示例中的
_defineProperty方法),会在许多文件中重现出现,造成文件体积冗余。
- 更优的 Polyfill 注入方案: transform-runtime
接下来要介绍的transform-runtime方案,就是为了解决@babel/preset-env的种种局限性。
需要提前说明的是,
transform-runtime方案可以作为@babel/preset-env中useBuiltIns配置的替代品,也就是说,一旦使用transform-runtime方案,你应该把useBuiltIns属性设为false。
尝试一下这个方案,首先安装必要的依赖:
pnpm i @babel/plugin-transform-runtime -D
pnpm i @babel/runtime-corejs3 -S这两个依赖的作用: 前者是编译时工具,用来转换语法和添加 Polyfill,后者是运行时基础库,封装了core-js、regenerator-runtime和各种语法转换用到的工具函数。
core-js 有三种产物,分别是
core-js、core-js-pure和core-js-bundle。第一种是全局 Polyfill 的做法,@babel/preset-env就是用的这种产物;第二种不会把 Polyfill 注入到全局环境,可以按需引入;第三种是打包好的版本,包含所有的 Polyfill,不太常用。@babel/runtime-corejs3 使用的是第二种产物。
.babelrc.json配置:
{
"plugins": [
// 添加 transform-runtime 插件
[
"@babel/plugin-transform-runtime",
{
"corejs": 3
}
]
],
"presets": [
[
"@babel/preset-env",
{
"targets": {
"ie": "11"
},
"corejs": 3,
// 关闭 @babel/preset-env 默认的 Polyfill 注入
"useBuiltIns": false,
"modules": false
}
]
]
}npx babel src --out-dir disttransform-runtime 一方面能够让我们在代码中使用非全局版本的 Polyfill,这样就避免全局空间的污染,这也得益于 core-js 的 pure 版本产物特性;另一方面对于asyncToGeneator这类的工具函数,它也将其转换成了一段引入语句,不再将完整的实现放到文件中,节省了编译后文件的体积。
另外,transform-runtime方案引用的基础库也发生了变化,不再是直接引入core-js和regenerator-runtime,而是引入@babel/runtime-corejs3。
Vite 语法降级与 Polyfill 注入
Vite 官方已经为我们封装好了一个开箱即用的方案: @vitejs/plugin-legacy,我们可以基于它来解决项目语法的浏览器兼容问题。这个插件内部同样使用 @babel/preset-env 以及 core-js 等一系列基础库来进行语法降级和 Polyfill 注入,因此对于上文所介绍的底层工具链的掌握是必要的,否则无法理解插件内部所做的事情,真正遇到问题时往往会不知所措。
# 安装插件
pnpm i @vitejs/plugin-legacy -D// vite.config.ts
import legacy from '@vitejs/plugin-legacy';
import { defineConfig } from 'vite'
export default defineConfig({
plugins: [
// 省略其它插件
legacy({
// 设置目标浏览器,browserslist 配置语法
targets: ['ie >= 11'],
})
]
})通过 targets 指定目标浏览器,这个参数在插件内部会透传给 @babel/preset-env。
执行 npm run build 打包后,多出了index-legacy.js、vendor-legacy.js以及polyfills-legacy.js三份产物文件。观察一下index.html的产物内容:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/assets/favicon.17e50649.svg" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Vite App</title>
<!-- 1. Modern 模式产物 -->
<script type="module" crossorigin src="/assets/index.c1383506.js"></script>
<link rel="modulepreload" href="/assets/vendor.0f99bfcc.js">
<link rel="stylesheet" href="/assets/index.91183920.css">
</head>
<body>
<div id="root"></div>
<!-- 2. Legacy 模式产物 -->
<script nomodule>兼容 iOS nomodule 特性的 polyfill 省略具体代码</script>
<script nomodule id="vite-legacy-polyfill" src="/assets/polyfills-legacy.36fe2f9e.js"></script>
<script nomodule id="vite-legacy-entry" data-src="/assets/index-legacy.c3d3f501.js">System.import(document.getElementById('vite-legacy-entry').getAttribute('data-src'))</script>
</body>
</html>通过官方的legacy插件, Vite 会分别打包出Modern模式和Legacy模式的产物,然后将两种产物插入同一个 HTML 里面,Modern产物被放到 type="module"的 script 标签中,而Legacy产物则被放到带有 nomodule 的 script 标签中。
这样产物便就能够同时放到现代浏览器和不支持 type="module" 的低版本浏览器当中执行。当然,在具体的代码语法层面,插件还需要考虑语法降级和 Polyfill 按需注入的问题,接下来我们就来分析一下 Vite 的官方 legacy 插件是如何解决这些问题的。
插件执行原理
官方的legacy插件是一个相对复杂度比较高的插件,直接看源码可能会很难理解,这里我梳理了画了一张简化后的流程图,接下来我们就根据这张流程图来一一拆解这个插件在各个钩子阶段到底做了些什么。
首先是在 configResolved 钩子中调整了 output 属性,这么做的目的是让 Vite 底层使用的打包引擎 Rollup 能另外打包出一份 Legacy 模式 的产物,实现代码如下:
const createLegacyOutput = (options = {}) => {
return {
...options,
// system 格式产物
format: 'system',
// 转换效果: index.[hash].js -> index-legacy.[hash].js
entryFileNames: getLegacyOutputFileName(options.entryFileNames),
chunkFileNames: getLegacyOutputFileName(options.chunkFileNames)
}
}
const { rollupOptions } = config.build
const { output } = rollupOptions
if (Array.isArray(output)) {
rollupOptions.output = [...output.map(createLegacyOutput), ...output]
} else {
rollupOptions.output = [createLegacyOutput(output), output || {}]
}接着,在renderChunk阶段,插件会对 Legacy 模式产物进行语法转译和 Polyfill 收集,值得注意的是,这里并不会真正注入Polyfill,而仅仅只是收集Polyfill:
{
renderChunk(raw, chunk, opts) {
// 1. 使用 babel + @babel/preset-env 进行语法转换与 Polyfill 注入
// 2. 由于此时已经打包后的 Chunk 已经生成
// 这里需要去掉 babel 注入的 import 语句,并记录所需的 Polyfill
// 3. 最后的 Polyfill 代码将会在 generateBundle 阶段生成
}
}由于场景是应用打包,这里直接使用 @babel/preset-env 的useBuiltIns: 'usage' 来进行全局 Polyfill 的收集是比较标准的做法。
回到 Vite 构建的主流程中,接下来会进入generateChunk钩子阶段,现在 Vite 会对之前收集到的Polyfill进行统一的打包,实现也比较精妙,主要逻辑集中在buildPolyfillChunk函数中:
// 打包 Polyfill 代码
async function buildPolyfillChunk(
name,
imports
bundle,
facadeToChunkMap,
buildOptions,
externalSystemJS
) {
let { minify, assetsDir } = buildOptions
minify = minify ? 'terser' : false
// 调用 Vite 的 build API 进行打包
const res = await build({
// 根路径设置为插件所在目录
// 由于插件的依赖包含`core-js`、`regenerator-runtime`这些运行时基础库
// 因此这里 Vite 可以正常解析到基础 Polyfill 库的路径
root: __dirname,
write: false,
// 这里的插件实现了一个虚拟模块
// Vite 对于 polyfillId 会返回所有 Polyfill 的引入语句
plugins: [polyfillsPlugin(imports, externalSystemJS)],
build: {
rollupOptions: {
// 访问 polyfillId
input: {
// name 暂可视作`polyfills-legacy`
// pofyfillId 为一个虚拟模块,经过插件处理后会拿到所有 Polyfill 的引入语句
[name]: polyfillId
},
}
}
});
// 拿到 polyfill 产物 chunk
const _polyfillChunk = Array.isArray(res) ? res[0] : res
if (!('output' in _polyfillChunk)) return
const polyfillChunk = _polyfillChunk.output[0]
// 后续做两件事情:
// 1. 记录 polyfill chunk 的文件名,方便后续插入到 Modern 模式产物的 HTML 中;
// 2. 在 bundle 对象上手动添加 polyfill 的 chunk,保证产物写到磁盘中
}因此,你可以理解为这个函数的作用即通过 vite build 对 renderChunk 中收集到 polyfill 代码进行打包,生成一个单独的 chunk:

需要注意的是,polyfill chunk 中除了包含一些 core-js 和 regenerator-runtime 的相关代码,也包含了
SystemJS的实现代码,你可以将其理解为 ESM 的加载器,实现了在旧版浏览器下的模块加载能力。
现在我们已经能够拿到 Legacy 模式的产物文件名及 Polyfill Chunk 的文件名,那么就可以通过transformIndexHtml钩子来将这些产物插入到 HTML 的结构中:
{
transformIndexHtml(html) {
// 1. 插入 Polyfill chunk 对应的 <script nomodule> 标签
// 2. 插入 Legacy 产物入口文件对应的 <script nomodule> 标签
}
}主流程中的细节:
- 当插件参数中开启了
modernPolyfills选项时,Vite 也会自动对 Modern 模式的产物进行 Polyfill 收集,并单独打包成polyfills-modern.js的 chunk,原理和 Legacy 模式下处理 Polyfill 一样。 - SaFari 10.1 版本不支持
nomodule,为此需要单独引入一些补丁代码,点击查看。 - 部分低版本 Edge 浏览器虽然支持 type="module",但不支持动态 import,为此也需要插入一些补丁代码,针对这种情况下降级使用 Legacy 模式的产物。
预渲染 SSR 工程
客户端渲染存在着一定的问题,例如首屏加载比较慢、对 SEO 不太友好,因此 SSR (Server Side Render)即服务端渲染技术应运而生,它在保留 CSR 技术栈的同时,也能解决 CSR 的各种问题。
SSR 基本概念
首先我们来分析一下 CSR 的问题,它的 HTML 产物一般是如下的结构:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title></title>
<link rel="stylesheet" href="xxx.css" />
</head>
<body>
<!-- 一开始没有页面内容 -->
<div id="root"></div>
<!-- 通过 JS 执行来渲染页面 -->
<script src="xxx.chunk.js"></script>
</body>
</html>浏览器的渲染流程,如下图所示:
当浏览器拿到如上的 HTML 内容之后,其实并不能渲染完整的页面内容,因为此时的 body 中基本只有一个空的 div 节点,并没有填入真正的页面内容。而接下来浏览器开始下载并执行 JS 代码,经历了框架初始化、数据请求、DOM 插入等操作之后才能渲染出完整的页面。也就是说,在 CSR 中完整的页面内容本质上通过 JS 代码执行之后才能够渲染。这主要会导致两个方面的问题:
- 首屏加载速度比较慢。首屏加载需要依赖 JS 的执行,下载和执行 JS 都可能是非常耗时的操作,尤其是在一些网络不佳的场景,或者性能敏感的低端机下。
- 对 SEO(搜索引擎优化) 不友好。页面 HTML 没有具体的页面内容,导致搜索引擎爬虫无法获取关键词信息,导致网站排名受到影响。
在 SSR 的场景下,服务端生成好完整的 HTML 内容,直接返回给浏览器,浏览器能够根据 HTML 渲染出完整的首屏内容,而不需要依赖 JS 的加载,这样一方面能够降低首屏渲染的时间,另一方面也能将完整的页面内容展现给搜索引擎的爬虫,利于 SEO。
当然,SSR 中只能生成页面的内容和结构,并不能完成事件绑定,因此需要在浏览器中执行 CSR 的 JS 脚本,完成事件绑定,让页面拥有交互的能力,这个过程被称作hydrate(翻译为注水或者激活)。同时,像这样服务端渲染 + 客户端 hydrate 的应用也被称为同构应用。
SSR 生命周期分析
SSR 在服务端(这里主要指 Node.js 端)提前渲染出完整的 HTML 内容,首先需要保证前端的代码经过编译后放到服务端中能够正常执行,其次在服务端渲染前端组件,生成并组装应用的 HTML。这就涉及到 SSR 应用的两大生命周期: 构建时和运行时
构建时:
解决模块加载问题。在原有的构建过程之外,需要加入
SSR 构建的过程 ,具体来说,我们需要另外生成一份CommonJS格式的产物,使之能在 Node.js 正常加载。当然,随着 Node.js 本身对 ESM 的支持越来越成熟,我们也可以复用前端 ESM 格式的代码,Vite 在开发阶段进行 SSR 构建也是这样的思路。
移除样式代码的引入。直接引入一行 css 在服务端其实是无法执行的,因为 Node.js 并不能解析 CSS 的内容。但
CSS Modules的情况除外,如下所示:tsimport styles from './index.module.css' // 这里的 styles 是一个对象,如{ "container": "xxx" },而不是 CSS 代码 console.log(styles)依赖外部化(external)。对于某些第三方依赖我们并不需要使用构建后的版本,而是直接从
node_modules中读取,比如react-dom,这样在SSR 构建的过程中将不会构建这些依赖,从而极大程度上加速 SSR 的构建。
运行时

- 加载 SSR 入口模块。在这个阶段,我们需要确定 SSR 构建产物的入口,即组件的入口在哪里,并加载对应的模块。
- 进行数据预取。这时候 Node 侧会通过查询数据库或者网络请求来获取应用所需的数据。
- 渲染组件。这个阶段为 SSR 的核心,主要将第
1步中加载的组件渲染成 HTML 字符串或者 Stream 流。 - HTML 拼接。在组件渲染完成之后,我们需要拼接完整的 HTML 字符串,并将其作为响应返回给浏览器。
从上面的分析中可以发现,SSR 其实是构建时和运行时互相配合才能实现的,也就是说,仅靠构建工具是不够的,写一个 Vite 插件严格意义上无法实现 SSR 的能力,我们需要对 Vite 的构建流程做一些整体的调整,并且加入一些服务端运行时的逻辑才能实现。
基于 Vite 搭建 SSR 项目
1. SSR 构建 API
Vite 如何支持 SSR 构建的,可以分为两种情况,在开发环境下,Vite 依然秉承 ESM 模块按需加载即 no-bundle 的理念,对外提供了 ssrLoadModule API,你可以无需打包项目,将入口文件的路径传入 ssrLoadModule 即可:
// 加载服务端入口模块
const xxx = await vite.ssrLoadModule('/src/entry-server.tsx')而在生产环境下,Vite 会默认进行打包,对于 SSR 构建输出 CommonJS 格式的产物。我们可以在package.json中加入这样类似的构建指令:
{
"build:ssr": "vite build --ssr 服务端入口路径"
}这样 Vite 会专门为 SSR 打包出一份构建产物。因此你可以看到,大部分 SSR 构建时的事情,Vite 已经帮我们提供了开箱即用的方案,我们后续直接使用即可。
2. 项目骨架搭建
通过脚手架初始化一个react+ts的项目:
npm init vite
pnpm i删除项目自带的src/main.ts,然后在 src 目录下新建entry-client.tsx和entry-server.tsx两个入口文件:
// entry-client.ts
// 客户端入口文件
import React from 'react'
import ReactDOM from 'react-dom'
import './index.css'
import App from './App'
ReactDOM.hydrate(
<React.StrictMode>
<App />
</React.StrictMode>,
document.getElementById('root')
)
// entry-server.ts
// 导出 SSR 组件入口
import App from "./App";
import './index.css'
function ServerEntry(props: any) {
return (
<App/>
);
}
export { ServerEntry };以 Express 框架为例来实现 Node 后端服务,后续的 SSR 逻辑会接入到这个服务中。安装以下的依赖:
pnpm i express -S
pnpm i @types/express -D// 新建 src/ssr-server/index.ts
// 后端服务
import express from 'express';
async function createServer() {
const app = express();
app.listen(3000, () => {
console.log('Node 服务器已启动~')
console.log('http://localhost:3000');
});
}
createServer();// package.json
{
"scripts": {
// 开发阶段启动 SSR 的后端服务
"dev": "nodemon --watch src/ssr-server --exec 'esno src/ssr-server/index.ts'",
// 打包客户端产物和 SSR 产物
"build": "npm run build:client && npm run build:server",
"build:client": "vite build --outDir dist/client",
"build:server": "vite build --ssr src/entry-server.tsx --outDir dist/server",
// 生产环境预览 SSR 效果
"preview": "NODE_ENV=production esno src/ssr-server/index.ts"
}
}其中涉及到两个额外的工具:
nodemon: 一个监听文件变化自动重启 Node 服务的工具。esno: 类似ts-node的工具,用来执行 ts 文件,底层基于 Esbuild 实现。
安装这两个依赖:
pnpm i esno nodemon -D3. SSR 运行时实现
SSR 作为一种特殊的后端服务,我们可以将其封装成一个中间件的形式,如以下的代码所示:
import express, { RequestHandler, Express } from 'express';
import { ViteDevServer } from 'vite';
const isProd = process.env.NODE_ENV === 'production';
const cwd = process.cwd();
async function createSsrMiddleware(app: Express): Promise<RequestHandler> {
let vite: ViteDevServer | null = null;
if (!isProd) {
vite = await (await import('vite')).createServer({
root: process.cwd(),
server: {
middlewareMode: 'ssr',
}
})
// 注册 Vite Middlewares
// 主要用来处理客户端资源
app.use(vite.middlewares);
}
return async (req, res, next) => {
// SSR 的逻辑
// 1. 加载服务端入口模块
// 2. 数据预取
// 3. 「核心」渲染组件
// 4. 拼接 HTML,返回响应
};
}
async function createServer() {
const app = express();
// 加入 Vite SSR 中间件
app.use(await createSsrMiddleware(app));
app.listen(3000, () => {
console.log('Node 服务器已启动~')
console.log('http://localhost:3000');
});
}
createServer();接下来把焦点放在中间件内 SSR 的逻辑实现上,首先实现第一步即加载服务端入口模块:
async function loadSsrEntryModule(vite: ViteDevServer | null) {
// 生产模式下直接 require 打包后的产物
if (isProd) {
const entryPath = path.join(cwd, 'dist/server/entry-server.js');
return require(entryPath);
}
// 开发环境下通过 no-bundle 方式加载
else {
const entryPath = path.join(cwd, 'src/entry-server.tsx');
return vite!.ssrLoadModule(entryPath);
}
}中间件内的逻辑如下:
async function createSsrMiddleware(app: Express): Promise<RequestHandler> {
// 省略前面的代码
return async (req, res, next) => {
const url = req.originalUrl;
// 1. 服务端入口加载
const { ServerEntry } = await loadSsrEntryModule(vite);
// ...
}
}接下来实现服务端的数据预取操作,你可以在entry-server.tsx中添加一个简单的获取数据的函数:
export async function fetchData() {
return { user: 'xxx' }
}然后在 SSR 中间件中完成数据预取的操作:
// src/ssr-server/index.ts
async function createSsrMiddleware(app: Express): Promise<RequestHandler> {
// 省略前面的代码
return async (req, res, next) => {
const url = req.originalUrl;
// 1. 服务端入口加载
const { ServerEntry, fetchData } = await loadSsrEntryModule(vite);
// 2. 预取数据
const data = await fetchData();
}
}接着我们进入到核心的组件渲染阶段:
// src/ssr-server/index.ts
import { renderToString } from 'react-dom/server';
import React from 'react';
async function createSsrMiddleware(app: Express): Promise<RequestHandler> {
// 省略前面的代码
return async (req, res, next) => {
const url = req.originalUrl;
// 1. 服务端入口加载
const { ServerEntry, fetchData } = await loadSsrEntryModule(vite);
// 2. 预取数据
const data = await fetchData();
// 3. 组件渲染 -> 字符串
const appHtml = renderToString(React.createElement(ServerEntry, { data }));
}
}由于在第一步之后我们拿到了入口组件,现在可以调用前端框架的 renderToStringAPI 将组件渲染为字符串,组件的具体内容便就此生成了。
目前我们已经拿到了组件的 HTML 以及预取的数据,接下来我们在根目录下的 HTML 中提供相应的插槽,方便内容的替换:
// index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/src/favicon.svg" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Vite App</title>
</head>
<body>
<div id="root"><!-- SSR_APP --></div>
<script type="module" src="/src/entry-client.tsx"></script>
<!-- SSR_DATA -->
</body>
</html>紧接着我们在 SSR 中间件中补充 HTML 拼接的逻辑:
// src/ssr-server/index.ts
function resolveTemplatePath() {
return isProd ?
path.join(cwd, 'dist/client/index.html') :
path.join(cwd, 'index.html');
}
async function createSsrMiddleware(app: Express): Promise<RequestHandler> {
// 省略之前的代码
return async (req, res, next) => {
const url = req.originalUrl;
// 省略前面的步骤
// 4. 拼接完整 HTML 字符串,返回客户端
const templatePath = resolveTemplatePath();
let template = await fs.readFileSync(templatePath, 'utf-8');
// 开发模式下需要注入 HMR、环境变量相关的代码,因此需要调用 vite.transformIndexHtml
if (!isProd && vite) {
template = await vite.transformIndexHtml(url, template);
}
const html = template
.replace('<!-- SSR_APP -->', appHtml)
// 注入数据标签,用于客户端 hydrate
.replace(
'<!-- SSR_DATA -->',
`<script>window.__SSR_DATA__=${JSON.stringify(data)}</script>`
);
res.status(200).setHeader('Content-Type', 'text/html').end(html);
}
}在拼接 HTML 的逻辑中,除了添加页面的具体内容,同时我们也注入了一个挂载全局数据的script标签。
在 SSR 的基本概念中我们就提到过,为了激活页面的交互功能,我们需要执行 CSR 的 JavaScript 代码来进行 hydrate 操作,而客户端 hydrate 的时候需要和服务端同步预取后的数据,保证页面渲染的结果和服务端渲染一致,因此,我们刚刚注入的数据 script 标签便派上用场了。由于全局的 window 上挂载服务端预取的数据,我们可以在entry-client.tsx也就是客户端渲染入口中拿到这份数据,并进行 hydrate:
import React from 'react'
import ReactDOM from 'react-dom'
import './index.css'
import App from './App'
// @ts-ignore
const data = window.__SSR_DATA__;
ReactDOM.hydrate(
<React.StrictMode>
<App data={data}/>
</React.StrictMode>,
document.getElementById('root')
)执行npm run dev启动项目,打开浏览器后查看页面源码,可以发现 SSR 生成的 HTML 已经顺利返回了。
4. 生产环境的 CSR 资源处理
如果你现在执行npm run build及npm run preview进行生产环境的预览,会发现 SSR 可以正常返回内容,但所有的静态资源及 CSR 的代码都失效了
开发阶段并没有这个问题,这是因为对于开发阶段的静态资源 Vite Dev Server 的中间件已经帮我们处理了,而生产环境所有的资源都已经打包完成,我们需要启用单独的静态资源服务来承载这些资源。这里你可以serve-static中间件来完成这个服务,首先安装对应第三方包:
pnpm i serve-static -S到 server 端注册:
// 过滤出页面请求
function matchPageUrl(url: string) {
if (url === '/') {
return true;
}
return false;
}
async function createSsrMiddleware(app: Express): Promise<RequestHandler> {
return async (req, res, next) => {
try {
const url = req.originalUrl;
if (!matchPageUrl(url)) {
// 走静态资源的处理
return await next();
}
// SSR 的逻辑省略
} catch(e: any) {
vite?.ssrFixStacktrace(e);
console.error(e);
res.status(500).end(e.message);
}
}
}
async function createServer() {
const app = express();
// 加入 Vite SSR 中间件
app.use(await createSsrMiddleware(app));
// 注册中间件,生产环境端处理客户端资源
if (isProd) {
app.use(serve(path.join(cwd, 'dist/client')))
}
// 省略其它代码
}这样一来,我们就解决了生产环境下静态资源失效的问题。不过,一般情况下,我们会将静态资源部上传到 CDN 上,并且将 Vite 的
base配置为域名前缀,这样我们可以通过 CDN 直接访问到静态资源,而不需要加上服务端的处理。不过作为本地的生产环境预览而言,serve-static还是一个不错的静态资源处理手段。
工程化问题
以上已经基本实现了 SSR 核心的构建和运行时功能,可以初步运行一个基于 Vite 的 SSR 项目,但在实际的场景中仍然是有不少的工程化问题需要我们注意。下面梳理一下到底需要考虑哪些问题,以及相应的解决思路是如何的,同时也会推荐一些比较成熟的解决方案。
1. 路由管理
在 SPA 场景下,对于不同的前端框架,一般会有不同的路由管理方案,如 Vue 中的 vue-router、React 的react-router。不过归根结底,路由方案在 SSR 过程中所完成的功能都是差不多的:
- 告诉框架现在渲染哪个路由。在 Vue 中我们可以通过
router.push确定即将渲染的路由,React 中则通过StaticRouter配合location参数来完成。 - 设置
base前缀。规定路径的前缀,如vue-router中 base 参数、react-router中StaticRouter组件的 basename。
2. 全局状态管理
对于全局的状态管理而言,对于不同的框架也有不同的生态和方案,比如 Vue 中的 Vuex、Pinia,React 中的 Redux、Recoil。各个状态管理工具的用法并不是本文的重点,接入 SSR 的思路也比较简单,在预取数据阶段初始化服务端的 store ,将异步获取的数据存入 store 中,然后在 拼接 HTML阶段将数据从 store 中取出放到数据 script 标签中,最后在客户端 hydrate 的时候通过 window 即可访问到预取数据。
需要注意的服务端处理许多不同的请求,对于每个请求都需要分别初始化 store,即一个请求一个 store,不然会造成全局状态污染的问题。
3. CSR 降级
在某些比较极端的情况下,我们需要降级到 CSR,也就是客户端渲染。一般而言包括如下的降级场景:
- 服务器端预取数据失败,需要降级到客户端获取数据。
- 服务器出现异常,需要返回兜底的 CSR 模板,完全降级为 CSR。
- 本地开发调试,有时需要跳过 SSR,仅进行 CSR。
对于第一种情况,在客户端入口文件中需要有重新获取数据的逻辑,我们可以进行这样的补充:
// entry-client.tsx
import React from 'react'
import ReactDOM from 'react-dom'
import './index.css'
import App from './App'
const fetchData = async () => {
// 客户端获取数据
}
const hydrate = async () => {
let data;
if (window.__SSR_DATA__) {
data = window.__SSR_DATA__;
} else {
// 降级逻辑
data = await fetchData();
}
// 也可简化为 const data = window.__SSR_DATA__ ?? await fetchData();
ReactDOM.hydrate(
<React.StrictMode>
<App data={data}/>
</React.StrictMode>,
document.getElementById('root')
)
}对于第二种场景,即服务器执行出错,我们可以在之前的 SSR 中间件逻辑追加 catch 逻辑:
async function createSsrMiddleware(app: Express): Promise<RequestHandler> {
return async (req, res, next) => {
try {
// SSR 的逻辑省略
} catch(e: any) {
vite?.ssrFixStacktrace(e);
console.error(e);
// 在这里返回浏览器 CSR 模板内容
}
}
}对于第三种情况,我们可以通过通过 ?csr 的 url query 参数来强制跳过 SSR,在 SSR 中间件添加如下逻辑:
async function createSsrMiddleware(app: Express): Promise<RequestHandler> {
return async (req, res, next) => {
try {
if (req.query?.csr) {
// 响应 CSR 模板内容
return;
}
// SSR 的逻辑省略
} catch(e: any) {
vite?.ssrFixStacktrace(e);
console.error(e);
}
}
}4. 浏览器 API 兼容
由于 Node.js 中不能使用浏览器里面诸如 window、document之类的 API,因此需要通过 i 这个 Vite 内置的环境变量来判断是否处于 SSR 环境,以此来规避业务代码在服务端出现浏览器的 API:
if (import.meta.env.SSR) {
// 服务端执行的逻辑
} else {
// 在此可以访问浏览器的 API
}我们也可以通过 polyfill 的方式,在 Node 中注入浏览器的 API,使这些 API 能够正常运行起来,解决如上的问题。推荐使用一个比较成熟的 polyfill 库 jsdom,使用方式如下:
const jsdom = require('jsdom');
const { window } = new JSDOM(`<!DOCTYPE html><p>Hello world</p>`);
const { document } = window;
// 挂载到 node 全局
global.window = window;
global.document = document;5. 自定义 Head
在 SSR 的过程中,我们虽然可以决定组件的内容,即<div id="root"></div>这个容器 div 中的内容,但对于 HTML 中head的内容我们无法根据组件的内部状态来决定,比如对于一个直播间的页面,我们需要在服务端渲染出 title 标签,title 的内容是不同主播的直播间名称,不能在代码中写死,这种情况怎么办?
React 生态中的 react-helmet 以及 Vue 生态中的 vue-meta 库就是为了解决这样的问题,让我们可以直接在组件中写一些 Head 标签,然后在服务端能够拿到组件内部的状态。这里我以一个react-helmet例子来说明:
// 前端组件逻辑
import { Helmet } from "react-helmet";
function App(props) {
const { data } = props;
return (
<div>
<Helmet>
<title>{ data.user }的页面</title>
<link rel="canonical" href="http://mysite.com/example" />
</Helmet>
</div>
)
}
// 服务端逻辑
import Helmet from 'react-helmet';
// renderToString 执行之后
const helmet = Helmet.renderStatic();
console.log("title 内容: ", helmet.title.toString());
console.log("link 内容: ", helmet.link.toString())6. 流式渲染
在不同前端框架的底层都实现了流式渲染的能力,即边渲染边响应,而不是等整个组件树渲染完毕之后再响应,这么做可以让响应提前到达浏览器,提升首屏的加载性能。Vue 中的 renderToNodeStream 和 React 中的 renderToPipeableStream 都实现了流式渲染的能力, 大致的使用方式如下:
import { renderToPipeableStream } from 'react-dom/server';
// The route handler syntax depends on your backend framework
app.use('/', (request, response) => {
const { pipe } = renderToPipeableStream(<App />, {
bootstrapScripts: ['/main.js'],
onShellReady() {
response.setHeader('content-type', 'text/html');
pipe(response);
}
});
});export default function App() {
return (
<html>
<head>
<meta charSet="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<link rel="stylesheet" href="/styles.css"></link>
<title>My app</title>
</head>
<body>
<Router />
</body>
</html>
);
}不过,流式渲染在我们带来首屏性能提升的同时,也给我们带来了一些限制: 如果我们需要在 HTML 中填入一些与组件状态相关的内容,则不能使用流式渲染。比如react-helmet中自定义的 head 内容,即便在渲染组件的时候收集到了 head 信息,但在流式渲染中,此时 HTML 的 head 部分已经发送给浏览器了,而这部分响应内容已经无法更改,因此 react-helmet 在 SSR 过程中将会失效。
7. SSR 缓存
SSR 是一种典型的 CPU 密集型操作,为了尽可能降低线上机器的负载,设置缓存是一个非常重要的环节。在 SSR 运行时,缓存的内容可以分为这么几个部分:
文件读取缓存。尽可能避免多次重复读磁盘的操作,每次磁盘 IO 尽可能地复用缓存结果。如下代码所示:
tsfunction createMemoryFsRead() { const fileContentMap = new Map(); return async (filePath) => { const cacheResult = fileContentMap.get(filePath); if (cacheResult) { return cacheResult; } const fileContent = await fs.readFile(filePath); fileContentMap.set(filePath, fileContent); return fileContent; } } const memoryFsRead = createMemoryFsRead(); memoryFsRead('file1'); // 直接复用缓存 memoryFsRead('file1');预取数据缓存。对于某些实时性不高的接口数据,我们可以采取缓存的策略,在下次相同的请求进来时复用之前预取数据的结果,这样预取数据过程的各种 IO 消耗,也可以一定程度上减少首屏时间。
HTML 渲染缓存。拼接完成的
HTML内容是缓存的重点,如果能将这部分进行缓存,那么下次命中缓存之后,将可以节省renderToString、HTML 拼接等一系列的消耗,服务端的性能收益会比较明显。
对于以上的缓存内容,具体的缓存位置可以是:
- 服务器内存。如果是放到内存中,需要考虑缓存淘汰机制,防止内存过大导致服务宕机,一个典型的缓存淘汰方案是 lru-cache (基于 LRU 算法)。
- Redis 数据库。相当于以传统后端服务器的设计思路来处理缓存。
- CDN 服务。我们可以将页面内容缓存到 CDN 服务上,在下一次相同的请求进来时,使用 CDN 上的缓存内容,而不用消费源服务器的资源。对于 CDN 上的 SSR 缓存,大家可以通过阅读这篇文章深入了解。
Vue 中另外实现了组件级别的缓存,这部分缓存一般放在内存中,可以实现更细粒度的 SSR 缓存。
8. 性能监控
在实际的 SSR 项目中,我们时常会遇到一些 SSR 线上性能问题,如果没有一个完整的性能监控机制,那么将很难发现和排查问题。对于 SSR 性能数据,有一些比较通用的指标:
- SSR 产物加载时间
- 数据预取的时间
- 组件渲染的时间
- 服务端接受请求到响应的完整时间
- SSR 缓存命中情况
- SSR 成功率、错误日志
我们可以通过perf_hooks来完成数据的采集,如下代码所示:
import { performance, PerformanceObserver } from 'perf_hooks';
// 初始化监听器逻辑
const perfObserver = new PerformanceObserver((items) => {
items.getEntries().forEach(entry => {
console.log('[performance]', entry.name, entry.duration.toFixed(2), 'ms');
});
performance.clearMarks();
});
perfObserver.observe({ entryTypes: ["measure"] })
// 接下来我们在 SSR 进行打点
// 以 renderToString 为例
performance.mark('render-start');
// renderToString 代码省略
performance.mark('render-end');
performance.measure('renderToString', 'render-start', 'render-end');启动服务后访问,可以看到日志信息。同样的,我们可以将其它阶段的指标通过上述的方式收集起来,作为性能日志;另一方面,在生产环境下,我们一般需要结合具体的性能监控平台,对上述的各项指标进行打点上报,完成线上的 SSR 性能监控服务。
9. SSG/ISR/SPR
有时候对于一些静态站点(如博客、文档),不涉及到动态变化的数据,因此我们并不需要用上服务端渲染。此时只需要在构建阶段产出完整的 HTML 进行部署即可,这种构建阶段生成 HTML 的做法也叫SSG(Static Site Generation,静态站点生成)。
SSG 与 SSR 最大的区别就是产出 HTML 的时间点从 SSR 运行时变成了构建时,但核心的生命周期流程并没有发生变化:
简单的实现代码:
// scripts/ssg.ts
// 以下的工具函数均可以从 SSR 流程复用
async function ssg() {
// 1. 加载服务端入口
const { ServerEntry, fetchData } = await loadSsrEntryModule(null);
// 2. 数据预取
const data = await fetchData();
// 3. 组件渲染
const appHtml = renderToString(React.createElement(ServerEntry, { data }));
// 4. HTML 拼接
const template = await resolveTemplatePath();
const templateHtml = await fs.readFileSync(template, 'utf-8');
const html = templateHtml
.replace('<!-- SSR_APP -->', appHtml)
.replace(
'<!-- SSR_DATA -->',
`<script>window.__SSR_DATA__=${JSON.stringify(data)}</script>`
);
// 最后,我们需要将 HTML 的内容写到磁盘中,将其作为构建产物
fs.mkdirSync('./dist/client', { recursive: true });
fs.writeFileSync('./dist/client/index.html', html);
}
ssg();接着你可以在package.json中加入这样一段 npm scripts:
{
"scripts": {
"build:ssg": "npm run build && NODE_ENV=production esno scripts/ssg.ts"
}
}这样我们便初步实现了 SSG 的逻辑。当然,除了 SSG,业界还流传着一些其它的渲染模式,诸如SPR、ISR,听起来比较高大上,但实际上只是 SSR 和 SSG 所衍生出来的新功能罢了,这里简单给大家解释一下:
- SPR即
Serverless Pre Render,即把 SSR 的服务部署到 Serverless(FaaS) 环境中,实现服务器实例的自动扩缩容,降低服务器运维的成本。 - ISR即
Incremental Site Rendering,即增量站点渲染,将一部分的 SSG 逻辑从构建时搬到了SSR运行时,解决的是大量页面 SSG 构建耗时长的问题。
模块联邦
模块联邦 (Module Federation) 代表的是一种通用的解决思路,并不局限于某一个特定的构建工具,因此,在 Vite 中我们同样可以实现这个特性,并且社区已经有了比较成熟的解决方案。
模块共享之痛
对于一个互联网产品来说,一般会有不同的细分应用,比如腾讯文档可以分为word、excel、ppt等等品类,抖音 PC 站点可以分为短视频站点、直播站点、搜索站点等子站点,而每个子站又彼此独立,可能由不同的开发团队进行单独的开发和维护,看似没有什么问题,但实际上会经常遇到一些模块共享的问题,也就是说不同应用中总会有一些共享的代码,比如公共组件、公共工具函数、公共第三方依赖等等。对于这些共享的代码,除了通过简单的复制粘贴,还有没有更好的复用手段呢?
1. 发布 npm 包
发布 npm 包是一种常见的复用模块的做法,我们可以将一些公用的代码封装为一个 npm 包,具体的发布更新流程是这样的:
公共库 lib1 改动,发布到 npm;
所有的应用安装新的依赖,并进行联调。
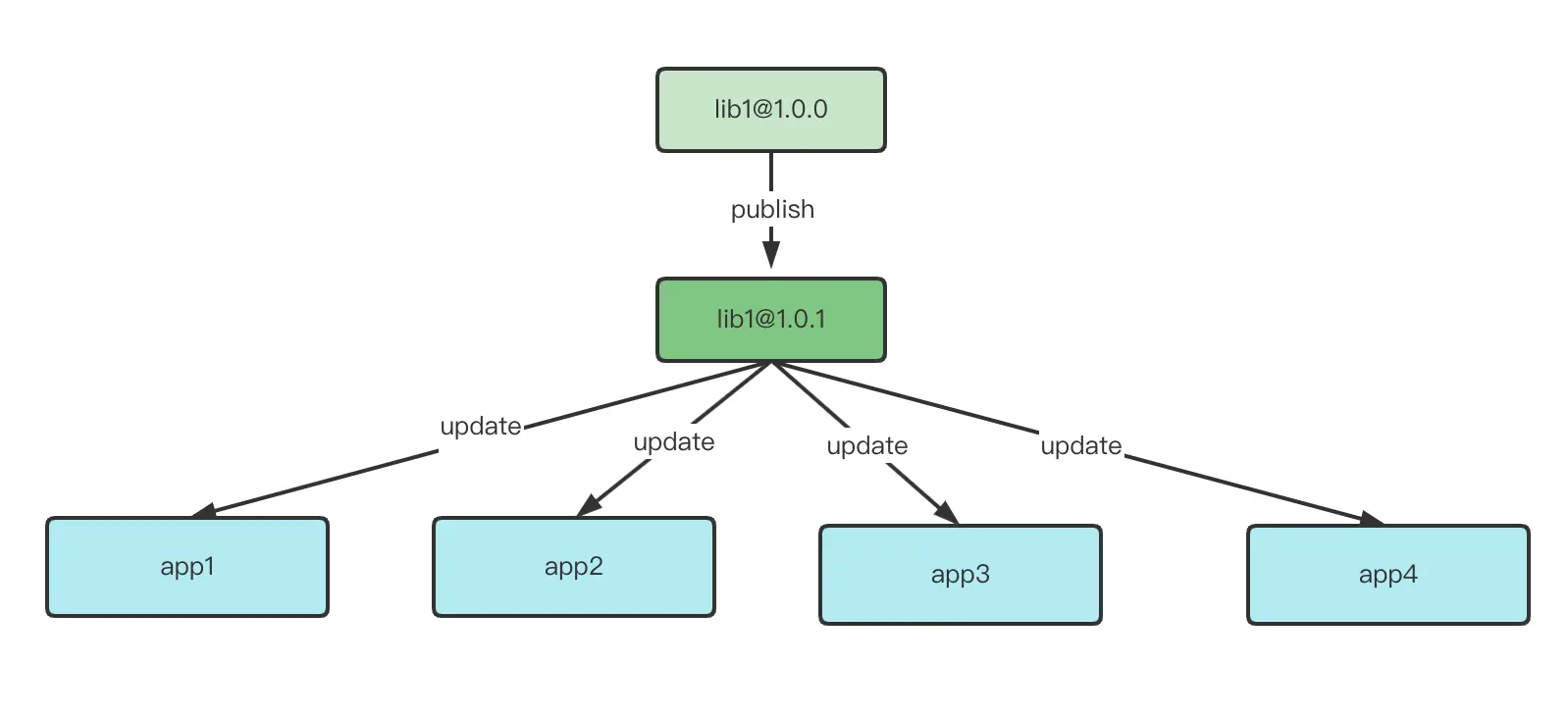
封装 npm 包可以解决模块复用的问题,但它本身又引入了新的问题:
- 开发效率问题。每次改动都需要发版,并所有相关的应用安装新依赖,流程比较复杂。
- 项目构建问题。引入了公共库之后,公共库的代码都需要打包到项目最后的产物后,导致产物体积偏大,构建速度相对较慢。
因此,这种方案并不能作为最终方案,只是暂时用来解决问题的无奈之举。
2. Git Submodule
通过 git submodule 的方式,我们可以将代码封装成一个公共的 Git 仓库,然后复用到不同的应用中,但也需要经历如下的步骤:
- 公共库 lib1 改动,提交到 Git 远程仓库;
- 所有的应用通过
git submodule命令更新子仓库代码,并进行联调。
你可以看到,整体的流程其实跟发 npm 包相差无几,仍然存在 npm 包方案所存在的各种问题。
3. 依赖外部化(external)+ CDN 引入
external的概念,即对于某些第三方依赖我们并不需要让其参与构建,而是使用某一份公用的代码。按照这个思路,我们可以在构建引擎中对某些依赖声明external,然后在 HTML 中加入依赖的 CDN 地址:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/src/favicon.svg" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Vite App</title>
</head>
<body>
<div id="root"></div>
<!-- 从 CDN 上引入第三方依赖的代码 -->
<script src="https://cdn.jsdelivr.net/npm/react@17.0.2/index.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/react-dom@17.0.2/index.min.js"></script>
</body>
</html>如上面的例子所示,我们可以对react和react-dom使用 CDN 的方式引入,一般使用UMD格式产物,这样不同的项目间就可以通过window.React来使用同一份依赖的代码了,从而达到模块复用的效果。不过在实际的使用场景,这种方案的局限性也很突出:
- 兼容性问题。并不是所有的依赖都有 UMD 格式的产物,因此这种方案不能覆盖所有的第三方 npm 包。
- 依赖顺序问题。我们通常需要考虑间接依赖的问题,如对于 antd 组件库,它本身也依赖了
react和moment,那么react和moment也需要external,并且在 HTML 中引用这些包,同时也要严格保证引用的顺序,比如说moment如果放在了antd后面,代码可能无法运行。而第三方包背后的间接依赖数量一般很庞大,如果逐个处理,对于开发者来说简直就是噩梦。 - 产物体积问题。由于依赖包被声明
external之后,应用在引用其 CDN 地址时,会全量引用依赖的代码,这种情况下就没有办法通过 Tree Shaking 来去除无用代码了,会导致应用的性能有所下降。
4. Monorepo
作为一种新的项目管理方式,Monorepo 也可以很好地解决模块复用的问题。在 Monorepo 架构下,多个项目可以放在同一个 Git 仓库中,各个互相依赖的子项目通过软链的方式进行调试,代码复用显得非常方便,如果有依赖的代码变动,那么用到这个依赖的项目当中会立马感知到。
不得不承认,对于应用间模块复用的问题,Monorepo 是一种非常优秀的解决方案,但与此同时,它也给团队带来了一些挑战:
- 所有的应用代码必须放到同一个仓库。如果是旧有项目,并且每个应用使用一个 Git 仓库的情况,那么使用 Monorepo 之后项目架构调整会比较大,也就是说改造成本会相对比较高。
- Monorepo 本身也存在一些天然的局限性。如项目数量多起来之后依赖安装时间会很久、项目整体构建时间会变长等等,我们也需要去解决这些局限性所带来的的开发效率问题。而这项工作一般需要投入专业的人去解决,如果没有足够的人员投入或者基建的保证,Monorepo 可能并不是一个很好的选择。
- 项目构建问题。跟
发 npm 包的方案一样,所有的公共代码都需要进入项目的构建流程中,产物体积还是会偏大。
MF 核心概念
模块联邦中主要有两种模块: 本地模块和远程模块。
本地模块即为普通模块,是当前构建流程中的一部分,而远程模块不属于当前构建流程,在本地模块的运行时进行导入,同时本地模块和远程模块可以共享某些依赖的代码,如下图所示:
值得强调的是,在模块联邦中,每个模块既可以是本地模块,导入其它的远程模块,又可以作为远程模块,被其他的模块导入。如下面这个例子所示:
以上就是模块联邦的主要设计原理,现在我们来好好分析一下这种设计究竟有哪些优势:
- 实现任意粒度的模块共享。这里所指的模块粒度可大可小,包括第三方 npm 依赖、业务组件、工具函数,甚至可以是整个前端应用!而整个前端应用能够共享产物,代表着各个应用单独开发、测试、部署,这也是一种
微前端的实现。 - 优化构建产物体积。远程模块可以从本地模块运行时被拉取,而不用参与本地模块的构建,可以加速构建过程,同时也能减小构建产物。
- 运行时按需加载。远程模块导入的粒度可以很小,如果你只想使用 app1 模块的
add函数,只需要在 app1 的构建配置中导出这个函数,然后在本地模块中按照诸如import('app1/add')的方式导入即可,这样就很好地实现了模块按需加载。 - 第三方依赖共享。通过模块联邦中的共享依赖机制,我们可以很方便地实现在模块间公用依赖代码,从而避免以往的
external + CDN引入方案的各种问题。
从以上的分析你可以看到,模块联邦近乎完美地解决了以往模块共享的问题,甚至能够实现应用级别的共享,进而达到微前端的效果。下面,我们就来以具体的例子来学习在 Vite 中如何使用模块联邦的能力。
MF 应用实战
社区中已经提供了一个比较成熟的 Vite 模块联邦方案: vite-plugin-federation,这个方案基于 Vite(或者 Rollup) 实现了完整的模块联邦能力。接下来,我们基于它来实现模块联邦应用。
首先初始化两个 Vue 的脚手架项目host和remote,然后分别安装vite-plugin-federation插件:
pnpm install @originjs/vite-plugin-federation -D配置文件中分别加入如下的配置:
// 远程模块配置
// remote/vite.config.ts
import { defineConfig } from "vite";
import vue from "@vitejs/plugin-vue";
import federation from "@originjs/vite-plugin-federation";
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
vue(),
// 模块联邦配置
federation({
name: "remote_app",
filename: "remoteEntry.js",
// 导出模块声明
exposes: {
"./Button": "./src/components/Button.js",
"./App": "./src/App.vue",
"./utils": "./src/utils.ts",
},
// 共享依赖声明
shared: ["vue"],
}),
],
// 打包配置
build: {
target: "esnext",
},
});
// 本地模块配置
// host/vite.config.ts
import { defineConfig } from "vite";
import vue from "@vitejs/plugin-vue";
import federation from "@originjs/vite-plugin-federation";
export default defineConfig({
plugins: [
vue(),
federation({
// 远程模块声明
remotes: {
remote_app: "http://localhost:3001/assets/remoteEntry.js",
},
// 共享依赖声明
shared: ["vue"],
}),
],
build: {
target: "esnext",
},
});在如上的配置中,我们完成了远程模块的模块导出及远程模块在本地模块的注册。
使用远程模块,首先我们需要对远程模块进行打包,在 remote 路径下依赖执行:
# 打包产物
pnpm run build
# 模拟部署效果,一般会在生产环境将产物上传到 CDN
npx vite preview --port=3001 --strictPort然后我们在 host项目中使用远程模块:
<script setup lang="ts">
import HelloWorld from "./components/HelloWorld.vue";
import { defineAsyncComponent } from "vue";
// 导入远程模块
// 1. 组件
import RemoteApp from "remote_app/App";
// 2. 工具函数
import { add } from "remote_app/utils";
// 3. 异步组件
const AysncRemoteButton = defineAsyncComponent(
() => import("remote_app/Button")
);
const data: number = add(1, 2);
</script>
<template>
<div>
<img alt="Vue logo" src="./assets/logo.png" />
<HelloWorld />
<RemoteApp />
<AysncRemoteButton />
<p>应用 2 工具函数计算结果: 1 + 2 = {{ data }}</p>
</div>
</template>
<style>
#app {
font-family: Avenir, Helvetica, Arial, sans-serif;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
text-align: center;
color: #2c3e50;
margin-top: 60px;
}
</style>启动项目后你可以看到如下的结果:

应用 2 的组件和工具函数逻辑已经在应用 1 中生效,也就是说,我们完成了远程模块在本地模块的运行时引入。
让我们来梳理一下整体的使用流程:
- 远程模块通过
exposes注册导出的模块,本地模块通过remotes注册远程模块地址。 - 远程模块进行构建,并部署到云端。
- 本地通过
import '远程模块名称/xxx'的方式来引入远程模块,实现运行时加载。
当然,还有几个要点需要给大家补充一下:
- 在模块联邦中的配置中,
exposes和remotes参数其实并不冲突,也就是说一个模块既可以作为本地模块,又可以作为远程模块。 - 由于 Vite 的插件机制与 Rollup 兼容,
vite-plugin-federation方案在 Rollup 中也是完全可以使用的。
MF 实现原理
Module Federation 使用比较简单,对已有项目来说改造成本并不大。那么,这么强大而易用的特性是如何在 Vite 中得以实现的呢?接下来,我们来深入探究一下 MF 背后的实现原理,分析vite-plugin-federation这个插件背后究竟做了些什么。
总体而言,实现模块联邦有三大主要的要素:
- Host模块: 即本地模块,用来消费远程模块。
- Remote模块: 即远程模块,用来生产一些模块,并暴露运行时容器供本地模块消费。
- Shared依赖: 即共享依赖,用来在本地模块和远程模块中实现第三方依赖的共享。
首先,我们来看看本地模块是如何消费远程模块的。之前,我们在本地模块中写过这样的引入语句:
import RemoteApp from "remote_app/App";Vite 编译后的代码:
// 为了方便阅读,以下部分方法的函数名进行了简化
// 远程模块表
const remotesMap = {
'remote_app':{url:'http://localhost:3001/assets/remoteEntry.js',format:'esm',from:'vite'},
'shared':{url:'vue',format:'esm',from:'vite'}
};
async function ensure() {
const remote = remoteMap[remoteId];
// 做一些初始化逻辑,暂时忽略
// 返回的是运行时容器
}
async function getRemote(remoteName, componentName) {
return ensure(remoteName)
// 从运行时容器里面获取远程模块
.then(remote => remote.get(componentName))
.then(factory => factory());
}
// import 语句被编译成了这样
// tip: es2020 产物语法已经支持顶层 await
const __remote_appApp = await getRemote("remote_app" , "./App");除了 import 语句被编译之外,在代码中还添加了 remoteMap 和一些工具函数,它们的目的很简单,就是通过访问远端的运行时容器来拉取对应名称的模块。
而运行时容器其实就是指远程模块打包产物 remoteEntry.js 的导出对象,我们来看看它的逻辑是怎样的:
// remoteEntry.js
const moduleMap = {
"./Button": () => {
return import('./__federation_expose_Button.js').then(module => () => module)
},
"./App": () => {
dynamicLoadingCss('./__federation_expose_App.css');
return import('./__federation_expose_App.js').then(module => () => module);
},
'./utils': () => {
return import('./__federation_expose_Utils.js').then(module => () => module);
}
};
// 加载 css
const dynamicLoadingCss = (cssFilePath) => {
const metaUrl = import.meta.url;
if (typeof metaUrl == 'undefined') {
console.warn('The remote style takes effect only when the build.target option in the vite.config.ts file is higher than that of "es2020".');
return
}
const curUrl = metaUrl.substring(0, metaUrl.lastIndexOf('remoteEntry.js'));
const element = document.head.appendChild(document.createElement('link'));
element.href = curUrl + cssFilePath;
element.rel = 'stylesheet';
};
// 关键方法,暴露模块
const get =(module) => {
return moduleMap[module]();
};
const init = () => {
// 初始化逻辑,用于共享模块,暂时省略
}
export { dynamicLoadingCss, get, init }从运行时容器的代码中我们可以得出一些关键的信息:
moduleMap用来记录导出模块的信息,所有在exposes参数中声明的模块都会打包成单独的文件,然后通过dynamic import进行导入。- 容器导出了十分关键的
get方法,让本地模块能够通过调用这个方法来访问到该远程模块。
至此,我们就梳理清楚了远程模块的运行时容器与本地模块的交互流程,如下图所示
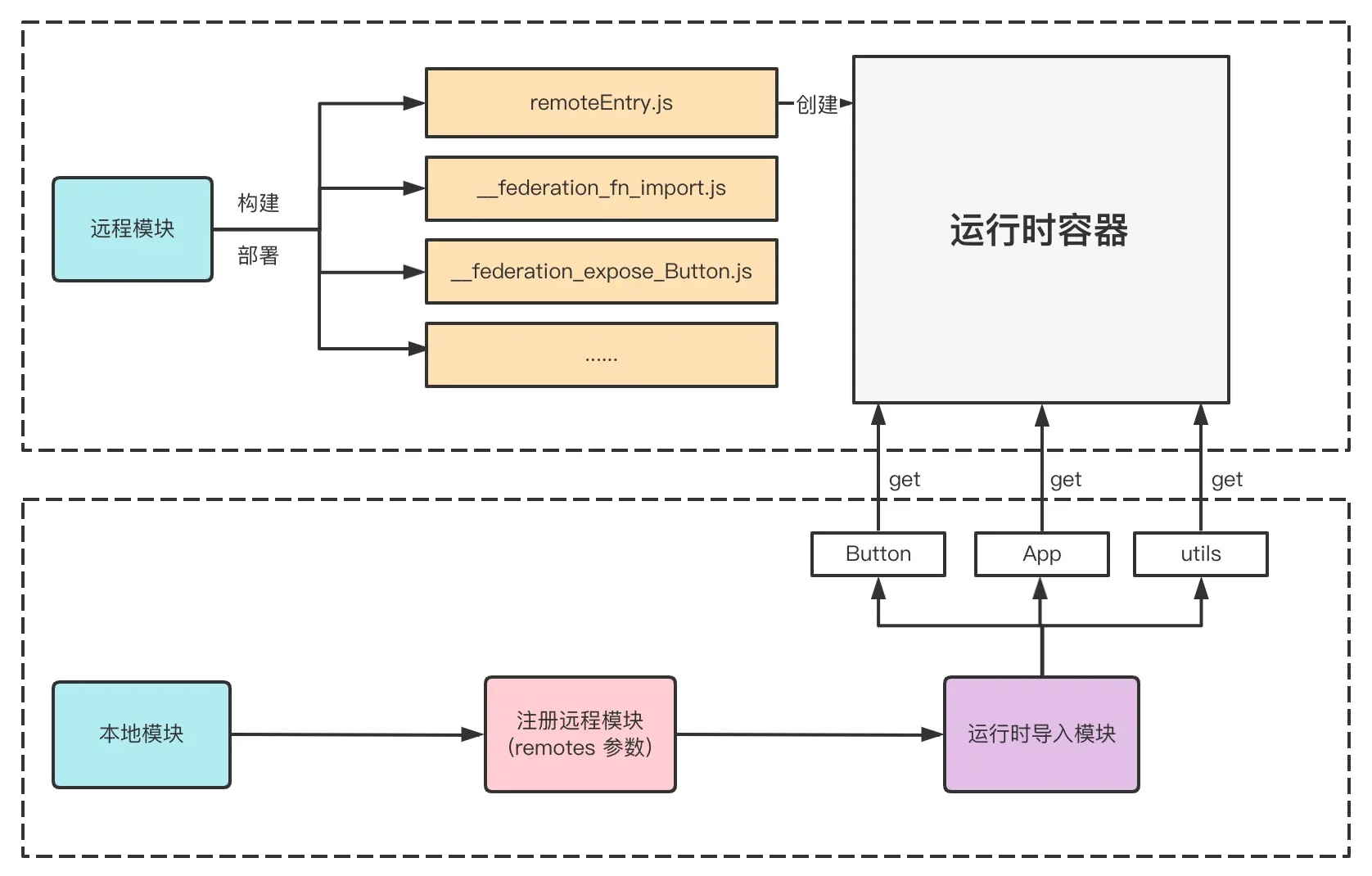
接下来,我们继续分析共享依赖的实现。拿之前的示例项目来说,本地模块设置了shared: ['vue']参数之后,当它执行远程模块代码的时候,一旦遇到了引入vue的情况,会优先使用本地的 vue,而不是远端模块中的vue。
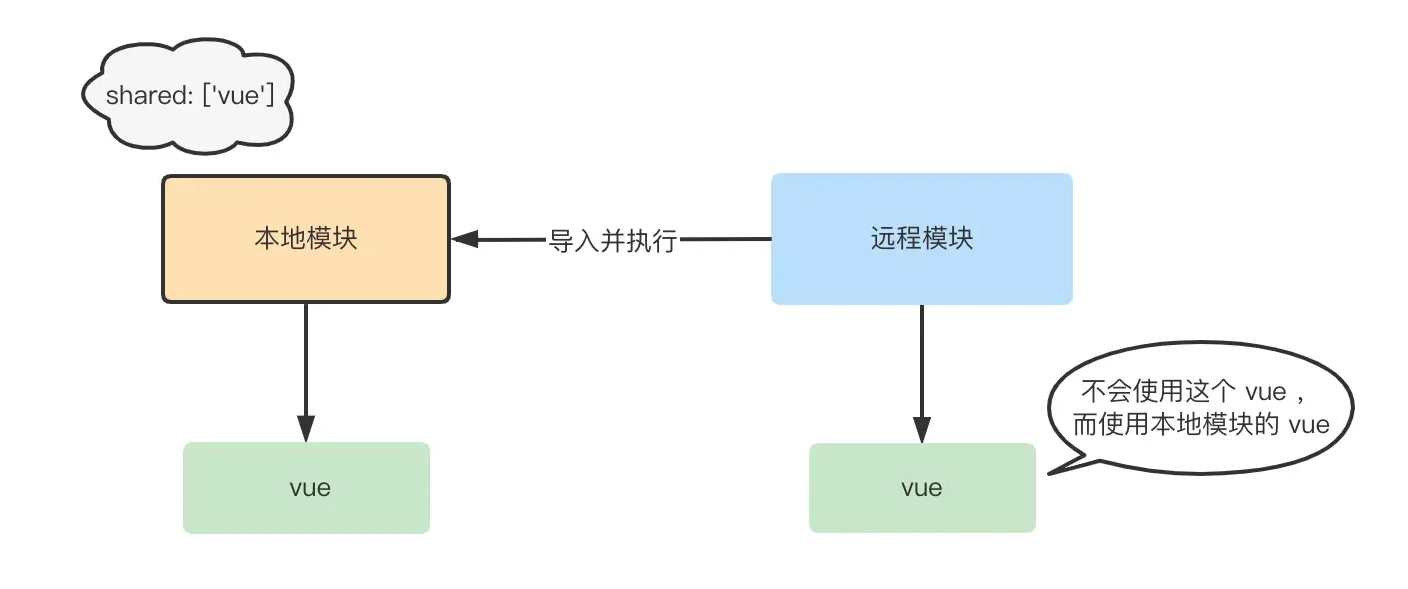
让我们把焦点放到容器初始化的逻辑中,回到本地模块编译后的ensure函数逻辑:
// host
// 下面是共享依赖表。每个共享依赖都会单独打包
const shareScope = {
'vue':{'3.2.31':{get:()=>get('./__federation_shared_vue.js'), loaded:1}}
};
async function ensure(remoteId) {
const remote = remotesMap[remoteId];
if (remote.inited) {
return new Promise(resolve => {
if (!remote.inited) {
remote.lib = window[remoteId];
remote.lib.init(shareScope);
remote.inited = true;
}
resolve(remote.lib);
});
}
}可以发现,ensure函数的主要逻辑是将共享依赖信息传递给远程模块的运行时容器,并进行容器的初始化。接下来我们进入容器初始化的逻辑init中:
const init =(shareScope) => {
globalThis.__federation_shared__= globalThis.__federation_shared__|| {};
// 下面的逻辑大家不用深究,作用很简单,就是将本地模块的`共享模块表`绑定到远程模块的全局 window 对象上
Object.entries(shareScope).forEach(([key, value]) => {
const versionKey = Object.keys(value)[0];
const versionValue = Object.values(value)[0];
const scope = versionValue.scope || 'default';
globalThis.__federation_shared__[scope] = globalThis.__federation_shared__[scope] || {};
const shared= globalThis.__federation_shared__[scope];
(shared[key] = shared[key]||{})[versionKey] = versionValue;
});
};当本地模块的共享依赖表能够在远程模块访问时,远程模块内也就能够使用本地模块的依赖(如 vue)了。现在我们来看看远程模块中对于import { h } from 'vue'这种引入代码被转换成了什么样子:
// __federation_expose_Button.js
import {importShared} from './__federation_fn_import.js'
const { h } = await importShared('vue')不难看到,第三方依赖模块的处理逻辑都集中到了 importShared 函数,让我们来一探究竟:
// __federation_fn_import.js
const moduleMap= {
'vue': {
get:()=>()=>__federation_import('./__federation_shared_vue.js'),
import:true
}
};
// 第三方模块缓存
const moduleCache = Object.create(null);
async function importShared(name,shareScope = 'default') {
return moduleCache[name] ?
new Promise((r) => r(moduleCache[name])) :
getProviderSharedModule(name, shareScope);
}
async function getProviderSharedModule(name, shareScope) {
// 从 window 对象中寻找第三方包的包名,如果发现有挂载,则获取本地模块的依赖
if (xxx) {
return await getHostDep();
} else {
return getConsumerSharedModule(name);
}
}
async function getConsumerSharedModule(name , shareScope) {
if (moduleMap[name]?.import) {
const module = (await moduleMap[name].get())();
moduleCache[name] = module;
return module;
} else {
console.error(`consumer config import=false,so cant use callback shared module`);
}
}由于远程模块运行时容器初始化时已经挂载了共享依赖的信息,远程模块内部可以很方便的感知到当前的依赖是不是共享依赖,如果是共享依赖则使用本地模块的依赖代码,否则使用远程模块自身的依赖产物代码。可以参考下面的流程图学习:

ESM 高阶特性 & Pure ESM 时代
Vite 本身是借助浏览器原生的 ESM 解析能力(type="module")实现了开发阶段的 no-bundle,即不用打包也可以构建 Web 应用。不过我们对于原生 ESM 的理解仅仅停留在 type="module" 这个特性上面未免有些狭隘了,一方面浏览器和 Node.js 各自提供了不同的 ESM 使用特性,如 import maps、package.json 的 imports 和 exports 属性等等,另一方面前端社区开始逐渐向 ESM 过渡,有的包甚至仅留下 ESM 产物,Pure ESM 的概念随之席卷前端圈,而与此同时,基于 ESM 的 CDN 基础设施也如雨后春笋般不断涌现,诸如esm.sh、skypack、jspm等等。
高阶特性
1. import map
在浏览器中我们可以使用包含type="module"属性的script标签来加载 ES 模块,而模块路径主要包含三种:
- 绝对路径,如
https://cdn.skypack.dev/react - 相对路径,如
./module-a bare import即直接写一个第三方包名,如react、lodash
对于前两种模块路径浏览器是原生支持的,而对于 bare import,在 Node.js 能直接执行,因为 Node.js 的路径解析算法会从项目的 node_modules 找到第三方包的模块路径,但是放在浏览器中无法直接执行。
现代浏览器内置的 import map 就是为了解决上述的问题,我们可以用一个简单的例子来使用这个特性:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="root"></div>
<script type="importmap">
{
"imports": {
"react": "https://cdn.skypack.dev/react"
}
}
</script>
<script type="module">
import React from 'react';
console.log(React)
</script>
</body>
</html>在浏览器中执行这个 HTML,如果正常执行,那么你可以看到浏览器已经从网络中获取了 react 的内容。
注意: import map 可能存在浏览器兼容性问题,这里出现浏览器报错也属于正常情况,后文会介绍解决方案。
在支持 import map 的浏览器中,在遇到type="importmap"的 script 标签时,浏览器会记录下第三方包的路径映射表,在遇到bare import时会根据这张表拉取远程的依赖代码。如上述的例子中,我们使用 skypack 这个第三方的 ESM CDN 服务,通过 https://cdn.skypack.dev/react 这个地址我们可以拿到 React 的 ESM 格式产物。
import map 特性虽然简洁方便,但浏览器的兼容性却是个大问题,它只能兼容市面上 68% 左右的浏览器份额,而反观type="module"的兼容性(兼容 95% 以上的浏览器),import map的兼容性实属不太乐观。但幸运的是,社区已经有了对应的 Polyfill 解决方案:es-module-shims,完整地实现了包含 import map在内的各大 ESM 特性,还包括:
- dynamic import。即动态导入,部分老版本的 Firefox 和 Edge 不支持。
- i
mport.meta和i 。当前模块的元信息,类似 Node.js 中的mport.meta.url __dirname、__filename。 - module preload。以前我们会在 link 标签中加上
rel="preload"来进行资源预加载,即在浏览器解析 HTML 之前就开始加载资源,现在对于 ESM 也有对应的module preload来支持这个行为。 - JSON Modules和 CSS Modules。即通过如下方式来引入
json或者css:html<script type="module"> // 获取 json 对象 import json from 'https://site.com/data.json' assert { type: 'json' }; // 获取 CSS Modules 对象 import sheet from 'https://site.com/sheet.css' assert { type: 'css' }; </script>
es-module-shims 基于 wasm 实现,性能并不差,相比浏览器原生的行为没有明显的性能下降。import map虽然并没有得到广泛浏览器的原生支持,但是我们仍然可以通过 Polyfill 的方式在支持 type="module" 的浏览器中使用 import map。
2. Nodejs 包导入导出策略
在 Node.js 中(>=12.20 版本)有一般如下几种方式可以使用原生 ES Module:
- 文件以
.mjs结尾; - package.json 中声明
type: "module"。
那么,Nodejs 在处理 ES Module 导入导出的时候,如果是处理 npm 包级别的情况,其中的细节可能比你想象中更加复杂。
首先来看看如何导出一个包,你有两种方式可以选择: main和 exports属性。这两个属性均来自于package.json,并且根据 Node 官方的 resolve 算法(查看详情),exports 的优先级比 main 更高,也就是说如果你同时设置了这两个属性,那么 exports会优先生效。
main 的使用比较简单,设置包的入口文件路径即可,如:
"main": "./dist/index.js"需要重点梳理的是exports属性,它包含了多种导出形式: 默认导出、子路径导出和条件导出,这些导出形式如以下的代码所示:
// package.json
{
"name": "package-a",
"type": "module",
"exports": {
// 默认导出,使用方式: import a from 'package-a'
".": "./dist/index.js",
// 子路径导出,使用方式: import d from 'package-a/dist'
"./dist": "./dist/index.js",
"./dist/*": "./dist/*", // 这里可以使用 `*` 导出目录下所有的文件
// 条件导出,区分 ESM 和 CommonJS 引入的情况
"./main":{
"import":"./main.js",
"require":"./main.cjs"
}
}
}其中,条件导出可以包括如下常见的属性:
- node: 在 Node.js 环境下适用,可以定义为嵌套条件导出,如:json
{ "exports":[ { ".": { "node": { "import": "./main.js", "require": "./main.cjs" } } } ] } - import: 用于 import 方式导入的情况,如
import("package-a"); - require: 用于 require 方式导入的情况,如
require("package-a"); - default,兜底方案,如果前面的条件都没命中,则使用 default 导出的路径。
当然,条件导出还包含 types、browser、development、production 等属性,大家可以参考 Node.js 的详情文档。
package.json 中的 imports 字段表示导入,一般是这样声明的:
{
"imports": {
// key 一般以 # 开头
// 也可以直接赋值为一个字符串: "#dep": "lodash-es"
"#dep": {
"node": "lodash-es",
"default": "./dep-polyfill.js"
}
},
"dependencies": {
"lodash-es": "^4.17.21"
}
}这样你可以在自己的包中使用下面的 import 语句:
// index.js
import { cloneDeep } from "#dep";
const obj = { a: 1 };
// { a: 1 }
console.log(cloneDeep(obj));Node.js 在执行的时候会将#dep定位到lodash-es这个第三方包,当然,你也可以将其定位到某个内部文件。这样相当于实现了路径别名的功能,不过与构建工具中的 alias 功能不同的是,"imports" 中声明的别名必须全量匹配,否则 Node.js 会直接抛错。
Pure ESM
Pure ESM 的概念有两层含义,一个是让 npm 包都提供 ESM 格式的产物,另一个是仅留下 ESM 产物,抛弃 CommonJS 等其它格式产物。
1. 对 Pure ESM 的态度
社区中的很多 npm 包已经出现了 ESM First 的趋势,可以预见的是越来越多的包会提供 ESM 的版本,来拥抱社区 ESM 大一统的趋势,同时也有一部分的 npm 包做得更加激进,直接采取Pure ESM模式,如大名鼎鼎的chalk和imagemin,最新版本中只提供 ESM 产物,而不再提供 CommonJS 产物。
对于没有上层封装需求的大型框架,如 Nuxt、Umi,在保证能上
Pure ESM的情况下,直接上不会有什么问题;但如果是一个底层基础库,最好提供好 ESM 和 CommonJS 两种格式的产物。
在 ESM 中,我们可以直接导入 CommonJS 模块,如:
// react 仅有 CommonJS 产物
import React from 'react';
console.log(React)Node.js 执行以上的原生 ESM 代码并没有问题,但反过来,如果你想在 CommonJS 中 require 一个 ES 模块,就行不通了,原因在于 require 是同步加载的,而 ES 模块本身具有异步加载的特性,因此两者天然互斥,即我们无法 require 一个 ES 模块。
但是我们可以通过 dynamic import 来引入:
async function init() {
const {default: chalk} = await import("chalk")
console.log(chalk.green("hello world"))
}
init()不过为了引入一个 ES 模块,我们必须要将原来同步的执行环境改为异步的,这就带来如下的几个问题:
- 如果执行环境不支持异步,CommonJS 将无法导入 ES 模块;
- jest 中不支持导入 ES 模块,测试会比较困难;
- 在 tsc 中,对于
await import()语法会强制编译成require的语法(详情),只能靠eval('await import()')绕过去。
总而言之,CommonJS 中导入 ES 模块比较困难。因此,如果一个基础底层库使用 Pure ESM,那么潜台词相当于你依赖这个库时(可能是直接依赖,也有可能是间接依赖),你自己的库/应用的产物最好为 ESM 格式。也就是说,Pure ESM是具有传染性的,底层的库出现了 Pure ESM 产物,那么上层的使用方也最好是 Pure ESM,否则会有上述的种种限制。
但从另一个角度来看,对于大型框架(如 Nuxt)而言,基本没有二次封装的需求,框架本身如果能够使用 Pure ESM ,那么也能带动社区更多的包(比如框架插件)走向 Pure ESM,同时也没有上游调用方的限制,反而对社区 ESM 规范的推动是一件好事情。
当然,上述的结论也带来了一个潜在的问题: 大型框架毕竟很有限,npm 上大部分的包还是属于基础库的范畴,那对于大部分包,我们采用导出 ESM/CommonJS 两种产物的方案,会不会对项目的语法产生限制呢?
我们知道,在 ESM 中无法使用 CommonJS 中的 __dirname、__filename、require.resolve 等全局变量和方法,同样的,在 CommonJS 中我们也没办法使用 ESM 专有的 i对象,那么如果要提供两种产物格式,这些模块规范相关的语法怎么处理呢?
在传统的编译构建工具中,我们很难逃开这个问题,但新一代的基础库打包器 tsup 给了我们解决方案。
2. 新一代的基础库打包器
tsup 是一个基于 Esbuild 的基础库打包器,主打无配置(no config)打包。借助它我们可以轻易地打出 ESM 和 CommonJS 双格式的产物,并且可以任意使用与模块格式强相关的一些全局变量或者 API,比如某个库的源码如下:
export interface Options {
data: string;
}
export function init(options: Options) {
console.log(options);
console.log(import.meta.url);
}由于代码中使用了 i 对象,这是仅在 ESM 下存在的变量,而经过 tsup 打包后的 CommonJS 版本却被转换成了下面这样:
var getImportMetaUrl = () =>
typeof document === "undefined"
? new URL("file:" + __filename).href
: (document.currentScript && document.currentScript.src) ||
new URL("main.js", document.baseURI).href;
var importMetaUrl = /* @__PURE__ */ getImportMetaUrl();
// src/index.ts
function init(options) {
console.log(options);
console.log(importMetaUrl);
}可以看到,ESM 中的 API 被转换为 CommonJS 对应的格式,反之也是同理。最后,我们可以借助之前提到的条件导出,将 ESM、CommonJS 的产物分别进行导出,如下所示:
{
"scripts": {
"watch": "npm run build -- --watch src",
"build": "tsup ./src/index.ts --format cjs,esm --dts --clean"
},
"exports": {
".": {
"import": "./dist/index.mjs",
"require": "./dist/index.js",
// 导出类型
"types": "./dist/index.d.ts"
}
}
}tsup 在解决了双格式产物问题的同时,本身利用 Esbuild 进行打包,性能非常强悍,也能生成类型文件,同时也弥补了 Esbuild 没有类型系统的缺点,还是非常推荐大家使用的。
性能优化
一、网络优化
1. HTTP2
传统的 HTTP 1.1 存在队头阻塞的问题,同一个 TCP 管道中同一时刻只能处理一个 HTTP 请求,也就是说如果当前请求没有处理完,其它的请求都处于阻塞状态,另外浏览器对于同一域名下的并发请求数量都有限制,比如 Chrome 中只允许 6 个请求并发(这个数量不允许用户配置),也就是说请求数量超过 6 个时,多出来的请求只能排队、等待发送。
因此,在 HTTP 1.1 协议中,队头阻塞和请求排队问题很容易成为网络层的性能瓶颈。而 HTTP 2 的诞生就是为了解决这些问题,它主要实现了如下的能力:
- 多路复用。将数据分为多个二进制帧,多个请求和响应的数据帧在同一个 TCP 通道进行传输,解决了之前的队头阻塞问题。而与此同时,在 HTTP2 协议下,浏览器不再有同域名的并发请求数量限制,因此请求排队问题也得到了解决。
- Server Push,即服务端推送能力。可以让某些资源能够提前到达浏览器,比如对于一个 html 的请求,通过 HTTP 2 我们可以同时将相应的 js 和 css 资源推送到浏览器,省去了后续请求的开销。
在 Vite 中,我们可以通过vite-plugin-mkcert在本地 Dev Server 上开启 HTTP2:
pnpm i vite-plugin-mkcert -D然后在 Vite 配置中进行使用:
// vite.config.ts
import { defineConfig } from "vite";
import react from "@vitejs/plugin-react";
import mkcert from "vite-plugin-mkcert";
export default defineConfig({
plugins: [react(), mkcert()],
server: {
// https 选项需要开启
https: true,
},
});插件的原理也比较简单,由于 HTTP2 依赖 TLS 握手,插件会帮你自动生成 TLS 证书,然后支持通过 HTTPS 的方式启动,而 Vite 会自动把 HTTPS 服务升级为 HTTP2。
其中有一个特例,即当你使用 Vite 的 proxy 配置时,Vite 会将 HTTP2 降级为 HTTPS,不过这个问题你可以通过vite-plugin-proxy-middleware插件解决。
2. DNS 预解析
浏览器在向跨域的服务器发送请求时,首先会进行 DNS 解析,将服务器域名解析为对应的 IP 地址。我们通过 dns-prefetch 技术将这一过程提前,降低 DNS 解析的延迟时间,具体使用方式如下:
<!-- href 为需要预解析的域名 -->
<link rel="dns-prefetch" href="https://fonts.googleapis.com/">一般情况下 dns-prefetch 会与 preconnect 搭配使用,前者用来解析 DNS,而后者用来会建立与服务器的连接,建立 TCP 通道及进行 TLS 握手,进一步降低请求延迟。使用方式如下所示:
<link rel="preconnect" href="https://fonts.gstatic.com/" crossorigin>
<link rel="dns-prefetch" href="https://fonts.gstatic.com/">值得注意的是,对于 preconnect 的 link 标签一般需要加上 crorssorigin(跨域标识),否则对于一些字体资源 preconnect 会失效。
3. Preload/Prefetch
对于一些比较重要的资源,我们可以通过 Preload 方式进行预加载,即在资源使用之前就进行加载,而不是在用到的时候才进行加载,这样可以使资源更早地到达浏览器。具体使用方式如下:
<link rel="preload" href="style.css" as="style">
<link rel="preload" href="main.js" as="script">与普通 script 标签不同的是,对于原生 ESM 模块,浏览器提供了 modulepreload 来进行预加载:
<link rel="modulepreload" href="/src/app.js" />不过在 Vite 中我们可以通过配置一键开启 modulepreload 的 Polyfill,从而在使所有支持原生 ESM 的浏览器(占比 90% 以上)都能使用该特性,配置方式如下:
// vite.config.ts
export default {
build: {
polyfillModulePreload: true
}
}除了 Preload,Prefetch 也是一个比较常用的优化方式,它相当于告诉浏览器空闲的时候去预加载其它页面的资源,比如对于 A 页面中插入了这样的 link 标签:
<link rel="prefetch" href="https://B.com/index.js" as="script">这样浏览器会在 A 页面加载完毕之后去加载B这个域名下的资源,如果用户跳转到了B页面中,浏览器会直接使用预加载好的资源,从而提升 B 页面的加载速度。而相比 Preload, Prefetch 的浏览器兼容性不太乐观。
二、资源优化
1. 产物分析报告
为了能可视化地感知到产物的体积情况,推荐大家用 rollup-plugin-visualizer 来进行产物分析。使用方式如下:
// 注: 首先需要安装 rollup-plugin-visualizer 依赖
import { defineConfig } from "vite";
import react from "@vitejs/plugin-react";
import { visualizer } from "rollup-plugin-visualizer";
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
react(),
visualizer({
// 打包完成后自动打开浏览器,显示产物体积报告
open: true,
}),
],
});当你执行pnpm run build之后,浏览器会自动打开产物分析页面。
2. 资源压缩
在生产环境中,为了极致的代码体积,我们一般会通过构建工具来对产物进行压缩。具体来说,有这样几类资源可以被压缩处理: JavaScript 代码、CSS 代码和图片文件。
JavaScript 压缩
在 Vite 生产环境构建的过程中,JavaScript 产物代码会自动进行压缩,相关的配置参数如下:
ts// vite.config.ts export default { build: { // 类型: boolean | 'esbuild' | 'terser' // 默认为 `esbuild` minify: 'esbuild', // 产物目标环境 target: 'modules', // 如果 minify 为 terser,可以通过下面的参数配置具体行为 // https://terser.org/docs/api-reference#minify-options terserOptions: {} } }target参数是压缩产物的目标环境。Vite 默认的参数是modules,即如下的browserlist:ts['es2019', 'edge88', 'firefox78', 'chrome87', 'safari13.1']其实,对于 JS 代码压缩的理解仅仅停留在去除空行、混淆变量名的层面是不够的,为了达到极致的压缩效果,压缩器一般会根据浏览器的目标,会对代码进行语法层面的转换,比如下面这个例子:
ts// 业务代码中 info == null ? undefined : info.name如果你将
target配置为exnext,也就是最新的 JS 语法,会发现压缩后的代码变成了下面这样:tsinfo?.name这就是压缩工具在背后所做的事情,将某些语句识别之后转换成更高级的语法,从而达到更优的代码体积。
因此,设置合适的
target就显得特别重要了,一旦目标环境的设置不能覆盖所有的用户群体,那么极有可能在某些低端浏览器中出现语法不兼容问题,从而发生线上事故。因此,为了线上的稳定性,推荐大家最好还是将 target 参数设置为
ECMA语法的最低版本es2015/es6。CSS 压缩
对于 CSS 代码的压缩,Vite 中的相关配置如下:
ts// vite.config.ts export default { build: { // 设置 CSS 的目标环境 cssTarget: '' } }默认情况下 Vite 会使用 Esbuild 对 CSS 代码进行压缩,一般不需要我们对
cssTarget进行配置。不过在需要兼容安卓端微信的 webview 时,我们需要将
build.cssTarget设置为chrome61,以防止 vite 将rgba()颜色转化为#RGBA十六进制符号的形式,出现样式问题。图片压缩
图片资源是一般是产物体积的大头,如果能有效地压缩图片体积,那么对项目体积来说会得到不小的优化。而在 Vite 中我们一般使用
vite-plugin-imagemin来进行图片压缩。产物拆包
一般来说,如果不对产物进行
代码分割(或者拆包),全部打包到一个 chunk 中,会产生如下的问题:- 首屏加载的代码体积过大,即使是当前页面不需要的代码也会进行加载。
- 线上缓存复用率极低,改动一行代码即可导致整个 bundle 产物缓存失效。
而 Vite 中内置如下的代码拆包能力:
- CSS 代码分割,即实现一个 chunk 对应一个 css 文件。
- 默认有一套拆包策略,将应用的代码和第三方库的代码分别打包成两份产物,并对于动态 import 的模块单独打包成一个 chunk。
我们也可以通过
manualChunks参数进行自定义配置:ts// vite.config.ts { build { rollupOptions: { output: { // 1. 对象配置 manualChunks: { // 将 React 相关库打包成单独的 chunk 中 'react-vendor': ['react', 'react-dom'], // 将 Lodash 库的代码单独打包 'lodash': ['lodash-es'], // 将组件库的代码打包 'library': ['antd'], }, // 2. 函数配置 if (id.includes('antd') || id.includes('@arco-design/web-react')) { return 'library'; } if (id.includes('lodash')) { return 'lodash'; } if (id.includes('react')) { return 'react'; } }, } }, }当然,在函数配置中,我们还需要注意循环引用的问题。
按需加载
在一个完整的 Web 应用中,对于某些模块当前页面可能并不需要,如果浏览器在加载当前页面的同时也需要加载这些不必要的模块,那么可能会带来严重的性能问题。一个比较好的方式是对路由组件进行动态引入,比如在 React 应用中使用
@loadable/component进行组件异步加载:tsimport React from "react"; import ReactDOM from "react-dom"; import loadable from "@loadable/component"; import { BrowserRouter, Routes, Route } from "react-router-dom"; const Foo = loadable(() => import("./routes/Foo")); const Bar = loadable(() => import("./routes/Bar")); ReactDOM.render( <React.StrictMode> <BrowserRouter> <Routes> <Route path="/foo" element={<Foo />} /> <Route path="/bar" element={<Bar />} /> </Routes> </BrowserRouter> </React.StrictMode>, document.getElementById("root") );这样在生产环境中,Vite 也会将动态引入的组件单独打包成一个 chunk。
对于组件内部的逻辑,我们也可以通过动态 import 的方式来延迟执行,进一步优化首屏的加载性能,如下代码所示:
tsxfunction App() { const computeFunc = async () => { // 延迟加载第三方库 // 需要注意 Tree Shaking 问题 // 如果直接引入包名,无法做到 Tree-Shaking,因此尽量导入具体的子路径 const { default: merge } = await import("lodash-es/merge"); const c = merge({ a: 1 }, { b: 2 }); console.log(c); }; return ( <div className="App"> <p> <button type="button" onClick={computeFunc}> Click me </button> </p> </div> ); } export default App;预渲染优化
预渲染是当今比较主流的优化手段,主要包括服务端渲染(SSR)和静态站点生成(SSG)这两种技术。
在 SSR 的场景下,服务端生成好完整的 HTML 内容,直接返回给浏览器,浏览器能够根据 HTML 渲染出完整的首屏内容,而不需要依赖 JS 的加载,从而降低浏览器的渲染压力;而另一方面,由于服务端的网络环境更优,可以更快地获取到页面所需的数据,也能节省浏览器请求数据的时间。
而 SSG 可以在构建阶段生成完整的 HTML 内容,它与 SSR 最大的不同在于 HTML 的生成在构建阶段完成,而不是在服务器的运行时。SSG 同样可以给浏览器完整的 HTML 内容,不依赖于 JS 的加载,可以有效提高页面加载性能。不过相比 SSR,SSG 的内容往往动态性不够,适合比较静态的站点,比如文档、博客等场景。
配置解析
Vite 构建环境分为开发环境和生产环境,不同环境会有不同的构建策略,但不管是哪种环境,Vite 都会首先解析用户配置。
一、流程梳理
Vite 中的配置解析由 resolveConfig 函数来实现,你可以对照源码一起学习。
1. 加载配置文件
进行一些必要的变量声明后,我们进入到解析配置逻辑中:
// 这里的 config 是命令行指定的配置,如 vite --configFile=xxx
let { configFile } = config
if (configFile !== false) {
// 默认都会走到下面加载配置文件的逻辑,除非你手动指定 configFile 为 false
const loadResult = await loadConfigFromFile(
configEnv,
configFile,
config.root,
config.logLevel
)
if (loadResult) {
// 解析配置文件的内容后,和命令行配置合并
config = mergeConfig(loadResult.config, config)
configFile = loadResult.path
configFileDependencies = loadResult.dependencies
}
}第一步是解析配置文件的内容(这部分比较复杂,本文后续单独分析),然后与命令行配置合并。值得注意的是,后面有一个记录configFileDependencies的操作。因为配置文件代码可能会有第三方库的依赖,所以当第三方库依赖的代码更改时,Vite 可以通过 HMR 处理逻辑中记录的configFileDependencies检测到更改,再重启 DevServer ,来保证当前生效的配置永远是最新的。
2. 解析用户插件
第二个重点环节是 解析用户插件。首先,我们通过 apply 参数 过滤出需要生效的用户插件。为什么这么做呢?因为有些插件只在开发阶段生效,或者说只在生产环境生效,我们可以通过 apply: 'serve' 或 'build' 来指定它们,同时也可以将apply配置为一个函数,来自定义插件生效的条件。解析代码如下:
// resolve plugins
const rawUserPlugins = (config.plugins || []).flat().filter((p) => {
if (!p) {
return false
} else if (!p.apply) {
return true
} else if (typeof p.apply === 'function') {
// apply 为一个函数的情况
return p.apply({ ...config, mode }, configEnv)
} else {
return p.apply === command
}
}) as Plugin[]
// 对用户插件进行排序
const [prePlugins, normalPlugins, postPlugins] =
sortUserPlugins(rawUserPlugins)接着,Vite 会拿到这些过滤且排序完成的插件,依次调用插件 config 钩子,进行配置合并:
// run config hooks
const userPlugins = [...prePlugins, ...normalPlugins, ...postPlugins]
for (const p of userPlugins) {
if (p.config) {
const res = await p.config(config, configEnv)
if (res) {
// mergeConfig 为具体的配置合并函数,大家有兴趣可以阅读一下实现
config = mergeConfig(config, res)
}
}
}然后解析项目的根目录即 root 参数,默认取 process.cwd() 的结果:
// resolve root
const resolvedRoot = normalizePath(
config.root ? path.resolve(config.root) : process.cwd()
)紧接着处理 alias ,这里需要加上一些内置的 alias 规则,如@vite/env、@vite/client这种直接重定向到 Vite 内部的模块:
// resolve alias with internal client alias
const resolvedAlias = mergeAlias(
clientAlias,
config.resolve?.alias || config.alias || []
)
const resolveOptions: ResolvedConfig['resolve'] = {
dedupe: config.dedupe,
...config.resolve,
alias: resolvedAlias
}3. 加载环境变量
现在,我们进入第三个核心环节: 加载环境变量,它的实现代码如下:
// load .env files
const envDir = config.envDir
? normalizePath(path.resolve(resolvedRoot, config.envDir))
: resolvedRoot
const userEnv =
inlineConfig.envFile !== false &&
loadEnv(mode, envDir, resolveEnvPrefix(config))loadEnv 其实就是扫描 p 与 .env 文件,解析出 env 对象,值得注意的是,这个对象的属性最终会被挂载到 i 这个全局对象上。
解析 env 对象的实现思路如下:
- 遍历 p
rocess.env 的属性,拿到指定前缀开头的属性(默认指定为 VITE_),并挂载 env 对象上。 - 遍历 .env 文件,解析文件,然后往 env 对象挂载那些以指定前缀开头的属性。遍历的文件先后顺序如下(下面的
mode开发阶段为development,生产环境为production):.env.${mode}.local.env.${mode}.env.local.env
特殊情况: 如果中途遇到 NODE_ENV 属性,则挂到
p,Vite 会优先通过这个属性来决定是否走rocess.env.VITE_USER_NODE_ENV 生产环境的构建。
接下来是对资源公共路径即base URL的处理,逻辑集中在 resolveBaseUrl 函数当中:
// 解析 base url
const BASE_URL = resolveBaseUrl(config.base, command === 'build', logger)
// 解析生产环境构建配置
const resolvedBuildOptions = resolveBuildOptions(config.build)resolveBaseUrl里面有这些处理规则需要注意:
- 空字符或者
./在开发阶段特殊处理,全部重写为/ .开头的路径,自动重写为/- 以
http(s)://开头的路径,在开发环境下重写为对应的 pathname - 确保路径开头和结尾都是
/
还有对cacheDir的解析,这个路径相对于在 Vite 预编译时写入依赖产物的路径:
// resolve cache directory
const pkgPath = lookupFile(resolvedRoot, [`package.json`], true /* pathOnly */)
// 默认为 node_module/.vite
const cacheDir = config.cacheDir
? path.resolve(resolvedRoot, config.cacheDir)
: pkgPath && path.join(path.dirname(pkgPath), `node_modules/.vite`)紧接着处理用户配置的assetsInclude,将其转换为一个过滤器函数:
const assetsFilter = config.assetsInclude
? createFilter(config.assetsInclude)
: () => falseVite 后面会将用户传入的 assetsInclude 和内置的规则合并:
assetsInclude(file: string) {
return DEFAULT_ASSETS_RE.test(file) || assetsFilter(file)
}这个配置决定是否让 Vite 将对应的后缀名视为静态资源文件(asset)来处理。
4. 路径解析器工厂
接下来,进入到第四个核心环节: 定义路径解析器工厂。这里所说的路径解析器,是指调用插件容器进行路径解析的函数。代码结构是这个样子的:
const createResolver: ResolvedConfig['createResolver'] = (options) => {
let aliasContainer: PluginContainer | undefined
let resolverContainer: PluginContainer | undefined
// 返回的函数可以理解为一个解析器
return async (id, importer, aliasOnly, ssr) => {
let container: PluginContainer
if (aliasOnly) {
container =
aliasContainer ||
// 新建 aliasContainer
} else {
container =
resolverContainer ||
// 新建 resolveContainer
}
return (await container.resolveId(id, importer, undefined, ssr))?.id
}
}这个解析器未来会在依赖预构建的时候用上,具体用法如下:
const resolve = config.createResolver()
// 调用以拿到 react 路径
rseolve('react', undefined, undefined, false)这里有aliasContainer和resolverContainer两个工具对象,它们都含有resolveId这个专门解析路径的方法,可以被 Vite 调用来获取解析结果。
两个工具对象的本质是
PluginContainer,后续会在「插件流水线」中详细介绍PluginContainer的特点和实现。
接着会顺便处理一个 public 目录,也就是 Vite 作为静态资源服务的目录:
const { publicDir } = config
const resolvedPublicDir =
publicDir !== false && publicDir !== ''
? path.resolve(
resolvedRoot,
typeof publicDir === 'string' ? publicDir : 'public'
)
: ''至此,配置已经基本上解析完成,最后通过 resolved 对象来整理一下:
const resolved: ResolvedConfig = {
...config,
configFile: configFile ? normalizePath(configFile) : undefined,
configFileDependencies,
inlineConfig,
root: resolvedRoot,
base: BASE_URL
// 其余配置不再一一列举
}5. 生成插件流水线
我们进入第五个环节: 生成插件流水线。代码如下:
;(resolved.plugins as Plugin[]) = await resolvePlugins(
resolved,
prePlugins,
normalPlugins,
postPlugins
)
// call configResolved hooks
await Promise.all(userPlugins.map((p) => p.configResolved?.(resolved)))先生成完整插件列表传给resolve.plugins,而后调用每个插件的 configResolved 钩子函数。其中 resolvePlugins 内部细节比较多,插件数量比较庞大,我们暂时不去深究具体实现,编译流水线这一小节再来详细介绍。
至此,所有核心配置都生成完毕。不过,后面 Vite 还会处理一些边界情况,在用户配置不合理的时候,给用户对应的提示。比如:用户直接使用alias时,Vite 会提示使用resolve.alias。
最后,resolveConfig 函数会返回 resolved 对象,也就是最后的配置集合,那么配置解析服务到底也就结束了。
二、加载配置文件详解
配置解析服务的流程梳理完,但刚开始加载配置文件(loadConfigFromFile)的实现我们还没有具体分析,先来回顾下代码。
const loadResult = await loadConfigFromFile(/*省略传参*/)这里的逻辑稍微有点复杂,很难梳理清楚,所以我们不妨借助刚才梳理的配置解析流程,深入loadConfigFromFile 的细节中,研究下 Vite 对于配置文件加载的实现思路。
首先,我们来分析下需要处理的配置文件类型,根据文件后缀和模块格式可以分为下面这几类:
- TS + ESM 格式
- TS + CommonJS 格式
- JS + ESM 格式
- JS + CommonJS 格式 那么,Vite 是如何加载配置文件的?一共分两个步骤:
- 识别出配置文件的类别
- 根据不同的类别分别解析出配置内容
1. 识别配置文件的类别
首先 Vite 会检查项目的 package.json ,如果有type: "module"则打上 isESM 的标识:
try {
const pkg = lookupFile(configRoot, ['package.json'])
if (pkg && JSON.parse(pkg).type === 'module') {
isMjs = true
}
} catch (e) {}然后,Vite 会寻找配置文件路径,代码简化后如下:
let isTS = false
let isESM = false
let dependencies: string[] = []
// 如果命令行有指定配置文件路径
if (configFile) {
resolvedPath = path.resolve(configFile)
// 根据后缀判断是否为 ts 或者 esm,打上 flag
isTS = configFile.endsWith('.ts')
if (configFile.endsWith('.mjs')) {
isESM = true
}
} else {
// 从项目根目录寻找配置文件路径,寻找顺序:
// - vite.config.js
// - vite.config.mjs
// - vite.config.ts
// - vite.config.cjs
const jsconfigFile = path.resolve(configRoot, 'vite.config.js')
if (fs.existsSync(jsconfigFile)) {
resolvedPath = jsconfigFile
}
if (!resolvedPath) {
const mjsconfigFile = path.resolve(configRoot, 'vite.config.mjs')
if (fs.existsSync(mjsconfigFile)) {
resolvedPath = mjsconfigFile
isESM = true
}
}
if (!resolvedPath) {
const tsconfigFile = path.resolve(configRoot, 'vite.config.ts')
if (fs.existsSync(tsconfigFile)) {
resolvedPath = tsconfigFile
isTS = true
}
}
if (!resolvedPath) {
const cjsConfigFile = path.resolve(configRoot, 'vite.config.cjs')
if (fs.existsSync(cjsConfigFile)) {
resolvedPath = cjsConfigFile
isESM = false
}
}
}在寻找路径的同时, Vite 也会给当前配置文件打上isESM和isTS的标识,方便后续的解析。
2. 根据类别解析配置
ESM 格式
对于 ESM 格式配置的处理代码如下:
tslet userConfig: UserConfigExport | undefined if (isESM) { const fileUrl = require('url').pathToFileURL(resolvedPath) // 首先对代码进行打包 const bundled = await bundleConfigFile(resolvedPath, true) dependencies = bundled.dependencies // TS + ESM if (isTS) { fs.writeFileSync(resolvedPath + '.js', bundled.code) userConfig = (await dynamicImport(`${fileUrl}.js?t=${Date.now()}`)).default fs.unlinkSync(resolvedPath + '.js') debug(`TS + native esm config loaded in ${getTime()}`, fileUrl) } // JS + ESM else { userConfig = (await dynamicImport(`${fileUrl}?t=${Date.now()}`)).default debug(`native esm config loaded in ${getTime()}`, fileUrl) } }首先通过 Esbuild 将配置文件编译打包成 js 代码:
tsconst bundled = await bundleConfigFile(resolvedPath, true) // 记录依赖 dependencies = bundled.dependencies对于 TS 配置文件来说,Vite 会将编译后的 js 代码写入
临时文件,通过 Node 原生 ESM Import 来读取这个临时的内容,以获取到配置内容,再直接删掉临时文件:tsfs.writeFileSync(resolvedPath + '.js', bundled.code) userConfig = (await dynamicImport(`${fileUrl}.js?t=${Date.now()}`)).default fs.unlinkSync(resolvedPath + '.js')以上这种先编译配置文件,再将产物写入临时目录,最后加载临时目录产物的做法,也是 AOT (Ahead Of Time)编译技术的一种具体实现。
而对于 JS 配置文件来说,Vite 会直接通过 Node 原生 ESM Import 来读取,也是使用 dynamicImport 函数的逻辑。
dynamicImport的实现如下:tsexport const dynamicImport = new Function('file', 'return import(file)')你可能会问,为什么要用 new Function 包裹?这是为了避免打包工具处理这段代码,比如 Rollup 和 TSC,类似的手段还有 eval。
你可能还会问,为什么 import 路径结果要加上时间戳 query?这其实是为了让 dev server 重启后仍然读取最新的配置,避免缓存。
CommonJS 格式
对于 CommonJS 格式的配置文件,Vite 集中进行了解析:
ts// 对于 js/ts 均生效 // 使用 esbuild 将配置文件编译成 commonjs 格式的 bundle 文件 const bundled = await bundleConfigFile(resolvedPath) dependencies = bundled.dependencies // 加载编译后的 bundle 代码 userConfig = await loadConfigFromBundledFile(resolvedPath, bundled.code)bundleConfigFile的逻辑上文中已经说了,主要是通过 Esbuild 将配置文件打包,拿到打包后的 bundle 代码以及配置文件的依赖(dependencies)。而接下来的事情就是考虑如何加载 bundle 代码了,这也是
loadConfigFromBundledFile要做的事情。我们来看一下这个函数具体的实现:tsasync function loadConfigFromBundledFile( fileName: string, bundledCode: string ): Promise<UserConfig> { const extension = path.extname(fileName) const defaultLoader = require.extensions[extension]! require.extensions[extension] = (module: NodeModule, filename: string) => { if (filename === fileName) { ;(module as NodeModuleWithCompile)._compile(bundledCode, filename) } else { defaultLoader(module, filename) } } // 清除 require 缓存 delete require.cache[require.resolve(fileName)] const raw = require(fileName) const config = raw.__esModule ? raw.default : raw require.extensions[extension] = defaultLoader return config }大体的思路是通过拦截原生
require.extensions的加载函数来实现对 bundle 后配置代码的加载。代码如下:ts// 默认加载器 const defaultLoader = require.extensions[extension]! // 拦截原生 require 对于`.js`或者`.ts`的加载 require.extensions[extension] = (module: NodeModule, filename: string) => { // 针对 vite 配置文件的加载特殊处理 if (filename === fileName) { ;(module as NodeModuleWithCompile)._compile(bundledCode, filename) } else { defaultLoader(module, filename) } }而原生 require 对于 js 文件的加载代码是这样的:
tsModule._extensions['.js'] = function (module, filename) { var content = fs.readFileSync(filename, 'utf8') module._compile(stripBOM(content), filename) }Node.js 内部也是先读取文件内容,然后编译该模块。当代码中调用
module._compile相当于手动编译一个模块,该方法在 Node 内部的实现如下:tsModule.prototype._compile = function (content, filename) { var self = this var args = [self.exports, require, self, filename, dirname] return compiledWrapper.apply(self.exports, args) }等同于下面的形式:
ts;(function (exports, require, module, __filename, __dirname) { // 执行 module._compile 方法中传入的代码 // 返回 exports 对象 })在调用完
module._compile编译完配置代码后,进行一次手动的 require,即可拿到配置对象:tsconst raw = require(fileName) const config = raw.__esModule ? raw.default : raw // 恢复原生的加载方法 require.extensions[extension] = defaultLoader // 返回配置 return config这种运行时加载 TS 配置的方式,也叫做
JIT(即时编译),这种方式和AOT最大的区别在于不会将内存中计算出来的 js 代码写入磁盘再加载,而是通过拦截 Node.js 原生 require.extension 方法实现即时加载。至此,配置文件的内容已经读取完成,等后处理完成再返回即可:
ts// 处理是函数的情况 const config = await (typeof userConfig === 'function' ? userConfig(configEnv) : userConfig) if (!isObject(config)) { throw new Error(`config must export or return an object.`) } // 接下来返回最终的配置信息 return { path: normalizePath(resolvedPath), config, // esbuild 打包过程中搜集的依赖 dependencies }
依赖预构建
Vite 依赖预构建的底层实现中,大量地使用到了 Esbuild 这款构建工具,实现了比较复杂的 Esbuild 插件,同时也应用了诸多 Esbuild 使用技巧。
关于预构建所有的实现代码都在optimizeDeps函数当中,也就是在仓库源码的 packages/vite/src/node/optimizer/index.ts 文件中,你可以对照着来学习。
缓存判断
首先是预构建缓存的判断。Vite 在每次预构建之后都将一些关键信息写入到了_metadata.json文件中,第二次启动项目时会通过这个文件中的 hash 值来进行缓存的判断,如果命中缓存则不会进行后续的预构建流程,代码如下所示:
// _metadata.json 文件所在的路径
const dataPath = path.join(cacheDir, "_metadata.json");
// 根据当前的配置计算出哈希值
const mainHash = getDepHash(root, config);
const data: DepOptimizationMetadata = {
hash: mainHash,
browserHash: mainHash,
optimized: {},
};
// 默认走到里面的逻辑
if (!force) {
let prevData: DepOptimizationMetadata | undefined;
try {
// 读取元数据
prevData = JSON.parse(fs.readFileSync(dataPath, "utf-8"));
} catch (e) {}
// 当前计算出的哈希值与 _metadata.json 中记录的哈希值一致,表示命中缓存,不用预构建
if (prevData && prevData.hash === data.hash) {
log("Hash is consistent. Skipping. Use --force to override.");
return prevData;
}
}值得注意的是哈希计算的策略,即决定哪些配置和文件有可能影响预构建的结果,然后根据这些信息来生成哈希值。这部分逻辑集中在getHash函数中,我把关键信息放到了注释中:
const lockfileFormats = ["package-lock.json", "yarn.lock", "pnpm-lock.yaml"];
function getDepHash(root: string, config: ResolvedConfig): string {
// 获取 lock 文件内容
let content = lookupFile(root, lockfileFormats) || "";
// 除了 lock 文件外,还需要考虑下面的一些配置信息
content += JSON.stringify(
{
// 开发/生产环境
mode: config.mode,
// 项目根路径
root: config.root,
// 路径解析配置
resolve: config.resolve,
// 自定义资源类型
assetsInclude: config.assetsInclude,
// 插件
plugins: config.plugins.map((p) => p.name),
// 预构建配置
optimizeDeps: {
include: config.optimizeDeps?.include,
exclude: config.optimizeDeps?.exclude,
},
},
// 特殊处理函数和正则类型
(_, value) => {
if (typeof value === "function" || value instanceof RegExp) {
return value.toString();
}
return value;
}
);
// 最后调用 crypto 库中的 createHash 方法生成哈希
return createHash("sha256").update(content).digest("hex").substring(0, 8);
}依赖扫描
如果没有命中缓存,则会正式地进入依赖预构建阶段。不过 Vite 不会直接进行依赖的预构建,而是在之前探测一下项目中存在哪些依赖,收集依赖列表,也就是进行依赖扫描的过程。这个过程是必须的,因为 Esbuild 需要知道我们到底要打包哪些第三方依赖。关键代码如下:
({ deps, missing } = await scanImports(config));在scanImports方法内部主要会调用 Esbuild 提供的 build 方法:
const deps: Record<string, string> = {};
// 扫描用到的 Esbuild 插件
const plugin = esbuildScanPlugin(config, container, deps, missing, entries);
await Promise.all(
// 应用项目入口
entries.map((entry) =>
build({
absWorkingDir: process.cwd(),
// 注意这个参数
write: false,
entryPoints: [entry],
bundle: true,
format: "esm",
logLevel: "error",
plugins: [...plugins, plugin],
...esbuildOptions,
})
)
);值得注意的是,其中传入的write参数被设为 false,表示产物不用写入磁盘,这就大大节省了磁盘 I/O 的时间了,也是依赖扫描为什么往往比依赖打包快很多的原因之一。
接下来会输出预打包信息:
if (!asCommand) {
if (!newDeps) {
logger.info(
chalk.greenBright(`Pre-bundling dependencies:\n ${depsString}`)
);
logger.info(
`(this will be run only when your dependencies or config have changed)`
);
}
} else {
logger.info(chalk.greenBright(`Optimizing dependencies:\n ${depsString}`));
}这时候你可以明白,为什么第一次启动时会输出预构建相关的 log 信息了,其实这些信息都是通过依赖扫描阶段来搜集的,而此时还并未开始真正的依赖打包过程。
可能你会有疑问,为什么对项目入口打包一次就收集到所有依赖信息了呢?大家可以注意到esbuildScanPlugin这个函数创建 scan 插件的时候就接收到了deps对象作为入参,这个对象的作用不可小觑,在 scan 插件里面就是解析各种 import 语句,最终通过它来记录依赖信息。
依赖打包
收集完依赖之后,就正式地进入到依赖打包的阶段了。这里也调用 Esbuild 进行打包并写入产物到磁盘中,关键代码如下:
const result = await build({
absWorkingDir: process.cwd(),
// 所有依赖的 id 数组,在插件中会转换为真实的路径
entryPoints: Object.keys(flatIdDeps),
bundle: true,
format: "esm",
target: config.build.target || undefined,
external: config.optimizeDeps?.exclude,
logLevel: "error",
splitting: true,
sourcemap: true,
outdir: cacheDir,
ignoreAnnotations: true,
metafile: true,
define,
plugins: [
...plugins,
// 预构建专用的插件
esbuildDepPlugin(flatIdDeps, flatIdToExports, config, ssr),
],
...esbuildOptions,
});
// 打包元信息,后续会根据这份信息生成 _metadata.json
const meta = result.metafile!;元信息写入磁盘
在打包过程完成之后,Vite 会拿到 Esbuild 构建的元信息,也就是上面代码中的meta对象,然后将元信息保存到_metadata.json文件中:
const data: DepOptimizationMetadata = {
hash: mainHash,
browserHash: mainHash,
optimized: {},
};
// 省略中间的代码
for (const id in deps) {
const entry = deps[id];
data.optimized[id] = {
file: normalizePath(path.resolve(cacheDir, flattenId(id) + ".js")),
src: entry,
// 判断是否需要转换成 ESM 格式,后面会介绍
needsInterop: needsInterop(
id,
idToExports[id],
meta.outputs,
cacheDirOutputPath
),
};
}
// 元信息写磁盘
writeFile(dataPath, JSON.stringify(data, null, 2));到这里,预构建的核心流程就梳理完了,可以看到总体的流程上面并不复杂,但实际上为了方便你理解,在依赖扫描和依赖打包这两个部分中,我省略了很多的细节,每个细节代表了各种复杂的处理场景,因此,在下面的篇幅中,我们就来好好地剖析一下这两部分的应用场景和实现细节。
依赖扫描详细分析
1. 如何获取入口
现在让我们把目光聚焦在scanImports的实现上。大家可以先想一想,在进行依赖扫描之前,需要做的第一件事是什么?很显然,是找到入口文件。但入口文件可能存在于多个配置当中,比如optimizeDeps.entries和build.rollupOptions.input,同时需要考虑数组和对象的情况;也可能用户没有配置,需要自动探测入口文件。那么,在scanImports是如何做到的呢?
const explicitEntryPatterns = config.optimizeDeps.entries;
const buildInput = config.build.rollupOptions?.input;
if (explicitEntryPatterns) {
// 先从 optimizeDeps.entries 寻找入口,支持 glob 语法
entries = await globEntries(explicitEntryPatterns, config);
} else if (buildInput) {
// 其次从 build.rollupOptions.input 配置中寻找,注意需要考虑数组和对象的情况
const resolvePath = (p: string) => path.resolve(config.root, p);
if (typeof buildInput === "string") {
entries = [resolvePath(buildInput)];
} else if (Array.isArray(buildInput)) {
entries = buildInput.map(resolvePath);
} else if (isObject(buildInput)) {
entries = Object.values(buildInput).map(resolvePath);
} else {
throw new Error("invalid rollupOptions.input value.");
}
} else {
// 兜底逻辑,如果用户没有进行上述配置,则自动从根目录开始寻找
entries = await globEntries("**/*.html", config);
}其中 globEntries 方法即通过 fast-glob 库来从项目根目录扫描文件。
接下来我们还需要考虑入口文件的类型,一般情况下入口需要是js/ts文件,但实际上像 html、vue 单文件组件这种类型我们也是需要支持的,因为在这些文件中仍然可以包含 script 标签的内容,从而让我们搜集到依赖信息。
在源码当中,同时对 html、vue、svelte、astro(一种新兴的类 html 语法)四种后缀的入口文件进行了解析,当然,具体的解析过程在依赖扫描阶段的 Esbuild 插件中得以实现,接着就让我们在插件的实现中一探究竟。
const htmlTypesRE = /.(html|vue|svelte|astro)$/;
function esbuildScanPlugin(/* 一些入参 */): Plugin {
// 初始化一些变量
// 返回一个 Esbuild 插件
return {
name: "vite:dep-scan",
setup(build) {
// 标记「类 HTML」文件的 namespace
build.onResolve({ filter: htmlTypesRE }, async ({ path, importer }) => {
return {
path: await resolve(path, importer),
namespace: "html",
};
});
build.onLoad(
{ filter: htmlTypesRE, namespace: "html" },
async ({ path }) => {
// 解析「类 HTML」文件
}
);
},
};
}这里以html文件的解析为例来讲解,原理如下图所示:

在插件中会扫描出所有带有 type=module 的 script 标签,对于含有 src 的 script 改写为一个 import 语句,对于含有具体内容的 script,则抽离出其中的脚本内容,最后将所有的 script 内容拼接成一段 js 代码。接下来我们来看具体的代码,其中会以上图中的html为示例来拆解中间过程:
const scriptModuleRE =
/(<script\b[^>]*type\s*=\s*(?: module |'module')[^>]*>)(.*?)</script>/gims
export const scriptRE = /(<script\b(?:\s[^>]*>|>))(.*?)</script>/gims
export const commentRE = /<!--(.|[\r\n])*?-->/
const srcRE = /\bsrc\s*=\s*(?: ([^ ]+) |'([^']+)'|([^\s' >]+))/im
const typeRE = /\btype\s*=\s*(?: ([^ ]+) |'([^']+)'|([^\s' >]+))/im
const langRE = /\blang\s*=\s*(?: ([^ ]+) |'([^']+)'|([^\s' >]+))/im
// scan 插件 setup 方法内部实现
build.onLoad(
{ filter: htmlTypesRE, namespace: 'html' },
async ({ path }) => {
let raw = fs.readFileSync(path, 'utf-8')
// 去掉注释内容,防止干扰解析过程
raw = raw.replace(commentRE, '<!---->')
const isHtml = path.endsWith('.html')
// HTML 情况下会寻找 type 为 module 的 script
// 正则:/(<script\b[^>]*type\s*=\s*(?: module |'module')[^>]*>)(.*?)</script>/gims
const regex = isHtml ? scriptModuleRE : scriptRE
regex.lastIndex = 0
let js = ''
let loader: Loader = 'js'
let match: RegExpExecArray | null
// 正式开始解析
while ((match = regex.exec(raw))) {
// 第一次: openTag 为 <script type= module src= /src/main.ts >, 无 content
// 第二次: openTag 为 <script type= module >,有 content
const [, openTag, content] = match
const typeMatch = openTag.match(typeRE)
const type =
typeMatch && (typeMatch[1] || typeMatch[2] || typeMatch[3])
const langMatch = openTag.match(langRE)
const lang =
langMatch && (langMatch[1] || langMatch[2] || langMatch[3])
if (lang === 'ts' || lang === 'tsx' || lang === 'jsx') {
// 指定 esbuild 的 loader
loader = lang
}
const srcMatch = openTag.match(srcRE)
// 根据有无 src 属性来进行不同的处理
if (srcMatch) {
const src = srcMatch[1] || srcMatch[2] || srcMatch[3]
js += `import ${JSON.stringify(src)}\n`
} else if (content.trim()) {
js += content + '\n'
}
}
return {
loader,
contents: js
}
)这里对源码做了一定的精简,省略了 vue/svelte 以及 i 语法的处理,但不影响整体的实现思路,这里主要是让你了解即使是html或者类似这种类型的文件,也是能作为 Esbuild 的预构建入口来进行解析的。
2. 如何记录依赖?
Vite 中会把 bare import 的路径当做依赖路径,关于 bare import,你可以理解为直接引入一个包名,比如下面这样:
import React from "react";而以.开头的相对路径或者以/开头的绝对路径都不能算bare import:
// 以下都不是 bare import
import React from "../node_modules/react/index.js";
import React from "/User/sanyuan/vite-project/node_modules/react/index.js";对于解析 bare import、记录依赖的逻辑依然实现在 scan 插件当中:
build.onResolve(
{
// avoid matching windows volume
filter: /^[\w@][^:]/,
},
async ({ path: id, importer }) => {
// 如果在 optimizeDeps.exclude 列表或者已经记录过了,则将其 externalize (排除),直接 return
// 接下来解析路径,内部调用各个插件的 resolveId 方法进行解析
const resolved = await resolve(id, importer);
if (resolved) {
// 判断是否应该 externalize,下个部分详细拆解
if (shouldExternalizeDep(resolved, id)) {
return externalUnlessEntry({ path: id });
}
if (resolved.includes("node_modules") || include?.includes(id)) {
// 如果 resolved 为 js 或 ts 文件
if (OPTIMIZABLE_ENTRY_RE.test(resolved)) {
// 注意了! 现在将其正式地记录在依赖表中
depImports[id] = resolved;
}
// 进行 externalize,因为这里只用扫描出依赖即可,不需要进行打包,具体实现后面的部分会讲到
return externalUnlessEntry({ path: id });
} else {
// resolved 为 「类 html」 文件,则标记上 'html' 的 namespace
const namespace = htmlTypesRE.test(resolved) ? "html" : undefined;
// linked package, keep crawling
return {
path: path.resolve(resolved),
namespace,
};
}
} else {
// 没有解析到路径,记录到 missing 表中,后续会检测这张表,显示相关路径未找到的报错
missing[id] = normalizePath(importer);
}
}
);顺便说一句,其中调用到了resolve,也就是路径解析的逻辑,这里面实际上会调用各个插件的 resolveId 方法来进行路径的解析,代码如下所示:
const resolve = async (id: string, importer?: string) => {
// 通过 seen 对象进行路径缓存
const key = id + (importer && path.dirname(importer));
if (seen.has(key)) {
return seen.get(key);
}
// 调用插件容器的 resolveId
// 关于插件容器下一节会详细介绍,这里你直接理解为调用各个插件的 resolveId 方法解析路径即可
const resolved = await container.resolveId(
id,
importer && normalizePath(importer)
);
const res = resolved?.id;
seen.set(key, res);
return res;
};3. external 的规则如何制定?
在 bare import 记录依赖的过程中还有一件非常重要的事情,就是决定哪些路径应该被排除,不应该被记录或者不应该被 Esbuild 来解析。这就是 external 规则的概念。
在这里,我们把需要 external 的路径分为两类: 资源型和模块型。
首先,对于资源型的路径,一般是直接排除,在插件中的处理方式如下:
// data url,直接标记 external: true,不让 esbuild 继续处理
build.onResolve({ filter: dataUrlRE }, ({ path }) => ({
path,
external: true,
}));
// 加了 ?worker 或者 ?raw 这种 query 的资源路径,直接 external
build.onResolve({ filter: SPECIAL_QUERY_RE }, ({ path }) => ({
path,
external: true,
}));
// css & json
build.onResolve(
{
filter: /.(css|less|sass|scss|styl|stylus|pcss|postcss|json)$/,
},
// 非 entry 则直接标记 external
externalUnlessEntry
);
// Vite 内置的一些资源类型,比如 .png、.wasm 等等
build.onResolve(
{
filter: new RegExp(`\.(${KNOWN_ASSET_TYPES.join("|")})$`),
},
// 非 entry 则直接标记 external
externalUnlessEntry
);其中externalUnlessEntry的实现也很简单:
const externalUnlessEntry = ({ path }: { path: string }) => ({
path,
// 非 entry 则标记 external
external: !entries.includes(path),
});其次,对于模块型的路径,也就是当我们通过 resolve 函数解析出了一个 JS 模块的路径,如何判断是否应该被 externalize 呢?这部分实现主要在 shouldExternalizeDep 函数中,之前在分析 bare import 埋了个伏笔,现在让我们看看具体的实现规则:
export function shouldExternalizeDep(
resolvedId: string,
rawId: string
): boolean {
// 解析之后不是一个绝对路径,不在 esbuild 中进行加载
if (!path.isAbsolute(resolvedId)) {
return true;
}
// 1. import 路径本身就是一个绝对路径
// 2. 虚拟模块(Rollup 插件中约定虚拟模块以`\0`开头)
// 都不在 esbuild 中进行加载
if (resolvedId === rawId || resolvedId.includes("\0")) {
return true;
}
// 不是 JS 或者 类 HTML 文件,不在 esbuild 中进行加载
if (!JS_TYPES_RE.test(resolvedId) && !htmlTypesRE.test(resolvedId)) {
return true;
}
return false;
}依赖打包详细分析
1. 如何达到扁平化的产物文件结构
一般情况下,esbuild 会输出嵌套的产物目录结构,比如对 vue 来说,其产物在dist/vue.runtime.esm-bundler.js中,那么经过 esbuild 正常打包之后,预构建的产物目录如下:
node_modules/.vite
├── _metadata.json
├── vue
│ └── dist
│ └── vue.runtime.esm-bundler.js由于各个第三方包的产物目录结构不一致,这种深层次的嵌套目录对于 Vite 路径解析来说,其实是增加了不少的麻烦的,带来了一些不可控的因素。为了解决嵌套目录带来的问题,Vite 做了两件事情来达到扁平化的预构建产物输出:
- 嵌套路径扁平化,
/被换成下划线,如react/jsx-dev-runtime,被重写为react_jsx-dev-runtime; - 用虚拟模块来代替真实模块,作为预打包的入口,具体的实现后面会详细介绍。
回到optimizeDeps函数中,其中在进行完依赖扫描的步骤后,就会执行路径的扁平化操作:
const flatIdDeps: Record<string, string> = {};
const idToExports: Record<string, ExportsData> = {};
const flatIdToExports: Record<string, ExportsData> = {};
// deps 即为扫描后的依赖表
// 形如: {
// react : /Users/sanyuan/vite-project/react/index.js }
// react/jsx-dev-runtime : /Users/sanyuan/vite-project/react/jsx-dev-runtime.js
// }
for (const id in deps) {
// 扁平化路径,`react/jsx-dev-runtime`,被重写为`react_jsx-dev-runtime`;
const flatId = flattenId(id);
// 填入 flatIdDeps 表,记录 flatId -> 真实路径的映射关系
const filePath = (flatIdDeps[flatId] = deps[id]);
const entryContent = fs.readFileSync(filePath, "utf-8");
// 后续代码省略
}对于虚拟模块的处理,大家可以把目光放到 esbuildDepPlugin 函数上面,它的逻辑大致如下:
export function esbuildDepPlugin(/* 一些传参 */) {
// 定义路径解析的方法
// 返回 Esbuild 插件
return {
name: 'vite:dep-pre-bundle',
set(build) {
// bare import 的路径
build.onResolve(
{ filter: /^[\w@][^:]/ },
async ({ path: id, importer, kind }) => {
// 判断是否为入口模块,如果是,则标记上`dep`的 namespace,成为一个虚拟模块
}
)
build.onLoad({ filter: /.*/, namespace: 'dep' }, ({ path: id }) => {
// 加载虚拟模块
})
}
}
}如此一来,Esbuild 会将虚拟模块作为入口来进行打包,最后的产物目录会变成下面的扁平结构:
node_modules/.vite
├── _metadata.json
├── vue.js
├── react.js
├── react_jsx-dev-runtime.js注:虚拟模块加载部分的代码在 Vite 3.0 中已被移除,原因是 Esbuild 输出扁平化产物路径已不再需要使用虚拟模块,PR 地址: github.com/vitejs/vite… 如下部分的小册内容你可以进行选读。
2. 代理模块加载
虚拟模块代替了真实模块作为打包入口,因此也可以理解为代理模块,后面也统一称之为代理模块。我们首先来分析一下代理模块究竟是如何被加载出来的,换句话说,它到底了包含了哪些内容。
拿import React from "react"来举例,Vite 会把react标记为 namespace 为 dep 的虚拟模块,然后控制 Esbuild 的加载流程,对于真实模块的内容进行重新导出。
那么第一步就是确定真实模块的路径:
// 真实模块所在的路径,拿 react 来说,即`node_modules/react/index.js`
const entryFile = qualified[id];
// 确定相对路径
let relativePath = normalizePath(path.relative(root, entryFile));
if (
!relativePath.startsWith("./") &&
!relativePath.startsWith("../") &&
relativePath !== "."
) {
relativePath = `./${relativePath}`;
}确定了路径之后,接下来就是对模块的内容进行重新导出。这里会分为几种情况:
- CommonJS 模块
- ES 模块
我们可以暂时把目光转移到optimizeDeps中,实际上在进行真正的依赖打包之前,Vite 会读取各个依赖的入口文件,通过es-module-lexer这种工具来解析入口文件的内容。这里稍微解释一下es-module-lexer,这是一个在 Vite 被经常使用到的工具库,主要是为了解析 ES 导入导出的语法,大致用法如下:
import { init, parse } from "es-module-lexer";
// 等待`es-module-lexer`初始化完成
await init;
const sourceStr = `
import moduleA from './a';
export * from 'b';
export const count = 1;
export default count;
`;
// 开始解析
const exportsData = parse(sourceStr);
// 结果为一个数组,分别保存 import 和 export 的信息
const [imports, exports] = exportsData;
// 返回 `import module from './a'`
sourceStr.substring(imports[0].ss, imports[0].se);
// 返回 ['count', 'default']
console.log(exports);值得注意的是, export * from 导出语法会被记录在 import 信息中。
接下来我们来看看 optimizeDeps 中如何利用 es-module-lexer 来解析入口文件的,实现代码如下:
import { init, parse } from "es-module-lexer";
// 省略中间的代码
await init;
for (const id in deps) {
// 省略前面的路径扁平化逻辑
// 读取入口内容
const entryContent = fs.readFileSync(filePath, "utf-8");
try {
exportsData = parse(entryContent) as ExportsData;
} catch {
// 省略对 jsx 的处理
}
for (const { ss, se } of exportsData[0]) {
const exp = entryContent.slice(ss, se);
// 标记存在 `export * from` 语法
if (/export\s+*\s+from/.test(exp)) {
exportsData.hasReExports = true;
}
}
// 将 import 和 export 信息记录下来
idToExports[id] = exportsData;
flatIdToExports[flatId] = exportsData;
}由于最后会有两张表记录下 ES 模块导入和导出的相关信息,而flatIdToExports表会作为入参传给 Esbuild 插件:
// 第二个入参
esbuildDepPlugin(flatIdDeps, flatIdToExports, config, ssr);如此,我们就能根据真实模块的路径获取到导入和导出的信息,通过这份信息来甄别 CommonJS 和 ES 两种模块规范。现在可以回到 Esbuild 打包插件中加载代理模块的代码:
let contents = "";
// 下面的 exportsData 即外部传入的模块导入导出相关的信息表
// 根据模块 id 拿到对应的导入导出信息
const data = exportsData[id];
const [imports, exports] = data;
if (!imports.length && !exports.length) {
// 处理 CommonJS 模块
} else {
// 处理 ES 模块
}如果是 CommonJS 模块,则导出语句写成这种形式:
let contents = "";
contents += `export default require( ${relativePath} );`;如果是 ES 模块,则分默认导出和非默认导出这两种情况来处理:
// 默认导出,即存在 export default 语法
if (exports.includes("default")) {
contents += `import d from ${relativePath} ;export default d;`;
}
// 非默认导出
if (
// 1. 存在 `export * from` 语法,前文分析过
data.hasReExports ||
// 2. 多个导出内容
exports.length > 1 ||
// 3. 只有一个导出内容,但这个导出不是 export default
exports[0] !== "default"
) {
// 凡是命中上述三种情况中的一种,则添加下面的重导出语句
contents += `\nexport * from ${relativePath} `;
}现在,我们组装好了 代理模块 的内容,接下来就可以放心地交给 Esbuild 加载了:
let ext = path.extname(entryFile).slice(1);
if (ext === "mjs") ext = "js";
return {
loader: ext as Loader,
// 虚拟模块内容
contents,
resolveDir: root,
};3. 代理模块为什么要和真实模块分离?
现在,相信你已经清楚了 Vite 是如何组装代理模块,以此作为 Esbuild 打包入口的,整体的思路就是先分析一遍模块真实入口文件的import和export语法,然后在代理模块中进行重导出。这里不妨回过头来思考一下: 为什么要对真实文件先做语法分析,然后重导出内容呢?
注意一下代码中的这段注释:
// It is necessary to do the re-exporting to separate the virtual proxy
// module from the actual module since the actual module may get
// referenced via relative imports - if we don't separate the proxy and
// the actual module, esbuild will create duplicated copies of the same
// module!
// 翻译后:
// 这种重导出的做法是必要的,它可以分离虚拟模块和真实模块,因为真实模块可以通过相对地址来引入。如果不这么做,Esbuild 将会对打包输出两个一样的模块。假设我不像源码中这么做,在虚拟模块中直接将真实入口的内容作为传给 Esbuild 可不可以呢?也就是像这样:
build.onLoad({ filter: /.*/, namespace: 'dep' }, ({ path: id }) => {
// 拿到查表拿到真实入口模块路径
const entryFile = qualified[id];
return {
loader: 'js',
contents: fs.readFileSync(entryFile, 'utf8')
}
})那么,这么实现会产生什么问题呢?我们可以先看看正常的预打包流程(以 React 为例):
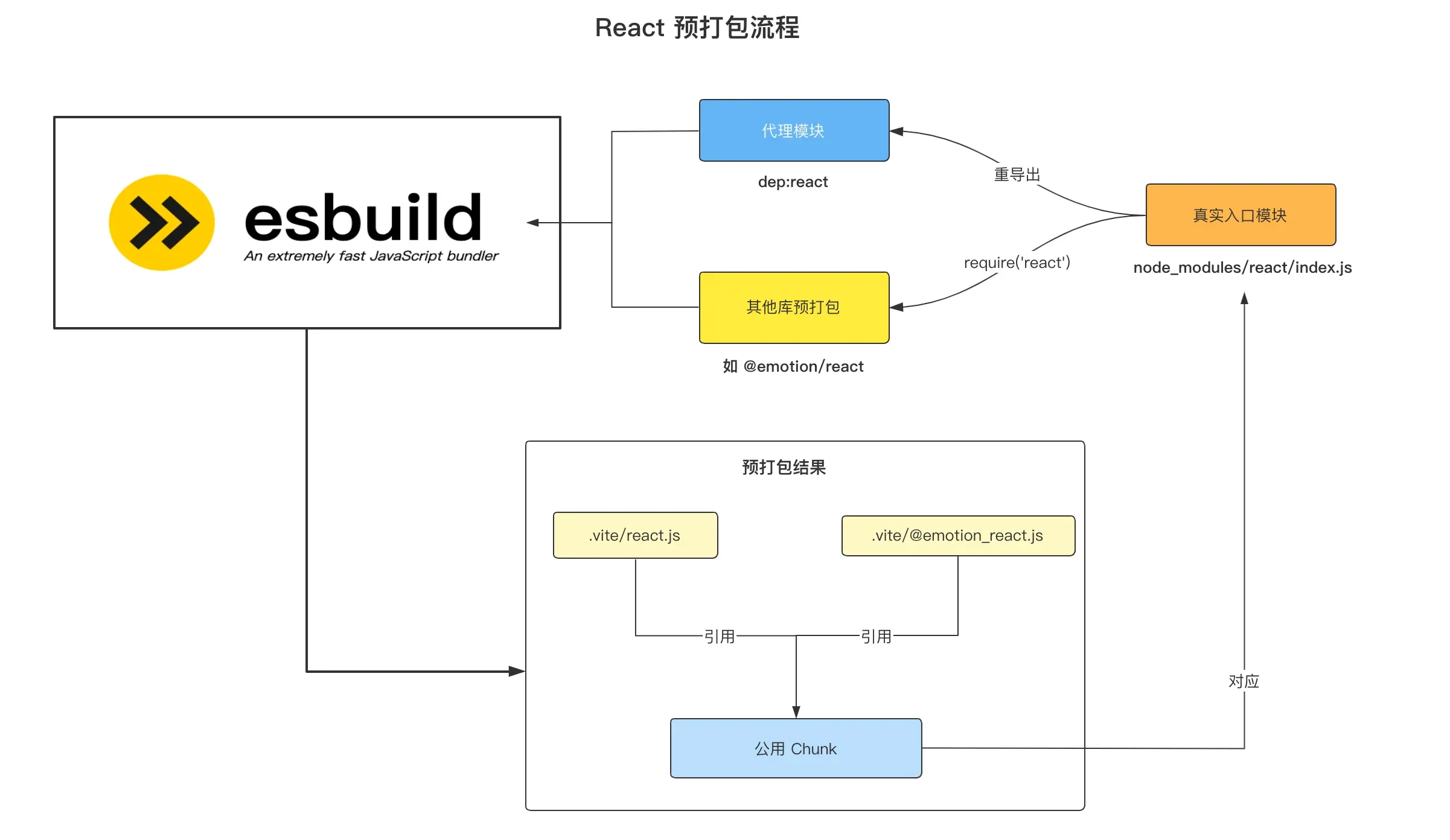
Vite 会使用 dep:react这个代理模块来作为入口内容在 Esbuild 中进行加载,与此同时,其他库的预打包也有可能会引入 React,比如@emotion/react这个库里面会有require('react')的行为。那么在 Esbuild 打包之后,react.js与@emotion_react.js的代码中会引用同一份 Chunk 的内容,这份 Chunk 也就对应 React 入口文件(node_modules/react/index.js)。
这是理想情况下的打包结果,接下来我们来看看上述有问题的版本是如何工作的:
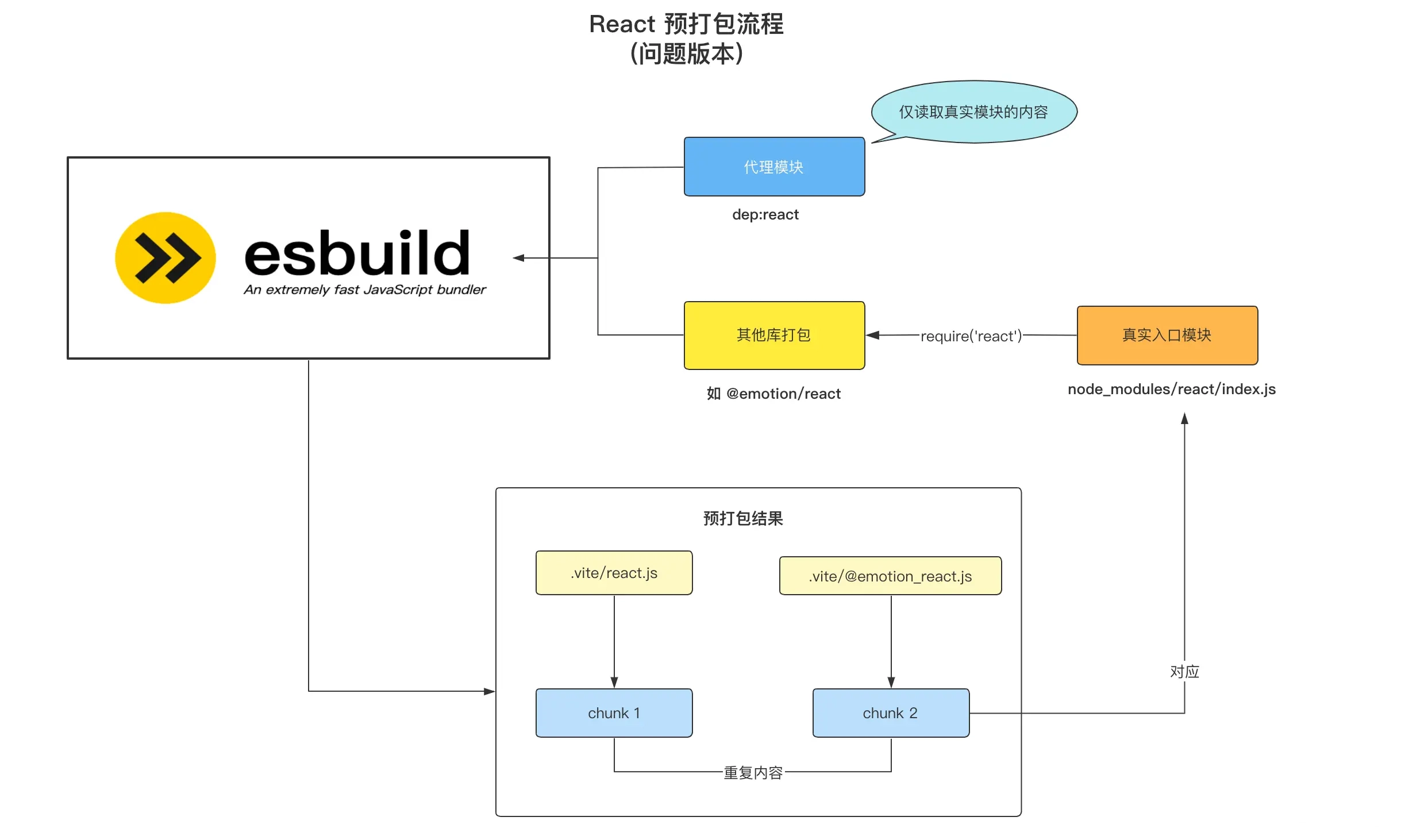
现在如果代理模块通过文件系统直接读取真实模块的内容,而不是进行重导出,因此由于此时代理模块跟真实模块并没有任何的引用关系,这就导致最后的react.js和@emotion/react.js两份产物并不会引用同一份 Chunk,Esbuild 最后打包出了内容完全相同的两个 Chunk!
这也就能解释为什么 Vite 中要在代理模块中对真实模块的内容进行重导出了,主要是为了避免 Esbuild 产生重复的打包内容。此时,你是不是也恍然大悟了呢?
插件流水线
Vite 在开发阶段实现了一个按需加载的服务器,每一个文件请求进来都会经历一系列的编译流程,然后 Vite 会将编译结果响应给浏览器。在生产环境下,Vite 同样会执行一系列编译过程,将编译结果交给 Rollup 进行模块打包。这一系列的编译过程指的就是 Vite 的插件工作流水线(Pipeline),而插件功能又是 Vite 构建能力的核心,因此谈到阅读 Vite 源码,我们永远绕不开插件的作用与实现原理。
插件容器
我们知道 Vite 的插件机制是与 Rollup 兼容的,但它在开发和生产环境下的实现稍有差别,你可以回顾一下这张架构图:
我们可以看到:
- 在生产环境中 Vite 直接调用 Rollup 进行打包,所以 Rollup 可以调度各种插件;
- 在开发环境中,Vite 模拟了 Rollup 的插件机制,设计了一个
PluginContainer对象来调度各个插件。
PluginContainer(插件容器)对象非常重要,前两节我们也多次提到了它,接下来我们就把目光集中到这个对象身上,看看 Vite 的插件容器机制究竟是如何实现的。
PluginContainer 的 实现 基于借鉴于 WMR 中的rollup-plugin-container.js,主要分为 2 个部分:
- 实现 Rollup 插件钩子的调度
- 实现插件钩子内部的 Context 上下文对象
首先,你可以通过 container 的定义 来看看各个 Rollup 钩子的实现方式,代码精简后如下:
const container = {
// 异步串行钩子
options: await (async () => {
let options = rollupOptions
for (const plugin of plugins) {
if (!plugin.options) continue
options =
(await plugin.options.call(minimalContext, options)) || options
}
return options;
})(),
// 异步并行钩子
async buildStart() {
await Promise.all(
plugins.map((plugin) => {
if (plugin.buildStart) {
return plugin.buildStart.call(
new Context(plugin) as any,
container.options as NormalizedInputOptions
)
}
})
)
},
// 异步优先钩子
async resolveId(rawId, importer) {
// 上下文对象,后文介绍
const ctx = new Context()
let id: string | null = null
const partial: Partial<PartialResolvedId> = {}
for (const plugin of plugins) {
const result = await plugin.resolveId.call(
ctx as any,
rawId,
importer,
{ ssr }
)
if (!result) continue;
return result;
}
}
// 异步优先钩子
async load(id, options) {
const ctx = new Context()
for (const plugin of plugins) {
const result = await plugin.load.call(ctx as any, id, { ssr })
if (result != null) {
return result
}
}
return null
},
// 异步串行钩子
async transform(code, id, options) {
const ssr = options?.ssr
// 每次 transform 调度过程会有专门的上下文对象,用于合并 SourceMap,后文会介绍
const ctx = new TransformContext(id, code, inMap as SourceMap)
ctx.ssr = !!ssr
for (const plugin of plugins) {
let result: TransformResult | string | undefined
try {
result = await plugin.transform.call(ctx as any, code, id, { ssr })
} catch (e) {
ctx.error(e)
}
if (!result) continue;
// 省略 SourceMap 合并的逻辑
code = result;
}
return {
code,
map: ctx._getCombinedSourcemap()
}
},
// close 钩子实现省略
}值得注意的是,在各种钩子被调用的时候,Vite 会强制将钩子函数的 this 绑定为一个上下文对象,如:
const ctx = new Context()
const result = await plugin.load.call(ctx as any, id, { ssr })我们知道,在 Rollup 钩子函数中,我们可以调用this.emitFile、this.resolve 等诸多的上下文方法(详情地址),因此,Vite 除了要模拟各个插件的执行流程,还需要模拟插件执行的上下文对象,代码中的 Context 对象就是用来完成这件事情的。我们来看看 Context 对象的具体实现:
import { RollupPluginContext } from 'rollup';
type PluginContext = Omit<
RollupPluginContext,
// not documented
| 'cache'
// deprecated
| 'emitAsset'
| 'emitChunk'
| 'getAssetFileName'
| 'getChunkFileName'
| 'isExternal'
| 'moduleIds'
| 'resolveId'
| 'load'
>
const watchFiles = new Set<string>()
class Context implements PluginContext {
// 实现各种上下文方法
// 解析模块 AST(调用 acorn)
parse(code: string, opts: any = {}) {
return parser.parse(code, {
sourceType: 'module',
ecmaVersion: 'latest',
locations: true,
...opts
})
}
// 解析模块路径
async resolve(
id: string,
importer?: string,
options?: { skipSelf?: boolean }
) {
let skip: Set<Plugin> | undefined
if (options?.skipSelf && this._activePlugin) {
skip = new Set(this._resolveSkips)
skip.add(this._activePlugin)
}
let out = await container.resolveId(id, importer, { skip, ssr: this.ssr })
if (typeof out === 'string') out = { id: out }
return out as ResolvedId | null
}
// 以下两个方法均从 Vite 的模块依赖图中获取相关的信息
// 我们将在下一节详细介绍模块依赖图,本节不做展开
getModuleInfo(id: string) {
return getModuleInfo(id)
}
getModuleIds() {
return moduleGraph
? moduleGraph.idToModuleMap.keys()
: Array.prototype[Symbol.iterator]()
}
// 记录开发阶段 watch 的文件
addWatchFile(id: string) {
watchFiles.add(id)
;(this._addedImports || (this._addedImports = new Set())).add(id)
if (watcher) ensureWatchedFile(watcher, id, root)
}
getWatchFiles() {
return [...watchFiles]
}
warn() {
// 打印 warning 信息
}
error() {
// 打印 error 信息
}
// 其它方法只是声明,并没有具体实现,这里就省略了
}很显然,Vite 将 Rollup 的PluginContext对象重新实现了一遍,因为只是开发阶段用到,所以去除了一些打包相关的方法实现。同时,上下文对象与 Vite 开发阶段的 ModuleGraph 即模块依赖图相结合,是为了实现开发时的 热更新(HMR)。
另外,transform 钩子也会绑定一个插件上下文对象,不过这个对象和其它钩子不同,实现代码精简如下:
class TransformContext extends Context {
constructor(filename: string, code: string, inMap?: SourceMap | string) {
super()
this.filename = filename
this.originalCode = code
if (inMap) {
this.sourcemapChain.push(inMap)
}
}
_getCombinedSourcemap(createIfNull = false) {
return this.combinedMap
}
getCombinedSourcemap() {
return this._getCombinedSourcemap(true) as SourceMap
}
}可以看到,TransformContext继承自之前所说的Context对象,也就是说 transform 钩子的上下文对象相比其它钩子只是做了一些扩展,增加了 sourcemap 合并的功能,将不同插件的 transform 钩子执行后返回的 sourcemap 进行合并,以保证 sourcemap 的准确性和完整性。
插件工作流概览
让我们把目光集中在resolvePlugins的实现上,Vite 所有的插件就是在这里被收集起来的。具体实现如下:
export async function resolvePlugins(
config: ResolvedConfig,
prePlugins: Plugin[],
normalPlugins: Plugin[],
postPlugins: Plugin[]
): Promise<Plugin[]> {
const isBuild = config.command === 'build'
// 收集生产环境构建的插件,后文会介绍
const buildPlugins = isBuild
? (await import('../build')).resolveBuildPlugins(config)
: { pre: [], post: [] }
return [
// 1. 别名插件
isBuild ? null : preAliasPlugin(),
aliasPlugin({ entries: config.resolve.alias }),
// 2. 用户自定义 pre 插件(带有`enforce: "pre"`属性)
...prePlugins,
// 3. Vite 核心构建插件
// 数量比较多,暂时省略代码
// 4. 用户插件(不带有 `enforce` 属性)
...normalPlugins,
// 5. Vite 生产环境插件 & 用户插件(带有 `enforce: "post"`属性)
definePlugin(config),
cssPostPlugin(config),
...buildPlugins.pre,
...postPlugins,
...buildPlugins.post,
// 6. 一些开发阶段特有的插件
...(isBuild
? []
: [clientInjectionsPlugin(config), importAnalysisPlugin(config)])
].filter(Boolean) as Plugin[]
}从上述代码中我们可以总结出 Vite 插件的具体执行顺序。
- 别名插件包括
vite:pre-alias和@rollup/plugin-alias,用于路径别名替换。 - 用户自定义 pre 插件,也就是带有
enforce: "pre"属性的自定义插件。 - Vite 核心构建插件,这部分插件为 Vite 的核心编译插件,数量比较多,我们在下部分一一拆解。
- 用户自定义的普通插件,即不带有
enforce属性的自定义插件。 Vite 生产环境插件和用户插件中带有enforce: "post"属性的插件。- 一些开发阶段特有的插件,包括环境变量注入插件
clientInjectionsPlugin和 import 语句分析及重写插件importAnalysisPlugin。
插件功能梳理
除用户自定义插件之外,我们需要梳理的 Vite 内置插件有下面这几类:
- 别名插件
- 核心构建插件
- 生产环境特有插件
- 开发环境特有插件
1. 别名插件
别名插件有两个,分别是 vite:pre-alias 和 @rollup/plugin-alias。 前者主要是为了将 bare import 路径重定向到预构建依赖的路径,如:
// 假设 React 已经过 Vite 预构建
import React from 'react';
// 会被重定向到预构建产物的路径
import React from '/node_modules/.vite/react.js'后者则是实现了比较通用的路径别名(即resolve.alias配置)的功能,使用的是 Rollup 官方 Alias 插件。
2. 核心构建插件
2.1 module preload 特性的 Polyfill
当你在 Vite 配置文件中开启下面这个配置时:
{
build: {
polyfillModulePreload: true
}
}Vite 会自动应用 modulePreloadPolyfillPlugin 插件,在产物中注入 module preload 的 Polyfill 代码,具体实现 摘自之前我们提到过的 es-module-shims 这个库,实现原理如下:
- 扫描出当前所有的 modulepreload 标签,拿到 link 标签对应的地址,通过执行 fetch 实现预加载;
- 同时通过 MutationObserver 监听 DOM 的变化,一旦发现包含 modulepreload 属性的 link 标签,则同样通过 fetch 请求实现预加载。
由于部分支持原生 ESM 的浏览器并不支持 module preload,因此某些情况下需要注入相应的 polyfill 进行降级。
2.2 路径解析插件
路径解析插件(即vite:resolve)是 Vite 中比较核心的插件,几乎所有重要的 Vite 特性都离不开这个插件的实现,诸如依赖预构建、HMR、SSR 等等。同时它也是实现相当复杂的插件,一方面实现了 Node.js 官方的 resolve 算法,另一方面需要支持前面所说的各项特性,可以说是专门给 Vite 实现了一套路径解析算法。
2.3 内联脚本加载插件
对于 HTML 中的内联脚本,Vite 会通过 vite:html-inline-script-proxy 插件来进行加载。比如下面这个 script 标签:
<script type="module">
import React from 'react';
console.log(React)
</script>这些内容会在后续的build-html插件从 HTML 代码中剔除,并且变成下面的这一行代码插入到项目入口模块的代码中:
import '/User/xxx/vite-app/index.html?http-proxy&index=0.js'而 vite:html-inline-script-proxy 就是用来加载这样的模块,实现如下:
const htmlProxyRE = /\?html-proxy&index=(\d+)\.js$/
export function htmlInlineScriptProxyPlugin(config: ResolvedConfig): Plugin {
return {
name: 'vite:html-inline-script-proxy',
load(id) {
const proxyMatch = id.match(htmlProxyRE)
if (proxyMatch) {
const index = Number(proxyMatch[1])
const file = cleanUrl(id)
const url = file.replace(normalizePath(config.root), '')
// 内联脚本的内容会被记录在 htmlProxyMap 这个表中
const result = htmlProxyMap.get(config)!.get(url)![index]
if (typeof result === 'string') {
// 加载脚本的具体内容
return result
} else {
throw new Error(`No matching HTML proxy module found from ${id}`)
}
}
}
}
}2.4 CSS 编译插件
即名为vite:css的插件,主要实现下面这些功能:
CSS 预处理器的编译CSS ModulesPostcss 编译- 通过 @import
记录依赖,便于 HMR
这个插件的核心在于compileCSS函数的实现,感兴趣的同学可以阅读一下这部分的源码。
2.5 Esbuild 转译插件
即名为vite:esbuild的插件,用来进行 .js、.ts、.jsx和tsx,代替了传统的 Babel 或者 TSC 的功能,这也是 Vite 开发阶段性能强悍的一个原因。插件中主要的逻辑是transformWithEsbuild函数,顾名思义,你可以通过这个函数进行代码转译。当然,Vite 本身也导出了这个函数,作为一种通用的 transform 能力,你可以这样来使用:
import { transformWithEsbuild } from 'vite';
// 传入两个参数: code, filename
transformWithEsbuild('<h1>hello</h1>', './index.tsx').then(res => {
// {
// warnings: [],
// code: '/* @__PURE__ */ React.createElement("h1", null, "hello");\n',
// map: {/* sourcemap 信息 */}
// }
console.log(res);
})2.6 静态资源加载插件
静态资源加载插件包括如下几个:
- vite:json 用来加载 JSON 文件,通过
@rollup/pluginutils的dataToEsm方法可实现 JSON 的按名导入,具体实现见链接; - vite:wasm 用来加载
.wasm格式的文件,具体实现见链接; - vite:worker 用来 Web Worker 脚本,插件内部会使用 Rollup 对 Worker 脚本进行打包,具体实现见链接;
- vite:asset,开发阶段实现了其他格式静态资源的加载,而生产环境会通过
renderChunk钩子将静态资源地址重写为产物的文件地址,如./img.png重写为https://cdn.xxx.com/assets/img.91ee297e.png。
值得注意的是,Rollup 本身存在 asset cascade 问题,即静态资源哈希更新,引用它的 JS 的哈希并没有更新(issue 链接)。因此 Vite 在静态资源处理的时候,并没有交给 Rollup 生成资源哈希,而是自己根据资源内容生成哈希(源码实现),并手动进行路径重写,以此避免 asset-cascade 问题。
3. 生产环境特有插件
3.1 全局变量替换插件
提供全局变量替换功能,如下面的这个配置:
// vite.config.ts
const version = '2.0.0';
export default {
define: {
__APP_VERSION__: `JSON.stringify(${version})`
}
}全局变量替换的功能和我们之前在 Rollup 插件中提到的 @rollup/plugin-replace 差不多,当然在实现上 Vite 会有所区别:
开发环境下,Vite 会通过将所有的全局变量挂载到window对象,而不用经过 define 插件的处理,节省编译开销; 生产环境下,Vite 会使用 define 插件,进行字符串替换以及 sourcemap 生成。
特殊情况: SSR 构建会在开发环境经过这个插件,仅替换字符串。
3.2 CSS 后处理插件
CSS 后处理插件即name为vite:css-post的插件,它的功能包括开发阶段 CSS 响应结果处理和生产环境 CSS 文件生成。
首先,在开发阶段,这个插件会将之前的 CSS 编译插件处理后的结果,包装成一个 ESM 模块,返回给浏览器,点击查看实现代码。
其次,生产环境中,Vite 默认会通过这个插件进行 CSS 的 code splitting,即对于每个异步 chunk,Vite 会将其依赖的 CSS 代码单独打包成一个文件,关键代码如下(源码链接):
const fileHandle = this.emitFile({
name: chunk.name + '.css',
type: 'asset',
source: chunkCSS
});如果 CSS 的 code splitting 功能被关闭(通过build.cssCodeSplit配置),那么 Vite 会将所有的 CSS 代码打包到同一个 CSS 文件中,点击查看实现。
最后,插件会调用 Esbuild 对 CSS 进行压缩,实现在 minifyCSS 函数中,点击查看实现。
3.3 HTML 构建插件
HTML 构建插件 即build-html插件。之前我们在内联脚本加载插件中提到过,项目根目录下的html会转换为一段 JavaScript 代码,如下面的这个例子:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
// 普通方式引入
<script src="./index.ts"></script>
// 内联脚本
<script type="module">
import React from 'react';
console.log(React)
</script>
</body>
</html>首先,当 Vite 在生产环境transform这段入口 HTML 时,会做 3 件事情:
对 HTML 执行各个插件中带有
enforce: "pre"属性的 transformIndexHtml 钩子;我们知道插件本身可以带有
enforce: "pre"|"post"属性,而 transformIndexHtml 本身也可以带有这个属性,用于在不同的阶段进行 HTML 转换。后文会介绍 transformIndexHtml 钩子带有enforce: "post"时的执行时机。将其中的 script 标签内容删除,并将其转换为
import 语句如import './index.ts',并记录下来;在 transform 钩子中返回记录下来的 import 内容,将 import 语句作为模块内容进行加载。也就是说,虽然 Vite 处理的是一个 HTML 文件,但最后进行打包的内容却是一段 JS 的内容,点击查看具体实现。代码简化后如下所示:
export function buildHtmlPlugin() {
name: 'vite:build',
transform(html, id) {
if (id.endsWith('.html')) {
let js = '';
// 省略 HTML AST 遍历过程(通过 @vue/compiler-dom 实现)
// 收集 script 标签,转换成 import 语句,拼接到 js 字符串中
return js;
}
}
}其次,在生成产物的最后一步即generateBundle钩子中,拿到入口 Chunk,分析入口 Chunk 的内容, 分情况进行处理。
如果只有 import 语句,先通过 Rollup 提供的 chunk 和 bundle 对象获取入口 chunk 所有的依赖 chunk,并将这些 chunk 进行后序排列,如 a 依赖 b,b 依赖 c,最后的依赖数组就是[c, b, a]。然后依次将 c,b, a 生成三个 script 标签,插入 HTML 中。最后,Vite 会将入口 chunk 的内容从 bundle 产物中移除,因此它的内容只要 import 语句,而它 import 的 chunk 已经作为 script 标签插入到了 HTML 中,那入口 Chunk 的存在也就没有意义了。
如果除了 import 语句,还有其它内容, Vite 就会将入口 Chunk 单独生成一个 script 标签,分析出依赖的后序排列(和上一种情况分析手段一样),然后通过注入 <link rel="modulepreload"> 标签对入口文件的依赖 chunk 进行预加载。
最后,插件会调用用户插件中带有 enforce: "post" 属性的 transformIndexHtml 钩子,对 HTML 进行进一步的处理。点击查看具体实现。
3.3 Commonjs 转换插件
我们知道,在开发环境中,Vite 使用 Esbuild 将 Commonjs 转换为 ESM,而生产环境中,Vite 会直接使用 Rollup 的官方插件 @rollup/plugin-commonjs。
3.4 date-uri 插件
date-uri 插件用来支持 import 模块中含有 Base64 编码的情况,如:
import batman from 'data:application/json;base64, eyAiYmF0bWFuIjogInRydWUiIH0=';3.5 dynamic-import-vars 插件
用于支持在动态 import 中使用变量的功能,如下示例代码:
function importLocale(locale) {
return import(`./locales/${locale}.js`);
}内部使用的是 Rollup 的官方插件 @rollup/plugin-dynamic-import-vars。
3.6 import-meta-url 支持插件
用来转换如下格式的资源 URL:
new URL('./foo.png', import.meta.url)将其转换为生产环境的 URL 格式,如:
// 使用 self.location 来保证低版本浏览器和 Web Worker 环境的兼容性
new URL('./assets.a4b3d56d.png, self.location)同时,对于动态 import 的情况也能进行支持,如下面的这种写法:
function getImageUrl(name) {
return new URL(`./dir/${name}.png`, import.meta.url).href
}Vite 识别到./dir/${name}.png这样的模板字符串,会将整行代码转换成下面这样:
function getImageUrl(name) {
return import.meta.globEager('./dir/**.png')[`./dir/${name}.png`].default;
}3.7 生产环境 import 分析插件
vite:build-import-analysis 插件会在生产环境打包时用作 import 语句分析和重写,主要目的是对动态 import 的模块进行预加载处理。
对含有动态 import 的 chunk 而言,会在插件的 transform 钩子中被添加这样一段工具代码用来进行模块预加载,逻辑并不复杂,你可以参考源码实现。关键代码简化后如下:
function preload(importModule, deps) {
return Promise.all(
deps.map(dep => {
// 如果异步模块的依赖还没有加载
if (!alreadyLoaded(dep)) {
// 创建 link 标签加载,包括 JS 或者 CSS
document.head.appendChild(createLink(dep))
// 如果是 CSS,进行特殊处理,后文会介绍
if (isCss(dep)) {
return new Promise((resolve, reject) => {
link.addEventListener('load', resolve)
link.addEventListener('error', reject)
})
}
}
})
).then(() => importModule())
}Vite 内置了 CSS 代码分割的能力,当一个模块通过动态 import 引入的时候,这个模块会被单独打包成一个 chunk,与此同时这个模块中的样式代码也会打包成单独的 CSS 文件。如果异步模块的 CSS 和 JS 同时进行预加载,那么在某些浏览器下(如 IE)就会出现 FOUC 问题,页面样式会闪烁,影响用户体验。但 Vite 通过监听 link 标签 load 事件的方式来保证 CSS 在 JS 之前加载完成,从而解决了 FOUC 问题。你可以注意下面这段关键代码:
if (isCss) {
return new Promise((res, rej) => {
link.addEventListener('load', res)
link.addEventListener('error', rej)
})
}现在,我们已经知道了预加载的实现方法,那么 Vite 是如何将动态 import 编译成预加载的代码的呢?
从源码的transform钩子实现中,不难发现 Vite 会将动态 import 的代码进行转换,如下代码所示:
// 转换前
import('a')
// 转换后
__vitePreload(() => 'a', true ?"__VITE_PRELOAD__":void)其中,__vitePreload 会被加载为前文中的 preload 工具函数,true 会在 renderChunk 中被替换成 true 或者 false,表示是否为 Modern 模式打包,而对于"__VITE_PRELOAD__",Vite 会在 generateBundle 阶段,分析出 a 模块所有依赖文件(包括 CSS),将依赖文件名的数组作为 preload 工具函数的第二个参数。
同时,对于 Vite 独有的 i
const modules = import.meta.glob('./dir/*.js')会通过插件转换成下面这段代码:
const modules = {
'./dir/foo.js': () => import('./dir/foo.js'),
'./dir/bar.js': () => import('./dir/bar.js')
}具体的实现在 transformImportGlob 函数中,除了被该插件使用外,这个函数被还依赖预构建、开发环境 import 分析等核心流程使用,属于一类比较底层的逻辑,感兴趣的同学可以精读一下这部分的实现源码。
3.8 JS 压缩插件
Vite 中提供了两种 JS 代码压缩的工具,即 Esbuild 和 Terser,分别由两个插件插件实现:
- vite:esbuild-transpile (点击查看实现)。在 renderChunk 阶段,调用 Esbuild 的 transform API,并指定 minify 参数,从而实现 JS 的压缩。
- vite:terser (点击查看实现)。同样也在 renderChunk 阶段,Vite 会单独的 Worker 进程中调用 Terser 进行 JS 代码压缩。
3.9 构建报告插件
主要由三个插件输出构建报告:
- vite:manifest (点击查看实现)。提供打包后的各种资源文件及其关联信息,如下内容所示:json
// manifest.json { "index.html": { "file": "assets/index.8edffa56.js", "src": "index.html", "isEntry": true, "imports": [ // JS 引用 "_vendor.71e8fac3.js" ], "css": [ // 样式文件应用 "assets/index.458f9883.css" ], "assets": [ // 静态资源引用 "assets/img.9f0de7da.png" ] }, "_vendor.71e8fac3.js": { "file": "assets/vendor.71e8fac3.js" } } - vite:ssr-manifest(点击查看实现)。提供每个模块与 chunk 之间的映射关系,方便 SSR 时期通过渲染的组件来确定哪些 chunk 会被使用,从而按需进行预加载。最后插件输出的内容如下:ts
// ssr-manifest.json { "node_modules/object-assign/index.js": [ "/assets/vendor.71e8fac3.js" ], "node_modules/object-assign/index.js?commonjs-proxy": [ "/assets/vendor.71e8fac3.js" ], // 省略其它模块信息 } - vite:reporter(点击查看实现)。主要提供打包时的命令行构建日志。
4. 开发环境特有插件
4.1 客户端环境变量注入插件
在开发环境中,Vite 会自动往 HTML 中注入一段 client 的脚本(点击查看实现):
<script type="module" src="/@vite/client"></script>这段脚本主要提供注入环境变量、处理 HMR 更新逻辑、构建出现错误时提供报错界面等功能,而我们这里要介绍的vite:client-inject就是来完成时环境变量的注入,将 client 脚本中的__MODE__、__BASE__、__DEFINE__等等字符串替换为运行时的变量,实现环境变量以及 HMR 相关上下文信息的注入,点击查看插件实现。
4.2 开发阶段 import 分析插件
最后,Vite 会在开发阶段加入 import 分析插件,即vite:import-analysis。与之前所介绍的vite:build-import-analysis相对应,主要处理 import 语句相关的解析和重写,但 vite:import-analysis 插件的关注点会不太一样,主要围绕 Vite 开发阶段的各项特性来实现,我们可以来梳理一下这个插件需要做哪些事情:
对 bare import,将路径名转换为真实的文件路径,如:
ts// 转换前 import 'foo' // 转换后 // tip: 如果是预构建的依赖,则会转换为预构建产物的路径 import '/@fs/project/node_modules/foo/dist/foo.js'主要调用
PluginContainer的上下文对象方法即this.resolve实现,这个方法会调用所有插件的 resolveId 方法,包括之前介绍的vite:pre-alias和vite:resolve,完成路径解析的核心逻辑。对于 HMR 的客户端 API,即
i,Vite 在识别到这样的 import 语句后,一方面会注入 import.meta.hot mport.meta.hot 的实现,因为浏览器原生并不具备这样的 API,点击查看注入代码;另一方面会识别 accept 方法,并判断 accept 是否为 接受自身更新的类型(如果对 HMR 更新类型还不了解,可以回顾一下HMR),如果是,则标记为上isSelfAccepting的 flag,便于 HMR 在服务端进行更新时进行HMR Boundary的查找。对于具体的查找过程,后面会详细介绍。对于全局环境变量读取语句,即
i,Vite 会注入mport.meta.env i的实现,也就是如下的mport.meta.env env字符串:
// config 即解析完的配置
let env = `import.meta.env = ${JSON.stringify({
...config.env,
SSR: !!ssr
})};`
// 对用户配置的 define 对象中,将带有 import.meta.env 前缀的全局变量挂到 import.meta.env 对象上
for (const key in config.define) {
if (key.startsWith(`import.meta.env. `)) {
const val = config.define[key]
env += `${key} = ${
typeof val === 'string' ? val : JSON.stringify(val)
};`
}
}- 对于
i语法,Vite 同样会调用之前提到的mport.meta.glob transformImportGlob函数来进行语法转换,但与生产环境的处理不同,在转换之后,Vite 会将该模块通过 glob 导入的依赖模块记录在 server 实例上,以便于 HMR 更新的时候能得到更准确的模块依赖信息,点击查看实现。
揭秘 HMR 的实现
基于 HMR Boundary (HMR 边界)的更新模式,即当一个模块发生变动时,Vite 会自动寻找更新边界,然后更新边界模块。
创建模块依赖图
为了方便管理各个模块之间的依赖关系,Vite 在 Dev Server 中创建了模块依赖图的数据结构,即ModuleGraph类,点击查看实现源码,Vite 中 HMR 边界模块的判定会依靠这个类来实现。
接下来,我们从以下几个维度看看这个图结构的创建过程。创建依赖图主要分为三个步骤:
- 初始化依赖图实例
- 创建依赖图节点
- 绑定各个模块节点的依赖关系
首先,Vite 在 Dev Server 启动时会初始化 ModuleGraph 的实例:
// pacakges/vite/src/node/server/index.ts
const moduleGraph: ModuleGraph = new ModuleGraph((url) =>
container.resolveId(url)
);接下来我们具体查看ModuleGraph这个类的实现。其中定义了若干个 Map,用来记录模块信息:
// 由原始请求 url 到模块节点的映射,如 /src/index.tsx
urlToModuleMap = new Map<string, ModuleNode>()
// 由模块 id 到模块节点的映射,其中 id 与原始请求 url,为经过 resolveId 钩子解析后的结果
idToModuleMap = new Map<string, ModuleNode>()
// 由文件到模块节点的映射,由于单文件可能包含多个模块,如 .vue 文件,因此 Map 的 value 值为一个集合
fileToModulesMap = new Map<string, Set<ModuleNode>>()ModuleNode 对象即代表模块节点的具体信息,我们可以来看看它的数据结构:
class ModuleNode {
// 原始请求 url
url: string
// 文件绝对路径 + query
id: string | null = null
// 文件绝对路径
file: string | null = null
type: 'js' | 'css'
info?: ModuleInfo
// resolveId 钩子返回结果中的元数据
meta?: Record<string, any>
// 该模块的引用方
importers = new Set<ModuleNode>()
// 该模块所依赖的模块
importedModules = new Set<ModuleNode>()
// 接受更新的模块
acceptedHmrDeps = new Set<ModuleNode>()
// 是否为`接受自身模块`的更新
isSelfAccepting = false
// 经过 transform 钩子后的编译结果
transformResult: TransformResult | null = null
// SSR 过程中经过 transform 钩子后的编译结果
ssrTransformResult: TransformResult | null = null
// SSR 过程中的模块信息
ssrModule: Record<string, any> | null = null
// 上一次热更新的时间戳
lastHMRTimestamp = 0
constructor(url: string) {
this.url = url
this.type = isDirectCSSRequest(url) ? 'css' : 'js'
}
}ModuleNode 中包含的信息比较多,你需要重点关注的是 importers 和 importedModules,这两条信息分别代表了当前模块被哪些模块引用以及它依赖了哪些模块,是构建整个模块依赖图的根基所在。
那么,Vite 是在什么时候创建 ModuleNode 节点的呢?我们可以到 Vite Dev Server 中的 transform 中间件一探究竟:
// packages/vite/src/node/server/middlewares/transform.ts
// 核心转换逻辑
const result = await transformRequest(url, server, {
html: req.headers.accept?.includes('text/html')
})可以看到,transform 中间件的主要逻辑是调用 transformRequest 方法,我们来进一步查看这个方法的核心代码实现:
// packages/vite/src/node/server/transformRequest.ts
// 从 ModuleGraph 查找模块节点信息
const module = await server.moduleGraph.getModuleByUrl(url)
// 如果有则命中缓存
const cached =
module && (ssr ? module.ssrTransformResult : module.transformResult)
if (cached) {
return cached
}
// 否则调用 PluginContainer 的 resolveId 和 load 方法对进行模块加载
const id = (await pluginContainer.resolveId(url))?.id || url
const loadResult = await pluginContainer.load(id, { ssr })
// 然后通过调用 ensureEntryFromUrl 方法创建 ModuleNode
const mod = await moduleGraph.ensureEntryFromUrl(url)接着我们看看 ensureEntryFromUrl 方法如何创建新的 ModuleNode 节点:
async ensureEntryFromUrl(rawUrl: string): Promise<ModuleNode> {
// 实质是调用各个插件的 resolveId 钩子得到路径信息
const [url, resolvedId, meta] = await this.resolveUrl(rawUrl)
let mod = this.urlToModuleMap.get(url)
if (!mod) {
// 如果没有缓存,就创建新的 ModuleNode 对象
// 并记录到 urlToModuleMap、idToModuleMap、fileToModulesMap 这三张表中
mod = new ModuleNode(url)
if (meta) mod.meta = meta
this.urlToModuleMap.set(url, mod)
mod.id = resolvedId
this.idToModuleMap.set(resolvedId, mod)
const file = (mod.file = cleanUrl(resolvedId))
let fileMappedModules = this.fileToModulesMap.get(file)
if (!fileMappedModules) {
fileMappedModules = new Set()
this.fileToModulesMap.set(file, fileMappedModules)
}
fileMappedModules.add(mod)
}
return mod
}各个节点的依赖关系是在什么时候绑定的呢?我们不妨把目光集中到vite:import-analysis插件当中,在这个插件的 transform 钩子中,会对模块代码中的 import 语句进行分析,得到如下的一些信息:
importedUrls: 当前模块的依赖模块 url 集合。acceptedUrls: 当前模块中通过 import.meta.hot.accept 声明的依赖模块 url 集合。 isSelfAccepting: 分析 import.meta.hot.accept 的用法,标记是否为 接受自身更新的类型。
接下来会进入核心的模块依赖关系绑定的环节,核心代码如下:
// 引用方模块
const importerModule = moduleGraph.getModuleById(importer)
await moduleGraph.updateModuleInfo(
importerModule,
importedUrls,
normalizedAcceptedUrls,
isSelfAccepting
)可以看到,绑定依赖关系的逻辑主要由 ModuleGraph 对象的 updateModuleInfo 方法实现,核心代码如下:
async updateModuleInfo(
mod: ModuleNode,
importedModules: Set<string | ModuleNode>,
acceptedModules: Set<string | ModuleNode>,
isSelfAccepting: boolean
) {
mod.isSelfAccepting = isSelfAccepting
mod.importedModules = new Set()
// 绑定节点依赖关系
for (const imported of importedModules) {
const dep =
typeof imported === 'string'
? await this.ensureEntryFromUrl(imported)
: imported
dep.importers.add(mod)
mod.importedModules.add(dep)
}
// 更新 acceptHmrDeps 信息
const deps = (mod.acceptedHmrDeps = new Set())
for (const accepted of acceptedModules) {
const dep =
typeof accepted === 'string'
? await this.ensureEntryFromUrl(accepted)
: accepted
deps.add(dep)
}
}至此,模块间的依赖关系就成功进行绑定了。随着越来越多的模块经过 vite:import-analysis 的 transform 钩子处理,所有模块之间的依赖关系会被记录下来,整个依赖图的信息也就被补充完整了。
服务端收集更新模块
刚才我们分析了模块依赖图的实现,接下来再看看 Vite 服务端如何根据这个图结构收集更新模块。
首先, Vite 在服务启动时会通过 chokidar 新建文件监听器:
// packages/vite/src/node/server/index.ts
import chokidar from 'chokidar'
// 监听根目录下的文件
const watcher = chokidar.watch(path.resolve(root));
// 修改文件
watcher.on('change', async (file) => {
file = normalizePath(file)
moduleGraph.onFileChange(file)
await handleHMRUpdate(file, server)
})
// 新增文件
watcher.on('add', (file) => {
handleFileAddUnlink(normalizePath(file), server)
})
// 删除文件
watcher.on('unlink', (file) => {
handleFileAddUnlink(normalizePath(file), server, true)
})然后,我们分别以修改文件、新增文件和删除文件这几个方面来介绍 HMR 在服务端的逻辑。
1. 修改文件
当业务代码中某个文件被修改时,Vite 首先会调用moduleGraph的onFileChange对模块图中的对应节点进行清除缓存的操作:
class ModuleGraph {
onFileChange(file: string): void {
const mods = this.getModulesByFile(file)
if (mods) {
const seen = new Set<ModuleNode>()
// 将模块的缓存信息去除
mods.forEach((mod) => {
this.invalidateModule(mod, seen)
})
}
}
invalidateModule(mod: ModuleNode, seen: Set<ModuleNode> = new Set()): void {
mod.info = undefined
mod.transformResult = null
mod.ssrTransformResult = null
}
}然后正式进入 HMR 收集更新的阶段,主要逻辑在handleHMRUpdate函数中,代码简化后如下:
// packages/vite/src/node/server/hmr.ts
export async function handleHMRUpdate(
file: string,
server: ViteDevServer
): Promise<any> {
const { ws, config, moduleGraph } = server
const shortFile = getShortName(file, config.root)
// 1. 配置文件/环境变量声明文件变化,直接重启服务
// 代码省略
// 2. 客户端注入的文件(vite/dist/client/client.mjs)更改
// 给客户端发送 full-reload 信号,使之刷新页面
if (file.startsWith(normalizedClientDir)) {
ws.send({
type: 'full-reload',
path: '*'
})
return
}
// 3. 普通文件变动
// 获取需要更新的模块
const mods = moduleGraph.getModulesByFile(file)
const timestamp = Date.now()
// 初始化 HMR 上下文对象
const hmrContext: HmrContext = {
file,
timestamp,
modules: mods ? [...mods] : [],
read: () => readModifiedFile(file),
server
}
// 依次执行插件的 handleHotUpdate 钩子,拿到插件处理后的 HMR 模块
for (const plugin of config.plugins) {
if (plugin.handleHotUpdate) {
const filteredModules = await plugin.handleHotUpdate(hmrContext)
if (filteredModules) {
hmrContext.modules = filteredModules
}
}
}
// updateModules——核心处理逻辑
updateModules(shortFile, hmrContext.modules, timestamp, server)
}从中可以看到,Vite 对于不同类型的文件,热更新的策略有所不同:
- 对于配置文件和环境变量声明文件的改动,Vite 会直接重启服务器。
- 对于客户端注入的文件(vite/dist/client/client.mjs)的改动,Vite 会给客户端发送
full-reload信号,让客户端刷新页面。 - 对于普通文件改动,Vite 首先会获取需要热更新的模块,然后对这些模块依次查找热更新边界,然后将模块更新的信息传给客户端。
其中,对于普通文件的热更新边界查找的逻辑,主要集中在updateModules函数中,让我们来看看具体的实现:
function updateModules(
file: string,
modules: ModuleNode[],
timestamp: number,
{ config, ws }: ViteDevServer
) {
const updates: Update[] = []
const invalidatedModules = new Set<ModuleNode>()
let needFullReload = false
// 遍历需要热更新的模块
for (const mod of modules) {
invalidate(mod, timestamp, invalidatedModules)
if (needFullReload) {
continue
}
// 初始化热更新边界集合
const boundaries = new Set<{
boundary: ModuleNode
acceptedVia: ModuleNode
}>()
// 调用 propagateUpdate 函数,收集热更新边界
const hasDeadEnd = propagateUpdate(mod, boundaries)
// 返回值为 true 表示需要刷新页面,否则局部热更新即可
if (hasDeadEnd) {
needFullReload = true
continue
}
// 记录热更新边界信息
updates.push(
...[...boundaries].map(({ boundary, acceptedVia }) => ({
type: `${boundary.type}-update` as Update['type'],
timestamp,
path: boundary.url,
acceptedPath: acceptedVia.url
}))
)
}
// 如果被打上 full-reload 标识,则让客户端强制刷新页面
if (needFullReload) {
ws.send({
type: 'full-reload'
})
} else {
config.logger.info(
updates
.map(({ path }) => chalk.green(`hmr update `) + chalk.dim(path))
.join('\n'),
{ clear: true, timestamp: true }
)
ws.send({
type: 'update',
updates
})
}
}
// 热更新边界收集
function propagateUpdate(
node: ModuleNode,
boundaries: Set<{
boundary: ModuleNode
acceptedVia: ModuleNode
}>,
currentChain: ModuleNode[] = [node]
): boolean {
// 接受自身模块更新
if (node.isSelfAccepting) {
boundaries.add({
boundary: node,
acceptedVia: node
})
return false
}
// 入口模块
if (!node.importers.size) {
return true
}
// 遍历引用方
for (const importer of node.importers) {
const subChain = currentChain.concat(importer)
// 如果某个引用方模块接受了当前模块的更新
// 那么将这个引用方模块作为热更新的边界
if (importer.acceptedHmrDeps.has(node)) {
boundaries.add({
boundary: importer,
acceptedVia: node
})
continue
}
if (currentChain.includes(importer)) {
// 出现循环依赖,需要强制刷新页面
return true
}
// 递归向更上层的引用方寻找热更新边界
if (propagateUpdate(importer, boundaries, subChain)) {
return true
}
}
return false
}可以看到,当热更新边界的信息收集完成后,服务端会将这些信息推送给客户端,从而完成局部的模块更新。
2. 新增和删除文件
对于新增和删除文件,Vite 也通过chokidar监听了相应的事件:
watcher.on('add', (file) => {
handleFileAddUnlink(normalizePath(file), server)
})
watcher.on('unlink', (file) => {
handleFileAddUnlink(normalizePath(file), server, true)
})接下来,我们就来浏览一下handleFileAddUnlink的逻辑,代码简化后如下:
export async function handleFileAddUnlink(
file: string,
server: ViteDevServer,
isUnlink = false
): Promise<void> {
const modules = [...(server.moduleGraph.getModulesByFile(file) ?? [])]
if (modules.length > 0) {
updateModules(
getShortName(file, server.config.root),
modules,
Date.now(),
server
)
}
}不难发现,这个函数同样是调用updateModules完成模块热更新边界的查找和更新信息的推送,而updateModules在上文中已经分析过,这里就不再赘述了
客户端派发更新
从前面的内容中,我们知道,服务端会监听文件的改动,然后计算出对应的热更新信息,通过 WebSocket 将更新信息传递给客户端,具体来说,会给客户端发送如下的数据:
{
type: "update",
update: [
{
// 更新类型,也可能是 `css-update`
type: "js-update",
// 更新时间戳
timestamp: 1650702020986,
// 热更模块路径
path: "/src/main.ts",
// 接受的子模块路径
acceptedPath: "/src/render.ts"
}
]
}
// 或者 full-reload 信号
{
type: "full-reload"
}那么客户端是如何接受这些信息并进行模块更新的呢?
从上一节我们知道,Vite 在开发阶段会默认在 HTML 中注入一段客户端的脚本,即:
<script type="module" src="/@vite/client"></script>在启动任意一个 Vite 项目后,我们可以在浏览器查看具体的脚本内容,从中你可以发现,客户端的脚本中创建了 WebSocket 客户端,并与 Vite Dev Server 中的 WebSocket 服务端(点击查看实现)建立双向连接:
const socketProtocol = null || (location.protocol === 'https:' ? 'wss' : 'ws');
const socketHost = `${null || location.hostname}:${"3000"}`;
const socket = new WebSocket(`${socketProtocol}://${socketHost}`, 'vite-hmr');随后会监听 socket 实例的message事件,接收到服务端传来的更新信息:
socket.addEventListener('message', async ({ data }) => {
handleMessage(JSON.parse(data));
});接下来分析 handleMessage 函数:
async function handleMessage(payload: HMRPayload) {
switch (payload.type) {
case 'connected':
console.log(`[vite] connected.`)
// 心跳检测
setInterval(() => socket.send('ping'), __HMR_TIMEOUT__)
break
case 'update':
payload.updates.forEach((update) => {
if (update.type === 'js-update') {
queueUpdate(fetchUpdate(update))
} else {
// css-update
// 省略实现
console.log(`[vite] css hot updated: ${path}`)
}
})
break
case 'full-reload':
// 刷新页面
location.reload()
// 省略其它消息类型
}
}我们重点关注 js 的更新逻辑,即下面这行代码:
queueUpdate(fetchUpdate(update))先来看看queueUpdate和fetchUpdate这两个函数的实现:
let pending = false
let queued: Promise<(() => void) | undefined>[] = []
// 批量任务处理,不与具体的热更新行为挂钩,主要起任务调度作用
async function queueUpdate(p: Promise<(() => void) | undefined>) {
queued.push(p)
if (!pending) {
pending = true
await Promise.resolve()
pending = false
const loading = [...queued]
queued = []
;(await Promise.all(loading)).forEach((fn) => fn && fn())
}
}
// 派发热更新的主要逻辑
async function fetchUpdate({ path, acceptedPath, timestamp }: Update) {
// 后文会介绍 hotModuleMap 的作用,你暂且不用纠结实现,可以理解为 HMR 边界模块相关的信息
const mod = hotModulesMap.get(path)
const moduleMap = new Map()
const isSelfUpdate = path === acceptedPath
// 1. 整理需要更新的模块集合
const modulesToUpdate = new Set<string>()
if (isSelfUpdate) {
// 接受自身更新
modulesToUpdate.add(path)
} else {
// 接受子模块更新
for (const { deps } of mod.callbacks) {
deps.forEach((dep) => {
if (acceptedPath === dep) {
modulesToUpdate.add(dep)
}
})
}
}
// 2. 整理需要执行的更新回调函数
// 注: mod.callbacks 为 import.meta.hot.accept 中绑定的更新回调函数,后文会介绍
const qualifiedCallbacks = mod.callbacks.filter(({ deps }) => {
return deps.some((dep) => modulesToUpdate.has(dep))
})
// 3. 对将要更新的模块进行失活操作,并通过动态 import 拉取最新的模块信息
await Promise.all(
Array.from(modulesToUpdate).map(async (dep) => {
const disposer = disposeMap.get(dep)
if (disposer) await disposer(dataMap.get(dep))
const [path, query] = dep.split(`?`)
try {
const newMod = await import(
/* @vite-ignore */
base +
path.slice(1) +
`?import&t=${timestamp}${query ? `&${query}` : ''}`
)
moduleMap.set(dep, newMod)
} catch (e) {
warnFailedFetch(e, dep)
}
})
)
// 4. 返回一个函数,用来执行所有的更新回调
return () => {
for (const { deps, fn } of qualifiedCallbacks) {
fn(deps.map((dep) => moduleMap.get(dep)))
}
const loggedPath = isSelfUpdate ? path : `${acceptedPath} via ${path}`
console.log(`[vite] hot updated: ${loggedPath}`)
}
}对热更新的边界模块来讲,我们需要在客户端获取这些信息:
- 边界模块所接受(accept)的模块
- accept 的模块触发更新后的回调
在 vite:import-analysis 插件中,会给包含热更新逻辑的模块注入一些工具代码,createHotContext 同样是客户端脚本中的一个工具函数,我们来看看它主要的实现:
const hotModulesMap = new Map<string, HotModule>()
export const createHotContext = (ownerPath: string) => {
// 将当前模块的接收模块信息和更新回调注册到 hotModulesMap
function acceptDeps(deps: string[], callback: HotCallback['fn'] = () => {}) {
const mod: HotModule = hotModulesMap.get(ownerPath) || {
id: ownerPath,
callbacks: []
}
mod.callbacks.push({
deps,
fn: callback
})
hotModulesMap.set(ownerPath, mod)
}
return {
// import.meta.hot.accept
accept(deps: any, callback?: any) {
if (typeof deps === 'function' || !deps) {
acceptDeps([ownerPath], ([mod]) => deps && deps(mod))
} else if (typeof deps === 'string') {
acceptDeps([deps], ([mod]) => callback && callback(mod))
} else if (Array.isArray(deps)) {
acceptDeps(deps, callback)
} else {
throw new Error(`invalid hot.accept() usage.`)
}
},
// import.meta.hot.dispose
// import.meta.hot.invalidate
// 省略更多方法的实现
}
}因此,Vite 给每个热更新边界模块注入的工具代码主要有两个作用:
- 注入 i
mport.meta.hot 对象的实现 - 将当前模块 accept 过的模块和更新回调函数记录到 hotModulesMap 表中
而前面所说的 fetchUpdate 函数则是通过 hotModuleMap 来获取边界模块的相关信息,在 accept 的模块发生变动后,通过动态 import 拉取最新的模块内容,然后返回更新回调,让queueUpdate这个调度函数执行更新回调,从而完成派发更新的过程。至此,HMR 的过程就结束了。
手写 Vite
在开始代码实战之前,先给大家梳理一下需要完成的模块和功能,让大家有一个整体的认知:
首先,我们会进行开发环境的搭建,安装必要的依赖,并搭建项目的构建脚本,同时完成 cli 工具的初始化代码。
然后我们正式开始实现
依赖预构建的功能,通过 Esbuild 实现依赖扫描和依赖构建的功能。接着开始搭建 Vite 的插件机制,也就是开发
PluginContainer和PluginContext两个主要的对象。搭建完插件机制之后,我们将会开发一系列的插件来实现 no-bundle 服务的编译构建能力,包括入口 HTML 处理、 TS/TSX/JS/TSX 编译、CSS 编译和静态资源处理。
最后,我们会实现一套系统化的模块热更新的能力,从搭建模块依赖图开始,逐步实现 HMR 服务端和客户端的开发。
搭建开发环境
首先,你可以执行pnpm init -y来初始化项目,然后安装一些必要的依赖,执行命令如下:
# 运行时依赖
pnpm i cac chokidar connect debug es-module-lexer esbuild fs-extra magic-string picocolors resolve rollup sirv ws -S
# 开发环境依赖
pnpm i @types/connect @types/debug @types/fs-extra @types/resolve @types/ws tsupVite 本身使用的是 Rollup 进行自身的打包,但之前给大家介绍的 tsup 也能够实现库打包的功能,并且内置 esbuild 进行提速,性能上更加强悍,因此在这里我们使用 tsup 进行项目的构建。
为了接入 tsup 打包功能,你需要在 package.json 中加入这些命令:
{
"scripts": {
"start": "tsup --watch",
"build": "tsup --minify"
}
}同时,你需要在项目根目录新建tsconfig.json和tsup.config.ts这两份配置文件,内容分别如下:
// tsconfig.json
{
"compilerOptions": {
// 支持 commonjs 模块的 default import,如 import path from 'path'
// 否则只能通过 import * as path from 'path' 进行导入
"esModuleInterop": true,
"target": "ES2020",
"moduleResolution": "node",
"module": "ES2020",
"strict": true
}
}// tsup.config.ts
import { defineConfig } from "tsup";
export default defineConfig({
// 后续会增加 entry
entry: {
index: "src/node/cli.ts",
},
// 产物格式,包含 esm 和 cjs 格式
format: ["esm", "cjs"],
// 目标语法
target: "es2020",
// 生成 sourcemap
sourcemap: true,
// 没有拆包的需求,关闭拆包能力
splitting: false,
});接着新建 src/node/cli.ts 文件,我们进行 cli 的初始化:
// src/node/cli.ts
import cac from "cac";
const cli = cac();
// [] 中的内容为可选参数,也就是说仅输入 `vite` 命令下会执行下面的逻辑
cli
.command("[root]", "Run the development server")
.alias("serve")
.alias("dev")
.action(async () => {
console.log('测试 cli~');
});
cli.help();
cli.parse();现在可以执行 pnpm start 来编译这个mini-vite项目,tsup 会生成产物目录dist,然后你可以新建bin/mini-vite文件来引用产物:
#!/usr/bin/env node
require("../dist/index.js");同时,你需要在 package.json 中注册mini-vite命令,配置如下:
{
"bin": {
"mini-vite": "bin/mini-vite"
}
}如此一来,我们就可以在业务项目中使用 mini-vite 这个命令了。Github 仓库中准备了一个示例的 playground 项目,你可以拿来进行测试,点击查看项目。
将 playground 项目放在 mini-vite 目录中,然后执行 pnpm i,由于项目的dependencies中已经声明了mini-vite:
{
"devDependencies": {
"mini-vite": "../"
}
}mini-vite命令会自动安装到测试项目的node_modules/.bin目录中, 接着我们在playground项目中执行pnpm dev命令(内部执行mini-vite),可以看到如下的 log 信息:
测试 cli~我们把console.log语句换成服务启动的逻辑:
import cac from "cac";
+ import { startDevServer } from "./server";
const cli = cac();
cli
.command("[root]", "Run the development server")
.alias("serve")
.alias("dev")
.action(async () => {
- console.log('测试 cli~');
+ await startDevServer();
});新建 src/node/server/index.ts,内容如下:
// connect 是一个具有中间件机制的轻量级 Node.js 框架。
// 既可以单独作为服务器,也可以接入到任何具有中间件机制的框架中,如 Koa、Express
import connect from "connect";
// picocolors 是一个用来在命令行显示不同颜色文本的工具
import { blue, green } from "picocolors";
export async function startDevServer() {
const app = connect();
const root = process.cwd();
const startTime = Date.now();
app.listen(3000, async () => {
console.log(
green("🚀 No-Bundle 服务已经成功启动!"),
`耗时: ${Date.now() - startTime}ms`
);
console.log(`> 本地访问路径: ${blue("http://localhost:3000")}`);
});
}再次执行pnpm dev,你可以发现终端出现如下的启动日志:

OK,mini-vite 的 cli 功能和服务启动的逻辑目前就已经成功搭建起来了。
依赖预构建
新建src/node/optimizer/index.ts来存放依赖预构建的逻辑:
export async function optimize(root: string) {
// 1. 确定入口
// 2. 从入口处扫描依赖
// 3. 预构建依赖
}然后在服务入口中引入预构建的逻辑:
// src/node/server/index.ts
import connect from "connect";
import { blue, green } from "picocolors";
+ import { optimize } from "../optimizer/index";
export async function startDevServer() {
const app = connect();
const root = process.cwd();
const startTime = Date.now();
app.listen(3000, async () => {
+ await optimize(root);
console.log(
green("🚀 No-Bundle 服务已经成功启动!"),
`耗时: ${Date.now() - startTime}ms`
);
console.log(`> 本地访问路径: ${blue("http://localhost:3000")}`);
});
}接着我们来开发依赖预构建的功能,从上面的代码注释你也可以看出,我们需要完成三部分的逻辑:
- 确定预构建入口
- 从入口开始扫描出用到的依赖
- 对依赖进行预构建
首先是确定入口,为了方便理解,这里我直接约定为 src 目录下的main.tsx文件:
// 需要引入的依赖
import path from "path";
// 1. 确定入口
const entry = path.resolve(root, "src/main.tsx");第二步是扫描依赖:
// 需要引入的依赖
import { build } from "esbuild";
import { green } from "picocolors";
import { scanPlugin } from "./scanPlugin";
// 2. 从入口处扫描依赖
const deps = new Set<string>();
await build({
entryPoints: [entry],
bundle: true,
write: false,
plugins: [scanPlugin(deps)],
});
console.log(
`${green("需要预构建的依赖")}:\n${[...deps]
.map(green)
.map((item) => ` ${item}`)
.join("\n")}`
);依赖扫描需要我们借助 Esbuild 插件来完成,最后会记录到 deps 这个集合中。接下来我们来着眼于 Esbuild 依赖扫描插件的开发,你需要在optimzier目录中新建scanPlguin.ts文件,内容如下:
// src/node/optimizer/scanPlugin.ts
import { Plugin } from "esbuild";
import { BARE_IMPORT_RE, EXTERNAL_TYPES } from "../constants";
export function scanPlugin(deps: Set<string>): Plugin {
return {
name: "esbuild:scan-deps",
setup(build) {
// 忽略的文件类型
build.onResolve(
{ filter: new RegExp(`\\.(${EXTERNAL_TYPES.join("|")})$`) },
(resolveInfo) => {
return {
path: resolveInfo.path,
// 打上 external 标记
external: true,
};
}
);
// 记录依赖
build.onResolve(
{
filter: BARE_IMPORT_RE,
},
(resolveInfo) => {
const { path: id } = resolveInfo;
// 推入 deps 集合中
deps.add(id);
return {
path: id,
external: true,
};
}
);
},
};
}需要说明的是,文件中用到了一些常量,在src/node/constants.ts中定义,内容如下:
export const EXTERNAL_TYPES = [
"css",
"less",
"sass",
"scss",
"styl",
"stylus",
"pcss",
"postcss",
"vue",
"svelte",
"marko",
"astro",
"png",
"jpe?g",
"gif",
"svg",
"ico",
"webp",
"avif",
];
export const BARE_IMPORT_RE = /^[\w@][^:]/;插件的逻辑非常简单,即把一些无关的资源进行 external,不让 esbuild 处理,防止 Esbuild 报错,同时将bare import的路径视作第三方包,推入 deps 集合中。
现在,我们在playground项目根路径中执行pnpm dev,可以发现依赖扫描已经成功执行:
当我们收集到所有的依赖信息之后,就可以对每个依赖进行打包,完成依赖预构建了:
// src/node/optimizer/index.ts
// 需要引入的依赖
import { preBundlePlugin } from "./preBundlePlugin";
import { PRE_BUNDLE_DIR } from "../constants";
// 3. 预构建依赖
await build({
entryPoints: [...deps],
write: true,
bundle: true,
format: "esm",
splitting: true,
outdir: path.resolve(root, PRE_BUNDLE_DIR),
plugins: [preBundlePlugin(deps)],
});在此,我们引入了一个新的常量PRE_BUNDLE_DIR,定义如下:
// src/node/constants.ts
// 增加如下代码
import path from "path";
// 预构建产物默认存放在 node_modules 中的 .m-vite 目录中
export const PRE_BUNDLE_DIR = path.join("node_modules", ".m-vite");接着,我们继续开发预构建的 Esbuild 插件。首先,考虑到兼容 Windows 系统,我们先加入一段工具函数的代码:
// src/node/utils.ts
import os from "os";
export function slash(p: string): string {
return p.replace(/\\/g, "/");
}
export const isWindows = os.platform() === "win32";
export function normalizePath(id: string): string {
return path.posix.normalize(isWindows ? slash(id) : id);
}然后完善预构建的代码:
import { Loader, Plugin } from "esbuild";
import { BARE_IMPORT_RE } from "../constants";
// 用来分析 es 模块 import/export 语句的库
import { init, parse } from "es-module-lexer";
import path from "path";
// 一个实现了 node 路径解析算法的库
import resolve from "resolve";
// 一个更加好用的文件操作库
import fs from "fs-extra";
// 用来开发打印 debug 日志的库
import createDebug from "debug";
import { normalizePath } from "../utils";
const debug = createDebug("dev");
export function preBundlePlugin(deps: Set<string>): Plugin {
return {
name: "esbuild:pre-bundle",
setup(build) {
build.onResolve(
{
filter: BARE_IMPORT_RE,
},
(resolveInfo) => {
const { path: id, importer } = resolveInfo;
const isEntry = !importer;
// 命中需要预编译的依赖
if (deps.has(id)) {
// 若为入口,则标记 dep 的 namespace
return isEntry
? {
path: id,
namespace: "dep",
}
: {
// 因为走到 onResolve 了,所以这里的 path 就是绝对路径了
path: resolve.sync(id, { basedir: process.cwd() }),
};
}
}
);
// 拿到标记后的依赖,构造代理模块,交给 esbuild 打包
build.onLoad(
{
filter: /.*/,
namespace: "dep",
},
async (loadInfo) => {
await init;
const id = loadInfo.path;
const root = process.cwd();
const entryPath = normalizePath(resolve.sync(id, { basedir: root }));
const code = await fs.readFile(entryPath, "utf-8");
const [imports, exports] = await parse(code);
let proxyModule = [];
// cjs
if (!imports.length && !exports.length) {
// 构造代理模块
// 下面的代码后面会解释
const res = require(entryPath);
const specifiers = Object.keys(res);
proxyModule.push(
`export { ${specifiers.join(",")} } from "${entryPath}"`,
`export default require("${entryPath}")`
);
} else {
// esm 格式比较好处理,export * 或者 export default 即可
if (exports.includes("default")) {
proxyModule.push(`import d from "${entryPath}";export default d`);
}
proxyModule.push(`export * from "${entryPath}"`);
}
debug("代理模块内容: %o", proxyModule.join("\n"));
const loader = path.extname(entryPath).slice(1);
return {
loader: loader as Loader,
contents: proxyModule.join("\n"),
resolveDir: root,
};
}
);
},
};
}值得一提的是,对于 CommonJS 格式的依赖,单纯用 export default require('入口路径') 是有局限性的,比如对于 React 而言,用这样的方式生成的产物最后只有 default 导出:
// esbuild 的打包产物
// 省略大部分代码
export default react_default;那么用户在使用这个依赖的时候,必须这么使用:
// ✅ 正确
import React from 'react';
const { useState } = React;
// ❌ 报错
import { useState } from 'react';那为什么上述会报错的语法在 Vite 是可以正常使用的呢?原因是 Vite 在做 import 语句分析的时候,自动将你的代码进行改写了:
// 原来的写法
import { useState } from 'react';
// Vite 的 importAnalysis 插件转换后的写法类似下面这样
import react_default from '/node_modules/.vite/react.js';
const { useState } = react_default;那么,还有没有别的方案来解决这个问题?没错,上述的插件代码中已经用另一个方案解决了这个问题,我们不妨把目光集中在下面这段代码中:
if (!imports.length && !exports.length) {
// 构造代理模块
// 通过 require 拿到模块的导出对象
const res = require(entryPath);
// 用 Object.keys 拿到所有的具名导出
const specifiers = Object.keys(res);
// 构造 export 语句交给 Esbuild 打包
proxyModule.push(
`export { ${specifiers.join(",")} } from "${entryPath}"`,
`export default require("${entryPath}")`
);
}如此一来,Esbuild 预构建的产物中便会包含 CommonJS 模块中所有的导出信息:
// 预构建产物导出代码
export {
react_default as default,
useState,
useEffect,
// 省略其它导出
}OK,接下来让我们来测试一下预构建整体的功能。在 playground 项目中执行 pnpm dev,接着去项目的 node_modules 目录中,可以发现新增了.m-vite 目录及react、react-dom的预构建产物:
插件机制开发
首先,新建src/node/pluginContainer.ts文件,增加如下的类型定义:
import type {
LoadResult,
PartialResolvedId,
SourceDescription,
PluginContext as RollupPluginContext,
ResolvedId,
} from "rollup";
export interface PluginContainer {
resolveId(id: string, importer?: string): Promise<PartialResolvedId | null>;
load(id: string): Promise<LoadResult | null>;
transform(code: string, id: string): Promise<SourceDescription | null>;
}另外,由于插件容器需要接收 Vite 插件作为初始化参数,因此我们需要提前声明插件的类型,你可以继续新建src/node/plugin.ts来声明如下的插件类型:
import { LoadResult, PartialResolvedId, SourceDescription } from "rollup";
import { ServerContext } from "./server";
export type ServerHook = (
server: ServerContext
) => (() => void) | void | Promise<(() => void) | void>;
// 只实现以下这几个钩子
export interface Plugin {
name: string;
configureServer?: ServerHook;
resolveId?: (
id: string,
importer?: string
) => Promise<PartialResolvedId | null> | PartialResolvedId | null;
load?: (id: string) => Promise<LoadResult | null> | LoadResult | null;
transform?: (
code: string,
id: string
) => Promise<SourceDescription | null> | SourceDescription | null;
transformIndexHtml?: (raw: string) => Promise<string> | string;
}对于其中的 ServerContext,暂时不用过于关心,只需要在server/index.ts中简单声明一下类型即可:
// src/node/server/index.ts
// 增加如下类型声明
export interface ServerContext {}接着,我们来实现插件机制的具体逻辑,主要集中在createPluginContainer函数中:
// src/node/pluginContainer.ts
// 模拟 Rollup 的插件机制
export const createPluginContainer = (plugins: Plugin[]): PluginContainer => {
// 插件上下文对象
// @ts-ignore 这里仅实现上下文对象的 resolve 方法
class Context implements RollupPluginContext {
async resolve(id: string, importer?: string) {
let out = await pluginContainer.resolveId(id, importer);
if (typeof out === "string") out = { id: out };
return out as ResolvedId | null;
}
}
// 插件容器
const pluginContainer: PluginContainer = {
async resolveId(id: string, importer?: string) {
const ctx = new Context() as any;
for (const plugin of plugins) {
if (plugin.resolveId) {
const newId = await plugin.resolveId.call(ctx as any, id, importer);
if (newId) {
id = typeof newId === "string" ? newId : newId.id;
return { id };
}
}
}
return null;
},
async load(id) {
const ctx = new Context() as any;
for (const plugin of plugins) {
if (plugin.load) {
const result = await plugin.load.call(ctx, id);
if (result) {
return result;
}
}
}
return null;
},
async transform(code, id) {
const ctx = new Context() as any;
for (const plugin of plugins) {
if (plugin.transform) {
const result = await plugin.transform.call(ctx, code, id);
if (!result) continue;
if (typeof result === "string") {
code = result;
} else if (result.code) {
code = result.code;
}
}
}
return { code };
},
};
return pluginContainer;
};接着,我们来完善一下之前的服务器逻辑:
// src/node/server/index.ts
import connect from "connect";
import { blue, green } from "picocolors";
import { optimize } from "../optimizer/index";
+ import { resolvePlugins } from "../plugins";
+ import { createPluginContainer, PluginContainer } from "../pluginContainer";
export interface ServerContext {
+ root: string;
+ pluginContainer: PluginContainer;
+ app: connect.Server;
+ plugins: Plugin[];
}
export async function startDevServer() {
const app = connect();
const root = process.cwd();
const startTime = Date.now();
+ const plugins = resolvePlugins();
+ const pluginContainer = createPluginContainer(plugins);
+ const serverContext: ServerContext = {
+ root: process.cwd(),
+ app,
+ pluginContainer,
+ plugins,
+ };
+ for (const plugin of plugins) {
+ if (plugin.configureServer) {
+ await plugin.configureServer(serverContext);
+ }
+ }
app.listen(3000, async () => {
await optimize(root);
console.log(
green("🚀 No-Bundle 服务已经成功启动!"),
`耗时: ${Date.now() - startTime}ms`
);
console.log(`> 本地访问路径: ${blue("http://localhost:3000")}`);
});
}其中 resolvePlugins 方法我们还未定义,你可以新建 src/node/plugins/index.ts 文件,内容如下:
import { Plugin } from "../plugin";
export function resolvePlugins(): Plugin[] {
// 下一部分会逐个补充插件逻辑
return [];
}入口 HTML 加载
首先要考虑的就是入口 HTML 如何编译和加载的问题,这里我们可以通过一个服务中间件,配合插件机制来实现。具体而言,你可以新建 src/node/server/middlewares/indexHtml.ts,内容如下:
import { NextHandleFunction } from "connect";
import { ServerContext } from "../index";
import path from "path";
import { pathExists, readFile } from "fs-extra";
export function indexHtmlMiddware(
serverContext: ServerContext
): NextHandleFunction {
return async (req, res, next) => {
if (req.url === "/") {
const { root } = serverContext;
// 默认使用项目根目录下的 index.html
const indexHtmlPath = path.join(root, "index.html");
if (await pathExists(indexHtmlPath)) {
const rawHtml = await readFile(indexHtmlPath, "utf8");
let html = rawHtml;
// 通过执行插件的 transformIndexHtml 方法来对 HTML 进行自定义的修改
for (const plugin of serverContext.plugins) {
if (plugin.transformIndexHtml) {
html = await plugin.transformIndexHtml(html);
}
}
res.statusCode = 200;
res.setHeader("Content-Type", "text/html");
return res.end(html);
}
}
return next();
};
}然后在服务中应用这个中间件:
// src/node/server/index.ts
// 需要增加的引入语句
import { indexHtmlMiddware } from "./middlewares/indexHtml";
// 省略中间的代码
// 处理入口 HTML 资源
app.use(indexHtmlMiddware(serverContext));
app.listen(3000, async () => {
// 省略
});接下来通过pnpm dev启动项目,然后访问http://localhost:3000,从网络面板中你可以查看到 HTML 的内容已经成功返回:
不过当前的页面并没有任何内容,因为 HTML 中引入的 TSX 文件并没有被正确编译。接下来,我们就来处理 TSX 文件的编译工作。
JS/TS/JSX/TSX 编译能力
首先新增一个中间件src/node/server/middlewares/transform.ts,内容如下:
import { NextHandleFunction } from "connect";
import {
isJSRequest,
cleanUrl,
} from "../../utils";
import { ServerContext } from "../index";
import createDebug from "debug";
const debug = createDebug("dev");
export async function transformRequest(
url: string,
serverContext: ServerContext
) {
const { pluginContainer } = serverContext;
url = cleanUrl(url);
// 简单来说,就是依次调用插件容器的 resolveId、load、transform 方法
const resolvedResult = await pluginContainer.resolveId(url);
let transformResult;
if (resolvedResult?.id) {
let code = await pluginContainer.load(resolvedResult.id);
if (typeof code === "object" && code !== null) {
code = code.code;
}
if (code) {
transformResult = await pluginContainer.transform(
code as string,
resolvedResult?.id
);
}
}
return transformResult;
}
export function transformMiddleware(
serverContext: ServerContext
): NextHandleFunction {
return async (req, res, next) => {
if (req.method !== "GET" || !req.url) {
return next();
}
const url = req.url;
debug("transformMiddleware: %s", url);
// transform JS request
if (isJSRequest(url)) {
// 核心编译函数
let result = await transformRequest(url, serverContext);
if (!result) {
return next();
}
if (result && typeof result !== "string") {
result = result.code;
}
// 编译完成,返回响应给浏览器
res.statusCode = 200;
res.setHeader("Content-Type", "application/javascript");
return res.end(result);
}
next();
};
}同时,我们也需要补充如下的工具函数和常量定义:
// src/node/utils.ts
import { JS_TYPES_RE } from './constants.ts'
export const isJSRequest = (id: string): boolean => {
id = cleanUrl(id);
if (JS_TYPES_RE.test(id)) {
return true;
}
if (!path.extname(id) && !id.endsWith("/")) {
return true;
}
return false;
};
export const cleanUrl = (url: string): string =>
url.replace(HASH_RE, "").replace(QEURY_RE, "");
// src/node/constants.ts
export const JS_TYPES_RE = /\.(?:j|t)sx?$|\.mjs$/;
export const QEURY_RE = /\?.*$/s;
export const HASH_RE = /#.*$/s;从如上的核心编译函数transformRequest可以看出,Vite 对于 JS/TS/JSX/TSX 文件的编译流程主要是依次调用插件容器的如下方法:
- resolveId
- load
- transform
其中会经历众多插件的处理逻辑,那么,对于 TSX 文件的编译逻辑,也分散到了各个插件当中,具体来说主要包含以下的插件:
- 路径解析插件
- Esbuild 语法编译插件
- import 分析插件
1. 路径解析插件
当浏览器解析到如下的标签时:
<script type="module" src="/src/main.tsx"></script>会自动发送一个路径为/src/main.tsx的请求,但如果服务端不做任何处理,是无法定位到源文件的,随之会返回 404 状态码。
因此,我们需要开发一个路径解析插件,对请求的路径进行处理,使之能转换真实文件系统中的路径。你可以新建文件src/node/plugins/resolve.ts,内容如下:
import resolve from "resolve";
import { Plugin } from "../plugin";
import { ServerContext } from "../server/index";
import path from "path";
import { pathExists } from "fs-extra";
import { DEFAULT_EXTERSIONS } from "../constants";
import { cleanUrl, normalizePath } from "../utils";
export function resolvePlugin(): Plugin {
let serverContext: ServerContext;
return {
name: "m-vite:resolve",
configureServer(s) {
// 保存服务端上下文
serverContext = s;
},
async resolveId(id: string, importer?: string) {
// 1. 绝对路径
if (path.isAbsolute(id)) {
if (await pathExists(id)) {
return { id };
}
// 加上 root 路径前缀,处理 /src/main.tsx 的情况
id = path.join(serverContext.root, id);
if (await pathExists(id)) {
return { id };
}
}
// 2. 相对路径
else if (id.startsWith(".")) {
if (!importer) {
throw new Error("`importer` should not be undefined");
}
const hasExtension = path.extname(id).length > 1;
let resolvedId: string;
// 2.1 包含文件名后缀
// 如 ./App.tsx
if (hasExtension) {
resolvedId = normalizePath(resolve.sync(id, { basedir: path.dirname(importer) }));
if (await pathExists(resolvedId)) {
return { id: resolvedId };
}
}
// 2.2 不包含文件名后缀
// 如 ./App
else {
// ./App -> ./App.tsx
for (const extname of DEFAULT_EXTERSIONS) {
try {
const withExtension = `${id}${extname}`;
resolvedId = normalizePath(resolve.sync(withExtension, {
basedir: path.dirname(importer),
}));
if (await pathExists(resolvedId)) {
return { id: resolvedId };
}
} catch (e) {
continue;
}
}
}
}
return null;
},
};
}这样对于 /src/main.tsx,在插件中会转换为文件系统中的真实路径,从而让模块在 load 钩子中能够正常加载(加载逻辑在 Esbuild 语法编译插件实现)。
接着我们来补充一下目前缺少的常量:
// src/node/constants.ts
export const DEFAULT_EXTERSIONS = [".tsx", ".ts", ".jsx", "js"];2. Esbuild 语法编译插件
这个插件的作用比较好理解,就是将 JS/TS/JSX/TSX 编译成浏览器可以识别的 JS 语法,可以利用 Esbuild 的 Transform API 来实现。你可以新建src/node/plugins/esbuild.ts文件,内容如下:
import { readFile } from "fs-extra";
import { Plugin } from "../plugin";
import { isJSRequest } from "../utils";
import esbuild from "esbuild";
import path from "path";
export function esbuildTransformPlugin(): Plugin {
return {
name: "m-vite:esbuild-transform",
// 加载模块
async load(id) {
if (isJSRequest(id)) {
try {
const code = await readFile(id, "utf-8");
return code;
} catch (e) {
return null;
}
}
},
async transform(code, id) {
if (isJSRequest(id)) {
const extname = path.extname(id).slice(1);
const {code: transformedCode, map} = await esbuild.transform(code, {
target: "esnext",
format: "esm",
sourcemap: true,
loader: extname as "js" | "ts" | "jsx" | "tsx",
});
return {
code: transformedCode,
map,
};
}
return null;
},
};
}3. import 分析插件
在将 TSX 转换为浏览器可以识别的语法之后,是不是就可以直接返回给浏览器执行了呢?
显然不是,我们还考虑如下的一些问题:
- 对于第三方依赖路径(bare import),需要重写为预构建产物路径;
- 对于绝对路径和相对路径,需要借助之前的路径解析插件进行解析。
接下来,我们就在 import 分析插件中一一解决这些问题:
// 新建 src/node/plugins/importAnalysis.ts
import { init, parse } from "es-module-lexer";
import {
BARE_IMPORT_RE,
DEFAULT_EXTERSIONS,
PRE_BUNDLE_DIR,
} from "../constants";
import {
cleanUrl,
isJSRequest,
normalizePath
} from "../utils";
// magic-string 用来作字符串编辑
import MagicString from "magic-string";
import path from "path";
import { Plugin } from "../plugin";
import { ServerContext } from "../server/index";
import { pathExists } from "fs-extra";
import resolve from "resolve";
export function importAnalysisPlugin(): Plugin {
let serverContext: ServerContext;
return {
name: "m-vite:import-analysis",
configureServer(s) {
// 保存服务端上下文
serverContext = s;
},
async transform(code: string, id: string) {
// 只处理 JS 相关的请求
if (!isJSRequest(id)) {
return null;
}
await init;
// 解析 import 语句
const [imports] = parse(code);
const ms = new MagicString(code);
// 对每一个 import 语句依次进行分析
for (const importInfo of imports) {
// 举例说明: const str = `import React from 'react'`
// str.slice(s, e) => 'react'
const { s: modStart, e: modEnd, n: modSource } = importInfo;
if (!modSource) continue;
// 第三方库: 路径重写到预构建产物的路径
if (BARE_IMPORT_RE.test(modSource)) {
const bundlePath = normalizePath(
path.join('/', PRE_BUNDLE_DIR, `${modSource}.js`)
);
ms.overwrite(modStart, modEnd, bundlePath);
} else if (modSource.startsWith(".") || modSource.startsWith("/")) {
// 直接调用插件上下文的 resolve 方法,会自动经过路径解析插件的处理
const resolved = await this.resolve(modSource, id);
if (resolved) {
ms.overwrite(modStart, modEnd, resolved.id);
}
}
}
return {
code: ms.toString(),
// 生成 SourceMap
map: ms.generateMap(),
};
},
};
}现在,我们便完成了 JS 代码的 import 分析工作。接下来,我们把上面实现的三个插件进行注册:
// src/node/plugin/index.ts
import { esbuildTransformPlugin } from "./esbuild";
import { importAnalysisPlugin } from "./importAnalysis";
import { resolvePlugin } from "./resolve";
import { Plugin } from "../plugin";
export function resolvePlugins(): Plugin[] {
return [resolvePlugin(), esbuildTransformPlugin(), importAnalysisPlugin()];
}当然,我们需要注册 transformMiddleware 中间件,在src/node/server/index.ts中增加代码如下:
app.use(transformMiddleware(serverContext));然后在playground项目下执行pnpm dev,在浏览器里面访问http://localhost:3000,你可以在网络面板中发现 main.tsx 的内容以及被编译为下面这样:

同时,页面内容也能被渲染出来了:
OK,目前为止我们就基本上完成 JS/TS/JSX/TSX 文件的编译。
CSS 编译插件
首先,我们可以看看项目中 CSS 代码是如何被引入的:
// playground/src/main.tsx
import "./index.css";为了让 CSS 能够在 no-bundle 服务中正常加载,我们需要将其包装成浏览器可以识别的模块格式,也就是 JS 模块,其中模块加载和转换的逻辑我们可以通过插件来实现。当然,首先我们需要在 transform 中间件中允许对 CSS 的请求进行处理,代码如下:
// src/node/server/middlewares/transform.ts
// 需要增加的导入语句
+ import { isCSSRequest } from '../../utils';
export function transformMiddleware(
serverContext: ServerContext
): NextHandleFunction {
return async (req, res, next) => {
if (req.method !== "GET" || !req.url) {
return next();
}
const url = req.url;
debug("transformMiddleware: %s", url);
// transform JS request
- if (isJSRequest(url)) {
+ if (isJSRequest(url) || isCSSRequest(url)) {
// 后续代码省略
}
next();
};
}补充对应的工具函数:
// src/node/utils.ts
export const isCSSRequest = (id: string): boolean =>
cleanUrl(id).endsWith(".css");现在来开发 CSS 的编译插件,新建src/node/plugins/css.ts文件,内容如下:
import { readFile } from "fs-extra";
import { Plugin } from "../plugin";
export function cssPlugin(): Plugin {
return {
name: "m-vite:css",
load(id) {
// 加载
if (id.endsWith(".css")) {
return readFile(id, "utf-8");
}
},
// 转换逻辑
async transform(code, id) {
if (id.endsWith(".css")) {
// 包装成 JS 模块
const jsContent = `
const css = "${code.replace(/\n/g, "")}";
const style = document.createElement("style");
style.setAttribute("type", "text/css");
style.innerHTML = css;
document.head.appendChild(style);
export default css;
`.trim();
return {
code: jsContent,
};
}
return null;
},
};
}这个插件的逻辑比较简单,主要是将封装一层 JS 样板代码,将 CSS 包装成一个 ES 模块,当浏览器执行这个模块的时候,会通过一个 style 标签将 CSS 代码作用到页面中,从而使样式代码生效。
接着我们来注册这个 CSS 插件:
// src/node/plugins/index.ts
+ import { cssPlugin } from "./css";
export function resolvePlugins(): Plugin[] {
return [
// 省略前面的插件
+ cssPlugin(),
];
}现在,你可以通过pnpm dev来启动 playground 项目,不过在启动之前,需要保证 TSX 文件已经引入了对应的 CSS 文件:
// playground/src/main.tsx
import "./index.css";
// playground/src/App.tsx
import "./App.css";在启动项目后,打开浏览器进行访问,可以看到样式已经正常生效:
静态资源加载
现在继续完成静态资源的加载。以 playground 项目为例,我们来支持 svg 文件的加载。首先,我们看看 svg 文件是如何被引入并使用的:
// playground/src/App.tsx
import logo from "./logo.svg";
function App() {
return (
<img className="App-logo" src={logo} alt="" />
)
}站在 no-bundle 服务的角度,从如上的代码我们可以分析出静态资源的两种请求:
- import 请求。如
import logo from "./logo.svg"。 - 资源内容请求。如 img 标签将资源 url 填入 src,那么浏览器会请求具体的资源内容。
因此,接下来为了实现静态资源的加载,我们需要做两手准备: 对静态资源的 import 请求返回资源的 url;对于具体内容的请求,读取静态资源的文件内容,并响应给浏览器。
首先处理 import 请求,我们可以在 TSX 的 import 分析插件中,给静态资源相关的 import 语句做一个标记:
// src/node/plugins/importAnalysis.ts
async transform(code, id) {
// 省略前面的代码
for (const importInfo of imports) {
const { s: modStart, e: modEnd, n: modSource } = importInfo;
if (!modSource) continue;
+ // 静态资源
+ if (modSource.endsWith(".svg")) {
+ // 加上 ?import 后缀
+ const resolvedUrl = path.join(path.dirname(id), modSource);
+ ms.overwrite(modStart, modEnd, `${resolvedUrl}?import`);
+ continue;
}
}
}编译后的 App.tsx 内容如下:
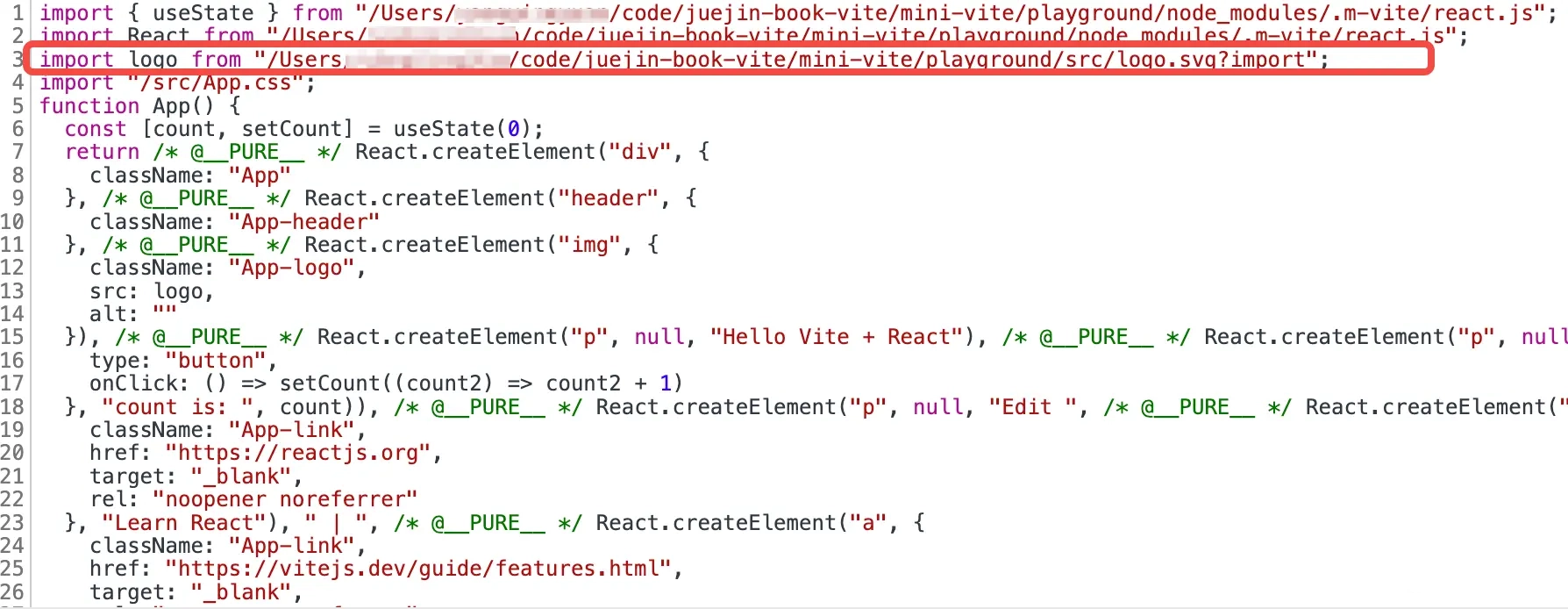
接着浏览器会发出带有?import后缀的请求,我们在 transform 中间件进行处理:
// src/node/server/middlewares/transform.ts
// 需要增加的导入语句
+ import { isImportRequest } from '../../utils';
export function transformMiddleware(
serverContext: ServerContext
): NextHandleFunction {
return async (req, res, next) => {
if (req.method !== "GET" || !req.url) {
return next();
}
const url = req.url;
debug("transformMiddleware: %s", url);
// transform JS request
- if (isJSRequest(url) || isCSSRequest(url)) {
+ if (isJSRequest(url) || isCSSRequest(url) || isImportRequest(url)) {
// 后续代码省略
}
next();
};
}补充对应的工具函数:
// src/node/utils.ts
export function isImportRequest(url: string): boolean {
return url.endsWith("?import");
}此时,我们就可以开发静态资源插件了。新建src/node/plugins/assets.ts,内容如下:
import { pathExists, readFile } from "fs-extra";
import { Plugin } from "../plugin";
import { ServerContext } from "../server";
import { cleanUrl, getShortName, normalizePath, removeImportQuery } from "../utils";
export function assetPlugin(): Plugin {
let serverContext: ServerContext;
return {
name: "m-vite:asset",
configureServer(s) {
serverContext = s;
},
async load(id) {
const cleanedId = removeImportQuery(cleanUrl(id));
const resolvedId = `/${getShortName(normalizePath(id), serverContext.root)}`;
// 这里仅处理 svg
if (cleanedId.endsWith(".svg")) {
return {
code: `export default "${resolvedId}"`,
};
}
},
};
}接着来注册这个插件:
// src/node/plugins/index.ts
+ import { assetPlugin } from "./assets";
export function resolvePlugins(): Plugin[] {
return [
// 省略前面的插件
+ assetPlugin(),
];
}目前我们处理完了静态资源的 import 请求,接着我们还需要处理非 import 请求,返回资源的具体内容。我们可以通过一个中间件来进行处理:
// src/node/server/middlewares/static.ts
import { NextHandleFunction } from "connect";
import { isImportRequest } from "../../utils";
// 一个用于加载静态资源的中间件
import sirv from "sirv";
export function staticMiddleware(root: string): NextHandleFunction {
const serveFromRoot = sirv(root, { dev: true });
return async (req, res, next) => {
if (!req.url) {
return;
}
// 不处理 import 请求
if (isImportRequest(req.url)) {
return;
}
serveFromRoot(req, res, next);
};
}然后在服务中注册这个中间件:
// src/node/server/index.ts
// 需要添加的引入语句
+ import { staticMiddleware } from "./middlewares/static";
export async function startDevServer() {
// 前面的代码省略
+ app.use(staticMiddleware(serverContext.root));
app.listen(3000, async () => {
// 省略实现
});
}现在,你可以通过pnpm dev启动 playground 项目,在浏览器中访问,可以发现 svg 图片已经能够成功显示了。
其实不光是 svg 文件,几乎所有格式的静态资源都可以按照如上的思路进行处理:
- 通过加入
?import后缀标识 import 请求,返回将静态资源封装成一个 JS 模块,即export default xxx的形式,导出资源的真实地址。 - 对非 import 请求,响应静态资源的具体内容,通过
Content-Type响应头告诉浏览器资源的类型(这部分工作 sirv 中间件已经帮我们做了)。
模块依赖图开发
模块依赖图在 no-bundle 构建服务中是一个不可或缺的数据结构,一方面可以存储各个模块的信息,用于记录编译缓存,另一方面也可以记录各个模块间的依赖关系,用于实现 HMR。
接下来我们来实现模块依赖图,即ModuleGraph类,新建src/node/ModuleGraph.ts,内容如下:
import { PartialResolvedId, TransformResult } from "rollup";
import { cleanUrl } from "./utils";
export class ModuleNode {
// 资源访问 url
url: string;
// 资源绝对路径
id: string | null = null;
importers = new Set<ModuleNode>();
importedModules = new Set<ModuleNode>();
transformResult: TransformResult | null = null;
lastHMRTimestamp = 0;
constructor(url: string) {
this.url = url;
}
}
export class ModuleGraph {
// 资源 url 到 ModuleNode 的映射表
urlToModuleMap = new Map<string, ModuleNode>();
// 资源绝对路径到 ModuleNode 的映射表
idToModuleMap = new Map<string, ModuleNode>();
constructor(
private resolveId: (url: string) => Promise<PartialResolvedId | null>
) {}
getModuleById(id: string): ModuleNode | undefined {
return this.idToModuleMap.get(id);
}
async getModuleByUrl(rawUrl: string): Promise<ModuleNode | undefined> {
const { url } = await this._resolve(rawUrl);
return this.urlToModuleMap.get(url);
}
async ensureEntryFromUrl(rawUrl: string): Promise<ModuleNode> {
const { url, resolvedId } = await this._resolve(rawUrl);
// 首先检查缓存
if (this.urlToModuleMap.has(url)) {
return this.urlToModuleMap.get(url) as ModuleNode;
}
// 若无缓存,更新 urlToModuleMap 和 idToModuleMap
const mod = new ModuleNode(url);
mod.id = resolvedId;
this.urlToModuleMap.set(url, mod);
this.idToModuleMap.set(resolvedId, mod);
return mod;
}
async updateModuleInfo(
mod: ModuleNode,
importedModules: Set<string | ModuleNode>
) {
const prevImports = mod.importedModules;
for (const curImports of importedModules) {
const dep =
typeof curImports === "string"
? await this.ensureEntryFromUrl(cleanUrl(curImports))
: curImports;
if (dep) {
mod.importedModules.add(dep);
dep.importers.add(mod);
}
}
// 清除已经不再被引用的依赖
for (const prevImport of prevImports) {
if (!importedModules.has(prevImport.url)) {
prevImport.importers.delete(mod);
}
}
}
// HMR 触发时会执行这个方法
invalidateModule(file: string) {
const mod = this.idToModuleMap.get(file);
if (mod) {
// 更新时间戳
mod.lastHMRTimestamp = Date.now();
mod.transformResult = null;
mod.importers.forEach((importer) => {
this.invalidateModule(importer.id!);
});
}
}
private async _resolve(
url: string
): Promise<{ url: string; resolvedId: string }> {
const resolved = await this.resolveId(url);
const resolvedId = resolved?.id || url;
return { url, resolvedId };
}
}接着我们看看如何将这个 ModuleGraph 接入到目前的架构中。首先在服务启动前,我们需要初始化 ModuleGraph 实例:
// src/node/server/index.ts
+ import { ModuleGraph } from "../ModuleGraph";
export interface ServerContext {
root: string;
pluginContainer: PluginContainer;
app: connect.Server;
plugins: Plugin[];
+ moduleGraph: ModuleGraph;
}
export async function startDevServer() {
+ const moduleGraph = new ModuleGraph((url) => pluginContainer.resolveId(url));
const pluginContainer = createPluginContainer(plugins);
const serverContext: ServerContext = {
root: process.cwd(),
app,
pluginContainer,
plugins,
+ moduleGraph
};
}然后在加载完模块后,也就是调用插件容器的 load 方法后,我们需要通过 ensureEntryFromUrl 方法注册模块:
// src/node/server/middlewares/transform.ts
let code = await pluginContainer.load(resolvedResult.id);
if (typeof code === "object" && code !== null) {
code = code.code;
}
+ const { moduleGraph } = serverContext;
+ mod = await moduleGraph.ensureEntryFromUrl(url);当我们对 JS 模块分析完 import 语句之后,需要更新模块之间的依赖关系:
// src/node/plugins/importAnalysis.ts
export function importAnalysis() {
return {
transform(code: string, id: string) {
// 省略前面的代码
+ const { moduleGraph } = serverContext;
+ const curMod = moduleGraph.getModuleById(id)!;
+ const importedModules = new Set<string>();
for(const importInfo of imports) {
// 省略部分代码
if (BARE_IMPORT_RE.test(modSource)) {
// 省略部分代码
+ importedModules.add(bundlePath);
} else if (modSource.startsWith(".") || modSource.startsWith("/")) {
const resolved = await resolve(modSource, id);
if (resolved) {
ms.overwrite(modStart, modEnd, resolved);
+ importedModules.add(resolved);
}
}
}
+ moduleGraph.updateModuleInfo(curMod, importedModules);
// 省略后续 return 代码
}
}
}现在,一个完整的模块依赖图就能随着 JS 请求的到来而不断建立起来了。另外,基于现在的模块依赖图,我们也可以记录模块编译后的产物,并进行缓存。让我们回到 transform 中间件中:
export async function transformRequest(
url: string,
serverContext: ServerContext
) {
const { moduleGraph, pluginContainer } = serverContext;
url = cleanUrl(url);
+ let mod = await moduleGraph.getModuleByUrl(url);
+ if (mod && mod.transformResult) {
+ return mod.transformResult;
+ }
const resolvedResult = await pluginContainer.resolveId(url);
let transformResult;
if (resolvedResult?.id) {
let code = await pluginContainer.load(resolvedResult.id);
if (typeof code === "object" && code !== null) {
code = code.code;
}
mod = await moduleGraph.ensureEntryFromUrl(url);
if (code) {
transformResult = await pluginContainer.transform(
code as string,
resolvedResult?.id
);
}
}
+ if (mod) {
+ mod.transformResult = transformResult;
+ }
return transformResult;
}在搭建好模块依赖图之后,我们把目光集中到最重要的部分——HMR 上面。
HMR 服务端
HMR 在服务端需要完成如下的工作:
- 创建文件监听器,以监听文件的变动
- 创建 WebSocket 服务端,负责和客户端进行通信
- 文件变动时,从 ModuleGraph 中定位到需要更新的模块,将更新信息发送给客户端
首先,我们来创建文件监听器:
// src/node/server/index.ts
import chokidar, { FSWatcher } from "chokidar";
export async function startDevServer() {
const watcher = chokidar.watch(root, {
ignored: ["**/node_modules/**", "**/.git/**"],
ignoreInitial: true,
});
}接着初始化 WebSocket 服务端,新建src/node/ws.ts,内容如下:
import connect from "connect";
import { red } from "picocolors";
import { WebSocketServer, WebSocket } from "ws";
import { HMR_PORT } from "./constants";
export function createWebSocketServer(server: connect.Server): {
send: (msg: string) => void;
close: () => void;
} {
let wss: WebSocketServer;
wss = new WebSocketServer({ port: HMR_PORT });
wss.on("connection", (socket) => {
socket.send(JSON.stringify({ type: "connected" }));
});
wss.on("error", (e: Error & { code: string }) => {
if (e.code !== "EADDRINUSE") {
console.error(red(`WebSocket server error:\n${e.stack || e.message}`));
}
});
return {
send(payload: Object) {
const stringified = JSON.stringify(payload);
wss.clients.forEach((client) => {
if (client.readyState === WebSocket.OPEN) {
client.send(stringified);
}
});
},
close() {
wss.close();
},
};
}同时定义 HMR_PORT 常量:
// src/node/constants.ts
export const HMR_PORT = 24678;接着我们将 WebSocket 服务端实例加入 no-bundle 服务中:
// src/node/server/index.ts
export interface ServerContext {
root: string;
pluginContainer: PluginContainer;
app: connect.Server;
plugins: Plugin[];
moduleGraph: ModuleGraph;
+ ws: { send: (data: any) => void; close: () => void };
+ watcher: FSWatcher;
}
export async function startDevServer() {
+ // WebSocket 对象
+ const ws = createWebSocketServer(app);
// // 开发服务器上下文
const serverContext: ServerContext = {
root: process.cwd(),
app,
pluginContainer,
plugins,
moduleGraph,
+ ws,
+ watcher
};
}下面我们来实现当文件变动时,服务端具体的处理逻辑,新建 src/node/hmr.ts:
import { ServerContext } from "./server/index";
import { blue, green } from "picocolors";
import { getShortName } from "./utils";
export function bindingHMREvents(serverContext: ServerContext) {
const { watcher, ws, root } = serverContext;
watcher.on("change", async (file) => {
console.log(`✨${blue("[hmr]")} ${green(file)} changed`);
const { moduleGraph } = serverContext;
// 清除模块依赖图中的缓存
await moduleGraph.invalidateModule(file);
// 向客户端发送更新信息
ws.send({
type: "update",
updates: [
{
type: "js-update",
timestamp: Date.now(),
path: "/" + getShortName(file, root),
acceptedPath: "/" + getShortName(file, root),
},
],
});
});
}补充一下缺失的工具函数:
// src/node/utils.ts
export function getShortName(file: string, root: string) {
return file.startsWith(root + "/") ? path.posix.relative(root, file) : file;
}接着我们在服务中添加如下代码:
// src/node/server/index.ts
+ import { bindingHMREvents } from "../hmr";
+ import { normalizePath } from "../utils";
// 开发服务器上下文
const serverContext: ServerContext = {
root: normalizePath(process.cwd()),
app,
pluginContainer,
plugins,
moduleGraph,
ws,
watcher,
};
+ bindingHMREvents(serverContext);HMR 客户端
HMR 客户端指的是我们向浏览器中注入的一段 JS 脚本,这段脚本中会做如下的事情:
- 创建 WebSocket 客户端,用于和服务端通信
- 在收到服务端的更新信息后,通过动态 import 拉取最新的模块内容,执行 accept 更新回调
- 暴露 HMR 的一些工具函数,比如 i
mport.meta.hot 对象的实现
首先我们来开发客户端的脚本内容,你可以新建src/client/client.ts文件,然后在 tsup.config.ts 中增加如下的配置:
import { defineConfig } from "tsup";
export default defineConfig({
entry: {
index: "src/node/cli.ts",
+ client: "src/client/client.ts",
},
});注: 改动 tsup 配置之后,为了使最新配置生效,你需要在 mini-vite 项目中执行 pnpm start 重新进行构建。
客户端脚本的具体实现如下:
// src/client/client.ts
console.log("[vite] connecting...");
// 1. 创建客户端 WebSocket 实例
// 其中的 __HMR_PORT__ 之后会被 no-bundle 服务编译成具体的端口号
const socket = new WebSocket(`ws://localhost:__HMR_PORT__`, "vite-hmr");
// 2. 接收服务端的更新信息
socket.addEventListener("message", async ({ data }) => {
handleMessage(JSON.parse(data)).catch(console.error);
});
// 3. 根据不同的更新类型进行更新
async function handleMessage(payload: any) {
switch (payload.type) {
case "connected":
console.log(`[vite] connected.`);
// 心跳检测
setInterval(() => socket.send("ping"), 1000);
break;
case "update":
// 进行具体的模块更新
payload.updates.forEach((update: Update) => {
if (update.type === "js-update") {
// 具体的更新逻辑,后续来开发
}
});
break;
}
}关于客户端具体的 JS 模块更新逻辑和工具函数的实现,你暂且不用过于关心。我们先把这段比较简单的 HMR 客户端代码注入到浏览器中,首先在新建 src/node/plugins/clientInject.ts,内容如下:
import { CLIENT_PUBLIC_PATH, HMR_PORT } from "../constants";
import { Plugin } from "../plugin";
import fs from "fs-extra";
import path from "path";
import { ServerContext } from "../server/index";
export function clientInjectPlugin(): Plugin {
let serverContext: ServerContext;
return {
name: "m-vite:client-inject",
configureServer(s) {
serverContext = s;
},
resolveId(id) {
if (id === CLIENT_PUBLIC_PATH) {
return { id };
}
return null;
},
async load(id) {
// 加载 HMR 客户端脚本
if (id === CLIENT_PUBLIC_PATH) {
const realPath = path.join(
serverContext.root,
"node_modules",
"mini-vite",
"dist",
"client.mjs"
);
const code = await fs.readFile(realPath, "utf-8");
return {
// 替换占位符
code: code.replace("__HMR_PORT__", JSON.stringify(HMR_PORT)),
};
}
},
transformIndexHtml(raw) {
// 插入客户端脚本
// 即在 head 标签后面加上 <script type="module" src="/@vite/client"></script>
// 注: 在 indexHtml 中间件里面会自动执行 transformIndexHtml 钩子
return raw.replace(
/(<head[^>]*>)/i,
`$1<script type="module" src="${CLIENT_PUBLIC_PATH}"></script>`
);
},
};
}同时添加相应的常量声明:
// src/node/constants.ts
export const CLIENT_PUBLIC_PATH = "/@vite/client";接着我们来注册这个插件:
// src/node/plugins/index.ts
+ import { clientInjectPlugin } from './clientInject';
export function resolvePlugins(): Plugin[] {
return [
+ clientInjectPlugin()
// 省略其它插件
]
}需要注意的是,clientInject插件最好放到最前面的位置,以免后续插件的 load 钩子干扰客户端脚本的加载。
接下来你可以在 playground 项目下执行pnpm dev,然后查看页面,可以发现控制台出现了如下的 log 信息:
[vite] connecting...
[vite] connected.值得一提的是,之所以我们可以在代码中编写类似i之类的方法,是因为 Vite 帮我们在模块最顶层注入了i对象,而这个对象由createHotContext来实现,具体的注入代码如下所示:
import { createHotContext as __vite__createHotContext } from "/@vite/client";
import.meta.hot = __vite__createHotContext("/src/App.tsx");下面我们在 import 分析插件中做一些改动,实现插入这段代码的功能:
import { init, parse } from "es-module-lexer";
import {
BARE_IMPORT_RE,
CLIENT_PUBLIC_PATH,
PRE_BUNDLE_DIR,
} from "../constants";
import {
cleanUrl,
+ getShortName,
isJSRequest,
} from "../utils";
import MagicString from "magic-string";
import path from "path";
import { Plugin } from "../plugin";
import { ServerContext } from "../server/index";
export function importAnalysisPlugin(): Plugin {
let serverContext: ServerContext;
return {
name: "m-vite:import-analysis",
configureServer(s) {
serverContext = s;
},
async transform(code: string, id: string) {
+ if (!isJSRequest(id) || isInternalRequest(id)) {
return null;
}
await init;
const importedModules = new Set<string>();
const [imports] = parse(code);
const ms = new MagicString(code);
+ const resolve = async (id: string, importer?: string) => {
+ const resolved = await this.resolve(
+ id,
+ normalizePath(importer)
+ );
+ if (!resolved) {
+ return;
+ }
+ const cleanedId = cleanUrl(resolved.id);
+ const mod = moduleGraph.getModuleById(cleanedId);
+ let resolvedId = `/${getShortName(resolved.id, serverContext.root)}`;
+ if (mod && mod.lastHMRTimestamp > 0) {
+ resolvedId += "?t=" + mod.lastHMRTimestamp;
+ }
+ return resolvedId;
+ };
const { moduleGraph } = serverContext;
const curMod = moduleGraph.getModuleById(id)!;
for (const importInfo of imports) {
const { s: modStart, e: modEnd, n: modSource } = importInfo;
if (!modSource || isInternalRequest(modSource)) continue;
// 静态资源
if (modSource.endsWith(".svg")) {
// 加上 ?import 后缀
const resolvedUrl = await resolve(modSource, id);
ms.overwrite(modStart, modEnd, `${resolvedUrl}?import`);
continue;
}
// 第三方库: 路径重写到预构建产物的路径
if (BARE_IMPORT_RE.test(modSource)) {
const bundlePath = normalizePath(
path.join('/', PRE_BUNDLE_DIR, `${modSource}.js`)
ms.overwrite(modStart, modEnd, bundlePath);
importedModules.add(bundlePath);
} else if (modSource.startsWith(".") || modSource.startsWith("/")) {
+ const resolved = await resolve(modSource, id);
if (resolved) {
ms.overwrite(modStart, modEnd, resolved);
importedModules.add(resolved);
}
}
}
// 只对业务源码注入
+ if (!id.includes("node_modules")) {
+ // 注入 HMR 相关的工具函数
+ ms.prepend(
+ `import { createHotContext as __vite__createHotContext } from "${CLIENT_PUBLIC_PATH}";` +
+ `import.meta.hot = __vite__createHotContext(${JSON.stringify(
+ cleanUrl(curMod.url)
+ )});`
+ );
+ }
moduleGraph.updateModuleInfo(curMod, importedModules);
return {
code: ms.toString(),
map: ms.generateMap(),
};
},
};
}接着启动 playground,打开页面后你可以发现 icreateHotContext 这个工具方法:
interface HotModule {
id: string;
callbacks: HotCallback[];
}
interface HotCallback {
deps: string[];
fn: (modules: object[]) => void;
}
// HMR 模块表
const hotModulesMap = new Map<string, HotModule>();
// 不在生效的模块表
const pruneMap = new Map<string, (data: any) => void | Promise<void>>();
export const createHotContext = (ownerPath: string) => {
const mod = hotModulesMap.get(ownerPath);
if (mod) {
mod.callbacks = [];
}
function acceptDeps(deps: string[], callback: any) {
const mod: HotModule = hotModulesMap.get(ownerPath) || {
id: ownerPath,
callbacks: [],
};
// callbacks 属性存放 accept 的依赖、依赖改动后对应的回调逻辑
mod.callbacks.push({
deps,
fn: callback,
});
hotModulesMap.set(ownerPath, mod);
}
return {
accept(deps: any, callback?: any) {
// 这里仅考虑接受自身模块更新的情况
// import.meta.hot.accept()
if (typeof deps === "function" || !deps) {
acceptDeps([ownerPath], ([mod]) => deps && deps(mod));
}
},
// 模块不再生效的回调
// import.meta.hot.prune(() => {})
prune(cb: (data: any) => void) {
pruneMap.set(ownerPath, cb);
},
};
};在 accept 方法中,我们会用hotModulesMap这张表记录该模块所 accept 的模块,以及 accept 的模块更新之后回调逻辑。
接着,我们来开发客户端热更新的具体逻辑,也就是服务端传递更新内容之后客户端如何来派发更新。实现代码如下:
async function fetchUpdate({ path, timestamp }: Update) {
const mod = hotModulesMap.get(path);
if (!mod) return;
const moduleMap = new Map();
const modulesToUpdate = new Set<string>();
modulesToUpdate.add(path);
await Promise.all(
Array.from(modulesToUpdate).map(async (dep) => {
const [path, query] = dep.split(`?`);
try {
// 通过动态 import 拉取最新模块
const newMod = await import(
path + `?t=${timestamp}${query ? `&${query}` : ""}`
);
moduleMap.set(dep, newMod);
} catch (e) {}
})
);
return () => {
// 拉取最新模块后执行更新回调
for (const { deps, fn } of mod.callbacks) {
fn(deps.map((dep: any) => moduleMap.get(dep)));
}
console.log(`[vite] hot updated: ${path}`);
};
}现在,我们可以来初步测试一下 HMR 的功能,你可以暂时将 main.tsx 的内容换成下面这样:
import React from "react";
import ReactDOM from "react-dom";
import "./index.css";
const App = () => <div>hello 123123</div>;
ReactDOM.render(<App />, document.getElementById("root"));
// @ts-ignore
import.meta.hot.accept(() => {
ReactDOM.render(<App />, document.getElementById("root"));
});启动 playground,然后打开浏览器,可以看到 hello 123123 文本,回到编辑器中,修改文本内容,然后保存,你可以发现页面内容也跟着发生了变化,并且网络面板发出了拉取最新模块的请求,说明 HMR 已经成功生效。
同时,当你再次刷新页面,看到的仍然是最新的页面内容。这一点非常重要,之所以能达到这样的效果,是因为我们在文件改动后会调用 ModuleGraph 的 invalidateModule 方法,这个方法会清除热更模块以及所有上层引用方模块的编译缓存:
// 方法实现
invalidateModule(file: string) {
const mod = this.idToModuleMap.get(file);
if (mod) {
mod.lastHMRTimestamp = Date.now();
mod.transformResult = null;
mod.importers.forEach((importer) => {
this.invalidateModule(importer.id!);
});
}
}这样每次经过 HMR 后,再次刷新页面,渲染出来的一定是最新的模块内容。
当然,我们也可以对 CSS 实现热更新功能,在客户端脚本中添加如下的工具函数:
const sheetsMap = new Map();
export function updateStyle(id: string, content: string) {
let style = sheetsMap.get(id);
if (!style) {
// 添加 style 标签
style = document.createElement("style");
style.setAttribute("type", "text/css");
style.innerHTML = content;
document.head.appendChild(style);
} else {
// 更新 style 标签内容
style.innerHTML = content;
}
sheetsMap.set(id, style);
}
export function removeStyle(id: string): void {
const style = sheetsMap.get(id);
if (style) {
document.head.removeChild(style);
}
sheetsMap.delete(id);
}紧接着我们调整一下 CSS 编译插件的代码:
import { readFile } from "fs-extra";
import { CLIENT_PUBLIC_PATH } from "../constants";
import { Plugin } from "../plugin";
import { ServerContext } from "../server";
import { getShortName } from "../utils";
export function cssPlugin(): Plugin {
let serverContext: ServerContext;
return {
name: "m-vite:css",
configureServer(s) {
serverContext = s;
},
load(id) {
if (id.endsWith(".css")) {
return readFile(id, "utf-8");
}
},
// 主要变动在 transform 钩子中
async transform(code, id) {
if (id.endsWith(".css")) {
// 包装成 JS 模块
const jsContent = `
import { createHotContext as __vite__createHotContext } from "${CLIENT_PUBLIC_PATH}";
import.meta.hot = __vite__createHotContext("/ ${getShortName(id, serverContext.root)}");
import { updateStyle, removeStyle } from "${CLIENT_PUBLIC_PATH}"
const id = '${id}';
const css = '${code.replace(/\n/g, "")}';
updateStyle(id, css);
import.meta.hot.accept();
export default css;
import.meta.hot.prune(() => removeStyle(id)); `.trim();
return {
code: jsContent,
};
}
return null;
},
};
}最后,你可以重启 playground 项目,本地尝试修改 CSS 代码,可以看到浏览器上的文本样式也跟着改变了。
手写 Bundler
前面我们一起手写了一个迷你版的 no-bundle 开发服务,也就是 Vite 开发阶段的 Dev Server,而在生产环境下面,处于页面性能的考虑,Vite 还是选择进行打包(bundle),并且在底层使用 Rollup 来完成打包的过程。
搭建开发测试环境
首先通过pnpm init -y新建项目,安装测试工具vitest:
pnpm i vitest -D新建 src/__test__ 目录,之后所有的测试代码都会放到这个目录中。我们不妨先尝试编写一个测试文件:
// src/__test__/example.test.ts
import { describe, test, expect } from "vitest";
describe("example test", () => {
test("should return correct result", () => {
expect(2 + 2).toBe(4);
});
});然后在package.json中增加如下的 scripts:
"test": "vitest"接着在命令行执行 pnpm test,如果你可以看到如下的终端界面,说明测试环境已经搭建成功:
词法分析器开发
接下来,我们正式进入 AST 解析器的开发,主要分为两个部分来进行: 词法分析器和语法分析器。
首先是词法分析器,也叫分词器(Tokenizer),它的作用是将代码划分为一个个词法单元,便于进行后续的语法分析。比如下面的这段代码:
let foo = function() {}在经过分词之后,代码会被切分为如下的 token 数组:
['let', 'foo', '=', 'function', '(', ')', '{', '}']从中你可以看到,原本一行普通的代码字符串被拆分成了拥有语法属性的 token 列表,不同的 token 之间也存在千丝万缕的联系,而后面所要介绍的语法分析器,就是来梳理各个 token 之间的联系,整理出 AST 数据结构。
当下我们所要实现的词法分析器,本质上是对代码字符串进行逐个字符的扫描,然后根据一定的语法规则进行分组。其中,涉及到几个关键的步骤:
- 确定语法规则,包括语言内置的关键词、单字符、分隔符等
- 逐个代码字符扫描,根据语法规则进行 token 分组
接下来我们以一个简单的语法为例,来初步实现如上的关键流程。需要解析的示例代码如下:
let foo = function() {}1. 确定语法规则
新建src/Tokenizer.ts,首先声明一些必要的类型:
export enum TokenType {
// let
Let = "Let",
// =
Assign = "Assign",
// function
Function = "Function",
// 变量名
Identifier = "Identifier",
// (
LeftParen = "LeftParen",
// )
RightParen = "RightParen",
// {
LeftCurly = "LeftCurly",
// }
RightCurly = "RightCurly",
}
export type Token = {
type: TokenType;
value?: string;
start: number;
end: number;
raw?: string;
};然后定义 Token 的生成器对象:
const TOKENS_GENERATOR: Record<string, (...args: any[]) => Token> = {
let(start: number) {
return { type: TokenType.Let, value: "let", start, end: start + 3 };
},
assign(start: number) {
return { type: TokenType.Assign, value: "=", start, end: start + 1 };
},
function(start: number) {
return {
type: TokenType.Function,
value: "function",
start,
end: start + 8,
};
},
leftParen(start: number) {
return { type: TokenType.LeftParen, value: "(", start, end: start + 1 };
},
rightParen(start: number) {
return { type: TokenType.RightParen, value: ")", start, end: start + 1 };
},
leftCurly(start: number) {
return { type: TokenType.LeftCurly, value: "{", start, end: start + 1 };
},
rightCurly(start: number) {
return { type: TokenType.RightCurly, value: "}", start, end: start + 1 };
},
identifier(start: number, value: string) {
return {
type: TokenType.Identifier,
value,
start,
end: start + value.length,
};
},
}
type SingleCharTokens = "(" | ")" | "{" | "}" | "=";
// 单字符到 Token 生成器的映射
const KNOWN_SINGLE_CHAR_TOKENS = new Map<
SingleCharTokens,
typeof TOKENS_GENERATOR[keyof typeof TOKENS_GENERATOR]
>([
["(", TOKENS_GENERATOR.leftParen],
[")", TOKENS_GENERATOR.rightParen],
["{", TOKENS_GENERATOR.leftCurly],
["}", TOKENS_GENERATOR.rightCurly],
["=", TOKENS_GENERATOR.assign],
]);2. 代码字符扫描、分组
现在我们开始实现 Tokenizer 对象:
export class Tokenizer {
private _tokens: Token[] = [];
private _currentIndex: number = 0;
private _source: string;
constructor(input: string) {
this._source = input;
}
tokenize(): Token[] {
while (this._currentIndex < this._source.length) {
let currentChar = this._source[this._currentIndex];
const startIndex = this._currentIndex;
// 根据语法规则进行 token 分组
}
return this._tokens;
}
}在扫描字符的过程,我们需要对不同的字符各自进行不同的处理,具体的策略如下:
- 当前字符为分隔符,如空格,直接跳过,不处理;
- 当前字符为字母,需要继续扫描,获取完整的单词:
- 如果单词为语法关键字,则新建相应关键字的 Token
- 否则视为普通的变量名
- 当前字符为单字符,如{、}、(、),则新建单字符对应的 Token
接着我们在代码中实现:
// while 循环内部
let currentChar = this._source[this._currentIndex];
const startIndex = this._currentIndex;
const isAlpha = (char: string): boolean => {
return (char >= "a" && char <= "z") || (char >= "A" && char <= "Z");
}
// 1. 处理空格
if (currentChar === ' ') {
this._currentIndex++;
continue;
}
// 2. 处理字母
else if (isAlpha(currentChar)) {
let identifier = '';
while(isAlpha(currentChar)) {
identifier += currentChar;
this._currentIndex ++;
currentChar = this._source[this._currentIndex];
}
let token: Token;
if (identifier in TOKENS_GENERATOR) {
// 如果是关键字
token =
TOKENS_GENERATOR[identifier as keyof typeof TOKENS_GENERATOR](
startIndex
);
} else {
// 如果是普通标识符
token = TOKENS_GENERATOR["identifier"](startIndex, identifier);
}
this._tokens.push(token);
continue;
}
// 3. 处理单字符
else if(KNOWN_SINGLE_CHAR_TOKENS.has(currentChar as SingleCharTokens)) {
const token = KNOWN_SINGLE_CHAR_TOKENS.get(
currentChar as SingleCharTokens
)!(startIndex);
this._tokens.push(token);
this._currentIndex++;
continue;
}接下来我们来增加测试用例,新建src/__test__/tokenizer.test.ts,内容如下:
describe("testTokenizerFunction", () => {
test("test example", () => {
const result = [
{ type: "Let", value: "let", start: 0, end: 3 },
{ type: "Identifier", value: "a", start: 4, end: 5 },
{ type: "Assign", value: "=", start: 6, end: 7 },
{ type: "Function", value: "function", start: 8, end: 16 },
{ type: "LeftParen", value: "(", start: 16, end: 17 },
{ type: "RightParen", value: ")", start: 17, end: 18 },
{ type: "LeftCurly", value: "{", start: 19, end: 20 },
{ type: "RightCurly", value: "}", start: 20, end: 21 },
];
const tokenizer = new Tokenizer("let a = function() {}");
expect(tokenizer.tokenize()).toEqual(result);
});
});然后在终端执行pnpm test,可以发现如下的测试结果:
说明此时一个简易版本的分词器已经被我们开发出来了,不过目前的分词器还比较简陋,仅仅支持有限的语法,不过在明确了核心的开发步骤之后,后面继续完善的过程就比较简单了。
语法分析器开发
在解析出词法 token 之后,我们就可以进入语法分析阶段了。在这个阶段,我们会依次遍历 token,对代码进行语法结构层面的分析,最后的目标是生成 AST 数据结构。至于代码的 AST 结构到底是什么样子,可以去 AST Explorer 网站进行在线预览:
接下来,我们要做的就是将 token 数组转换为上图所示的 AST 数据。
首先新建src/Parser.ts,添加如下的类型声明代码及 Parser 类的初始化代码:
export enum NodeType {
Program = "Program",
VariableDeclaration = "VariableDeclaration",
VariableDeclarator = "VariableDeclarator",
Identifier = "Identifier",
FunctionExpression = "FunctionExpression",
BlockStatement = "BlockStatement",
}
export interface Node {
type: string;
start: number;
end: number;
}
export interface Identifier extends Node {
type: NodeType.Identifier;
name: string;
}
interface Expression extends Node {}
interface Statement extends Node {}
export interface Program extends Node {
type: NodeType.Program;
body: Statement[];
}
export interface VariableDeclarator extends Node {
type: NodeType.VariableDeclarator;
id: Identifier;
init: Expression;
}
export interface VariableDeclaration extends Node {
type: NodeType.VariableDeclaration;
kind: "var" | "let" | "const";
declarations: VariableDeclarator[];
}
export interface FunctionExpression extends Node {
type: NodeType.FunctionExpression;
id: Identifier | null;
params: Expression[] | Identifier[];
body: BlockStatement;
}
export interface BlockStatement extends Node {
type: NodeType.BlockStatement;
body: Statement[];
}
export type VariableKind = "let";
export class Parser {
private _tokens: Token[] = [];
private _currentIndex = 0;
constructor(token: Token[]) {
this._tokens = [...token];
}
parse(): Program {
const program = this._parseProgram();
return program;
}
private _parseProgram(): Program {
const program: Program = {
type: NodeType.Program,
body: [],
start: 0,
end: Infinity,
};
// 解析 token 数组
return program;
}
}从中你可以看出,解析 AST 的核心逻辑就集中在 _parseProgram 方法中,接下来让我们一步步完善一个方法:
export class Parser {
private _parseProgram {
// 省略已有代码
while (!this._isEnd()) {
const node = this._parseStatement();
program.body.push(node);
if (this._isEnd()) {
program.end = node.end;
}
}
return program;
}
// token 是否已经扫描完
private _isEnd(): boolean {
return this._currentIndex >= this._tokens.length;
}
// 工具方法,表示消费当前 Token,扫描位置移动到下一个 token
private _goNext(type: TokenType | TokenType[]): Token {
const currentToken = this._tokens[this._currentIndex];
// 断言当前 Token 的类型,如果不能匹配,则抛出错误
if (Array.isArray(type)) {
if (!type.includes(currentToken.type)) {
throw new Error(
`Expect ${type.join(",")}, but got ${currentToken.type}`
);
}
} else {
if (currentToken.type !== type) {
throw new Error(`Expect ${type}, but got ${currentToken.type}`);
}
}
this._currentIndex++;
return currentToken;
}
private _checkCurrentTokenType(type: TokenType | TokenType[]): boolean {
if (this._isEnd()) {
return false;
}
const currentToken = this._tokens[this._currentIndex];
if (Array.isArray(type)) {
return type.includes(currentToken.type);
} else {
return currentToken.type === type;
}
}
private _getCurrentToken(): Token {
return this._tokens[this._currentIndex];
}
private _getPreviousToken(): Token {
return this._tokens[this._currentIndex - 1];
}
}一个程序(Program)实际上由各个语句(Statement)来构成,因此在_parseProgram逻辑中,我们主要做的就是扫描一个个语句,然后放到 Program 对象的 body 中。那么,接下来,我们将关注点放到语句的扫描逻辑上面。
从之前的示例代码:
let a = function() {}我们可以知道这是一个变量声明语句,那么现在我们就在 _parseStatement 中实现这类语句的解析:
export enum NodeType {
Program = "Program",
VariableDeclarator = "VariableDeclarator",
}
export class Parser {
private _parseStatement(): Statement {
// TokenType 来自 Tokenizer 的实现中
if (this._checkCurrentTokenType(TokenType.Let)) {
return this._parseVariableDeclaration();
}
throw new Error("Unexpected token");
}
private _parseVariableDeclaration(): VariableDeclaration {
// 获取语句开始位置
const { start } = this._getCurrentToken();
// 拿到 let
const kind = this._getCurrentToken().value;
this._goNext(TokenType.Let);
// 解析变量名 foo
const id = this._parseIdentifier();
// 解析 =
this._goNext(TokenType.Assign);
// 解析函数表达式
const init = this._parseFunctionExpression();
const declarator: VariableDeclarator = {
type: NodeType.VariableDeclarator,
id,
init,
start: id.start,
end: init ? init.end : id.end,
};
// 构造 Declaration 节点
const node: VariableDeclaration = {
type: NodeType.VariableDeclaration,
kind: kind as VariableKind,
declarations: [declarator],
start,
end: this._getPreviousToken().end,
};
return node;
}
}接下来主要的代码解析逻辑可以梳理如下:
- 发现
let关键词对应的 token,进入_parseVariableDeclaration - 解析变量名,如示例代码中的
foo - 解析函数表达式,如示例代码中的
function() {}
其中,解析变量名的过程我们通过 _parseIdentifier 方法实现,解析函数表达式的过程由 _parseFunctionExpression 来实现,代码如下:
// 1. 解析变量名
private _parseIdentifier(): Identifier {
const token = this._getCurrentToken();
const identifier: Identifier = {
type: NodeType.Identifier,
name: token.value!,
start: token.start,
end: token.end,
};
this._goNext(TokenType.Identifier);
return identifier;
}
// 2. 解析函数表达式
private _parseFunctionExpression(): FunctionExpression {
const { start } = this._getCurrentToken();
this._goNext(TokenType.Function);
let id = null;
if (this._checkCurrentTokenType(TokenType.Identifier)) {
id = this._parseIdentifier();
}
const node: FunctionExpression = {
type: NodeType.FunctionExpression,
id,
params: [],
body: {
type: NodeType.BlockStatement,
body: [],
start: start,
end: Infinity,
},
start,
end: 0,
};
return node;
}
// 用于解析函数参数
private _parseParams(): Identifier[] | Expression[] {
// 消费 "("
this._goNext(TokenType.LeftParen);
const params = [];
// 逐个解析括号中的参数
while (!this._checkCurrentTokenType(TokenType.RightParen)) {
let param = this._parseIdentifier();
params.push(param);
}
// 消费 ")"
this._goNext(TokenType.RightParen);
return params;
}
// 用于解析函数体
private _parseBlockStatement(): BlockStatement {
const { start } = this._getCurrentToken();
const blockStatement: BlockStatement = {
type: NodeType.BlockStatement,
body: [],
start,
end: Infinity,
};
// 消费 "{"
this._goNext(TokenType.LeftCurly);
while (!this._checkCurrentTokenType(TokenType.RightCurly)) {
// 递归调用 _parseStatement 解析函数体中的语句(Statement)
const node = this._parseStatement();
blockStatement.body.push(node);
}
blockStatement.end = this._getCurrentToken().end;
// 消费 "}"
this._goNext(TokenType.RightCurly);
return blockStatement;
}一个简易的 Parser 现在就已经搭建出来了,你可以用如下的测试用例看看程序运行的效果,代码如下:
// src/__test__/parser.test.ts
describe("testParserFunction", () => {
test("test example code", () => {
const result = {
type: "Program",
body: [
{
type: "VariableDeclaration",
kind: "let",
declarations: [
{
type: "VariableDeclarator",
id: {
type: "Identifier",
name: "a",
start: 4,
end: 5,
},
init: {
type: "FunctionExpression",
id: null,
params: [],
body: {
type: "BlockStatement",
body: [],
start: 19,
end: 21,
},
start: 8,
end: 21,
},
start: 0,
end: 21,
},
],
start: 0,
end: 21,
},
],
start: 0,
end: 21,
};
const code = `let a = function() {};`;
const tokenizer = new Tokenizer(code);
const parser = new Parser(tokenizer.tokenize());
expect(parser.parse()).toEqual(result);
});
});实现 Bundler
首先我们来梳理一下整体的实现思路,如下图所示:
第一步我们需要获取模块的内容并解析模块 AST,然后梳理模块间的依赖关系,生成一张模块依赖图(ModuleGraph)。
接下来,我们根据模块依赖图生成拓扑排序后的模块列表,以保证最后的产物中各个模块的顺序是正确的,比如模块 A 依赖了模块 B,那么在产物中,模块 B 的代码需要保证在模块 A 的代码之前执行。
当然,Tree Shaking 的实现也是很重要的一环,我会带你实现一个基于 import/export 符号分析的 Tree Shaking 效果,保证只有被 import 的部分被打包进产物。最后,我们便可以输出完整的 Bundle 代码,完成模块打包。
开发环境搭建
我们先来搭建一下项目的基本开发环境,首先新建目录my-bundler,然后进入目录中执行 pnpm init -y 初始化,安装一些必要的依赖:
新项目需与
ast-parser平级,因为需要使用到ast-parser
pnpm i magic-string -S
pnpm i @types/node tsup typescript typescript-transform-paths -D新建tsconfig.json,内容如下:
{
"compilerOptions": {
"target": "es2016",
"allowJs": true,
"module": "commonjs",
"moduleResolution": "node",
"outDir": "dist",
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true,
"strict": true,
"skipLibCheck": true,
"sourceMap": true,
"baseUrl": "src",
"rootDir": "src",
"declaration": true,
"plugins": [
{
"transform": "typescript-transform-paths" /* 支持别名 */
},
{
"transform": "typescript-transform-paths",
"afterDeclarations": true /* 支持类型文件中的别名 */
}
],
"paths": {
"*": ["./*"],
"ast-parser": ["../../ast-parser"] /* AST 解析器的路径*/
}
},
"include": ["src"],
"references": [{ "path": "../ast-parser" }]
}然后在 package.json 中添加如下的构建脚本:
"scripts": {
"dev": "tsup ./src/rollup.ts --format cjs,esm --dts --clean --watch",
"build": "tsup ./src/rollup.ts --format cjs,esm --dts --clean --minify"
}接下来,你可以在src目录下新建index.ts,内容如下:
// src/index.ts
import { Bundle } from './Bundle';
export interface BuildOptions {
input: string;
}
export function build(options: BuildOptions) {
const bundle = new Bundle({
entry: options.input
});
return bundle.build().then(() => {
return {
generate: () => bundle.render()
};
});
}由此可见,所有核心的逻辑我们封装在了 Bundle 对象中,接着新建Bundle.ts及其依赖的Graph.ts, 添加如下的代码骨架:
// Bundle.ts
export class Bundle {
graph: Graph;
constructor(options: BundleOptions) {
// 初始化模块依赖图对象
this.graph = new Graph({
entry: options.entry,
bundle: this
});
}
async build() {
// 模块打包逻辑,完成所有的 AST 相关操作
return this.graph.build();
}
render() {
// 代码生成逻辑,拼接模块 AST 节点,产出代码
}
getModuleById(id: string) {
return this.graph.getModuleById(id);
}
addModule(module: Module) {
return this.graph.addModule(module);
}
}
// Graph.ts
// 模块依赖图对象的实现
import { dirname, resolve } from 'path';
export class Graph {
entryPath: string;
basedir: string;
moduleById: Record<string, Module> = {};
modules: Module[] = [];
constructor(options: GraphOptions) {
const { entry, bundle } = options;
this.entryPath = resolve(entry);
this.basedir = dirname(this.entryPath);
this.bundle = bundle;
}
async build() {
// 1. 获取并解析模块信息
// 2. 构建依赖关系图
// 3. 模块拓扑排序
// 4. Tree Shaking, 标记需要包含的语句
}
getModuleById(id: string) {
return this.moduleById[id];
}
addModule(module: Module) {
if (!this.moduleById[module.id]) {
this.moduleById[module.id] = module;
this.modules.push(module);
}
}
}接下来,我们就正式开始实现打包器的模块解析逻辑。
模块 AST 解析
我们基于目前的 Graph.ts 继续开发,首先在 Graph 对象中初始化模块加载器(ModuleLoader):
// src/Graph.ts
import { dirname, resolve } from 'path';
export class Graph {
constructor(options: GraphOptions) {
// 省略其它代码
// 初始化模块加载器对象
this.moduleLoader = new ModuleLoader(bundle);
}
async build() {
// 1. 获取并解析模块信息,返回入口模块对象
const entryModule = await this.moduleLoader.fetchModule(
this.entryPath,
null,
true
);
}
}然后添加ModuleLoader.ts,代码如下:
// src/ModuleLoader.ts
export class ModuleLoader {
bundle: Bundle;
resolveIdsMap: Map<string, string | false> = new Map();
constructor(bundle: Bundle) {
this.bundle = bundle;
}
// 解析模块逻辑
resolveId(id: string, importer: string | null) {
const cacheKey = id + importer;
if (this.resolveIdsMap.has(cacheKey)) {
return this.resolveIdsMap.get(cacheKey)!;
}
const resolved = defaultResolver(id, importer);
this.resolveIdsMap.set(cacheKey, resolved);
return resolved;
}
// 加载模块内容并解析
async fetchModule(
id: string,
importer: null | string,
isEntry = false,
bundle: Bundle = this.bundle,
loader: ModuleLoader = this
): Promise<Module | null> {
const path = this.resolveId(id, importer);
// 查找缓存
const existModule = this.bundle.getModuleById(path);
if (existModule) {
return existModule;
}
const code = await readFile(path, { encoding: 'utf-8' });
// 初始化模块,解析 AST
const module = new Module({
path,
code,
bundle,
loader,
isEntry
});
this.bundle.addModule(module);
// 拉取所有的依赖模块
await this.fetchAllDependencies(module);
return module;
}
async fetchAllDependencies(module: Module) {
await Promise.all(
module.dependencies.map((dep) => {
return this.fetchModule(dep, module.path);
})
);
}
}主要由 fetchModule 方法完成模块的加载和解析,流程如下:
- 调用 resolveId 方法解析模块路径
- 初始化模块实例即 Module 对象,解析模块 AST
- 递归初始化模块的所有依赖模块
其中,最主要的逻辑在于第二步,即 Module 对象实例的初始化,在这个过程中,模块代码将会被进行 AST 解析及依赖分析。接下来,让我们把目光集中在 Module 对象的实现上。
// src/Module.ts
export class Module {
isEntry: boolean = false;
id: string;
path: string;
bundle: Bundle;
moduleLoader: ModuleLoader;
code: string;
magicString: MagicString;
statements: Statement[];
imports: Imports;
exports: Exports;
reexports: Exports;
exportAllSources: string[] = [];
exportAllModules: Module[] = [];
dependencies: string[] = [];
dependencyModules: Module[] = [];
referencedModules: Module[] = [];
constructor({ path, bundle, code, loader, isEntry = false }: ModuleOptions) {
this.id = path;
this.bundle = bundle;
this.moduleLoader = loader;
this.isEntry = isEntry;
this.path = path;
this.code = code;
this.magicString = new MagicString(code);
this.imports = {};
this.exports = {};
this.reexports = {};
this.declarations = {};
try {
const ast = parse(code) as any;
const nodes = ast.body as StatementNode[];
// 以语句(Statement)的维度来拆分 Module,保存 statement 的集合,供之后分析
this.statements = nodes.map((node) => {
const magicString = this.magicString.snip(node.start, node.end);
// Statement 对象将在后文中介绍具体实现
return new Statement(node, magicString, this);
});
} catch (e) {
console.log(e);
throw e;
}
// 分析 AST 节点
this.analyseAST();
}
analyseAST() {
// 以语句为最小单元来分析
this.statements.forEach((statement) => {
// 对 statement 进行分析
statement.analyse();
// 注册顶层声明
if (!statement.scope.parent) {
statement.scope.eachDeclaration((name, declaration) => {
this.declarations[name] = declaration;
});
}
});
// 注册 statement 的 next 属性,用于生成代码使用,next 即下一个 statement 的起始位置
const statements = this.statements;
let next = this.code.length;
for (let i = statements.length - 1; i >= 0; i--) {
statements[i].next = next;
next = statements[i].start;
}
}
}我们可以来梳理一下解析 AST 节点主要做了哪些事情:
- 调用 ast-parser 将代码字符串解析为 AST 对象。
- 遍历 AST 对象中的各个语句,以语句的维度来进行 AST 分析,通过语句的分析结果来构造作用域链和模块依赖关系。
ast-parser 的解析部分我们已经详细介绍过,这里不再赘述。接下来我们将重点放到 Statement 对象的实现上。你可以新建src/Statement.ts,内容如下:
// src/Statement.ts
// 以下为三个工具函数
// 是否为函数节点
function isFunctionDeclaration(node: Declaration): boolean {
if (!node) return false;
return (
// function foo() {}
node.type === 'FunctionDeclaration' ||
// const foo = function() {}
(node.type === NodeType.VariableDeclarator &&
node.init &&
node.init.type === NodeType.FunctionExpression) ||
// export function ...
// export default function
((node.type === NodeType.ExportNamedDeclaration ||
node.type === NodeType.ExportDefaultDeclaration) &&
!!node.declaration &&
node.declaration.type === NodeType.FunctionDeclaration)
);
}
// 是否为 export 声明节点
export function isExportDeclaration(node: ExportDeclaration): boolean {
return /^Export/.test(node.type);
}
// 是否为 import 声明节点
export function isImportDeclaration(node: any) {
return node.type === 'ImportDeclaration';
}
export class Statement {
node: StatementNode;
magicString: MagicString;
module: Module;
scope: Scope;
start: number;
next: number;
isImportDeclaration: boolean;
isExportDeclaration: boolean;
isReexportDeclaration: boolean;
isFunctionDeclaration: boolean;
isIncluded: boolean = false;
defines: Set<string> = new Set();
modifies: Set<string> = new Set();
dependsOn: Set<string> = new Set();
references: Reference[] = [];
constructor(node: StatementNode, magicString: MagicString, module: Module) {
this.magicString = magicString;
this.node = node;
this.module = module;
this.scope = new Scope({
statement: this
});
this.start = node.start;
this.next = 0;
this.isImportDeclaration = isImportDeclaration(node);
this.isExportDeclaration = isExportDeclaration(node as ExportDeclaration);
this.isReexportDeclaration =
this.isExportDeclaration &&
!!(node as ExportAllDeclaration | ExportNamedDeclaration).source;
this.isFunctionDeclaration = isFunctionDeclaration(
node as FunctionDeclaration
);
}
analyse() {
if (this.isImportDeclaration) return;
// 1、构建作用域链,记录 Declaration 节点表
buildScope(this);
// 2. 寻找引用的依赖节点,记录 Reference 节点表
findReference(this);
}
}在 Statement 节点的分析过程中主要需要做两件事情:
- 构建作用域链。这是为了记录当前语句中声明的变量。
- 记录引用的依赖节点。这是为了记录当前语句引用了哪些变量以及这些变量对应的 AST 节点。
而无论是构建作用域链还是记录引用节点,我们都离不开一个最基本的操作,那就是对 AST 进行遍历操作。你可以新建src/utils/walk.ts,用来存放 AST 节点遍历的逻辑。
let shouldSkip;
let shouldAbort: boolean;
export function walk(ast: any, { enter, leave }: { enter: any; leave: any }) {
shouldAbort = false;
visit(ast, null, enter, leave);
}
let context = {
skip: () => (shouldSkip = true),
abort: () => (shouldAbort = true)
};
let childKeys = {} as Record<string, string[]>;
let toString = Object.prototype.toString;
function isArray(thing: Object) {
return toString.call(thing) === '[object Array]';
}
function visit(node: any, parent: any, enter: any, leave: any, prop?: string) {
if (!node || shouldAbort) return;
if (enter) {
shouldSkip = false;
enter.call(context, node, parent, prop);
if (shouldSkip || shouldAbort) return;
}
let keys =
childKeys[node.type] ||
(childKeys[node.type] = Object.keys(node).filter(
(key) => typeof node[key] === 'object'
));
let key, value;
for (let i = 0; i < keys.length; i++) {
key = keys[i];
value = node[key];
if (isArray(value)) {
for (let j = 0; j < value.length; j++) {
visit(value[j], node, enter, leave, key);
}
} else if (value && value.type) {
visit(value, node, enter, leave, key);
}
}
if (leave && !shouldAbort) {
leave(node, parent, prop);
}
}接下来我们主要通过这个遍历器来完成 Statement 节点的分析。对于作用域链的分析,我们先来新建一个 Scope 对象,封装作用域相关的基本信息:
// src/utils/Scope.ts
import { Statement } from 'Statement';
import { Declaration } from 'ast/Declaration';
interface ScopeOptions {
parent?: Scope;
paramNodes?: any[];
block?: boolean;
statement: Statement;
isTopLevel?: boolean;
}
export class Scope {
// 父作用域
parent?: Scope;
// 如果是函数作用域,则需要参数节点
paramNodes: any[];
// 是否为块级作用域
isBlockScope?: boolean;
// 作用域对应的语句节点
statement: Statement;
// 变量/函数 声明节点,为 Scope 的核心数据
declarations: Record<string, Declaration> = {};
constructor(options: ScopeOptions) {
const { parent, paramNodes, block, statement } = options;
this.parent = parent;
this.paramNodes = paramNodes || [];
this.statement = statement;
this.isBlockScope = !!block;
this.paramNodes.forEach(
(node) =>
(this.declarations[node.name] = new Declaration(
node,
true,
this.statement
))
);
}
addDeclaration(node: any, isBlockDeclaration: boolean) {
// block scope & var, 向上追溯,直到顶层作用域
if (this.isBlockScope && !isBlockDeclaration && this.parent) {
this.parent.addDeclaration(node, isBlockDeclaration);
} else {
// 否则在当前作用域新建声明节点(Declaration)
const key = node.id && node.id.name;
this.declarations[key] = new Declaration(node, false, this.statement);
}
}
// 遍历声明节点(Declaration)
eachDeclaration(fn: (name: string, dec: Declaration) => void) {
Object.keys(this.declarations).forEach((key) => {
fn(key, this.declarations[key]);
});
}
contains(name: string): Declaration {
return this.findDeclaration(name);
}
findDeclaration(name: string): Declaration {
return (
this.declarations[name] ||
(this.parent && this.parent.findDeclaration(name))
);
}
}Scope 的核心在于声明节点(即Declaration)的收集与存储,而上述的代码中并没有 Declaration 对象的实现,接下来我们来封装一下这个对象:
// src/ast/Declaration.ts
import { Module } from '../Module';
import { Statement } from '../Statement';
import { Reference } from './Reference';
export class Declaration {
isFunctionDeclaration: boolean = false;
functionNode: any;
statement: Statement | null;
name: string | null = null;
isParam: boolean = false;
isUsed: boolean = false;
isReassigned: boolean = false;
constructor(node: any, isParam: boolean, statement: Statement | null) {
// 考虑函数和变量声明两种情况
if (node) {
if (node.type === 'FunctionDeclaration') {
this.isFunctionDeclaration = true;
this.functionNode = node;
} else if (
node.type === 'VariableDeclarator' &&
node.init &&
/FunctionExpression/.test(node.init.type)
) {
this.isFunctionDeclaration = true;
this.functionNode = node.init;
}
}
this.statement = statement;
this.isParam = isParam;
}
addReference(reference: Reference) {
reference.declaration = this;
this.name = reference.name;
}
}既然有了声明节点,那么我们如果感知到哪些地方使用了这些节点呢?这时候就需要 Reference 节点登场了,它的作用就是记录其它节点与 Declaration 节点的引用关系,让我门来简单实现一下:
import { Scope } from './Scope';
import { Statement } from '../Statement';
import { Declaration } from './Declaration';
export class Reference {
node: any;
scope: Scope;
statement: Statement;
// declaration 信息在构建依赖图的部分补充
declaration: Declaration | null = null;
name: string;
start: number;
end: number;
objectPaths: any[] = [];
constructor(node: any, scope: Scope, statement: Statement) {
this.node = node;
this.scope = scope;
this.statement = statement;
this.start = node.start;
this.end = node.end;
let root = node;
this.objectPaths = [];
while (root.type === 'MemberExpression') {
this.objectPaths.unshift(root.property);
root = root.object;
}
this.objectPaths.unshift(root);
this.name = root.name;
}
}前面铺垫了这么多基础的数据结构,让大家了解到各个关键对象的作用及其联系,接下来我们正式开始编写构建作用域链的代码。
你可以新建src/utils/buildScope.ts,内容如下:
import { walk } from 'utils/walk';
import { Scope } from 'ast/Scope';
import { Statement } from 'Statement';
import {
NodeType,
Node,
VariableDeclaration,
VariableDeclarator
} from 'ast-parser';
import { FunctionDeclaration } from 'ast-parser';
export function buildScope(statement: Statement) {
const { node, scope: initialScope } = statement;
let scope = initialScope;
// 遍历 AST
walk(node, {
// 遵循深度优先的原则,每进入和离开一个节点会触发 enter 和 leave 钩子
// 如 a 的子节点为 b,那么触发顺序为 a-enter、b-enter、b-leave、a-leave
enter(node: Node) {
// function foo () {...}
if (node.type === NodeType.FunctionDeclaration) {
scope.addDeclaration(node, false);
}
// var let const
if (node.type === NodeType.VariableDeclaration) {
const currentNode = node as VariableDeclaration;
const isBlockDeclaration = currentNode.kind !== 'var';
currentNode.declarations.forEach((declarator: VariableDeclarator) => {
scope.addDeclaration(declarator, isBlockDeclaration);
});
}
let newScope;
// function scope
if (node.type === NodeType.FunctionDeclaration) {
const currentNode = node as FunctionDeclaration;
newScope = new Scope({
parent: scope,
block: false,
paramNodes: currentNode.params,
statement
});
}
// new block scope
if (node.type === NodeType.BlockStatement) {
newScope = new Scope({
parent: scope,
block: true,
statement
});
}
// 记录 Scope 父子关系
if (newScope) {
Object.defineProperty(node, '_scope', {
value: newScope,
configurable: true
});
scope = newScope;
}
},
leave(node: any) {
// 更新当前作用域
// 当前 scope 即 node._scope
if (node._scope && scope.parent) {
scope = scope.parent;
}
}
});
}从中可以看到,我们会对如下类型的 AST 节点进行处理:
- 变量声明节点。包括
var、let和const声明对应的节点。对let和const,我们需要将声明节点绑定到当前作用域中,而对于var,需要绑定到全局作用域。 - 函数声明节点。对于这类节点,我们直接创建一个新的作用域。
- 块级节点。即用
{ }包裹的节点,如 if 块、函数体,此时我们也创建新的作用域。
在构建完作用域完成后,我们进入下一个环节: 记录引用节点。
新建src/utils/findReference.ts,内容如下:
import { Statement } from 'Statement';
import { walk } from 'utils/walk';
import { Reference } from 'ast/Reference';
function isReference(node: any, parent: any): boolean {
if (node.type === 'MemberExpression' && parent.type !== 'MemberExpression') {
return true;
}
if (node.type === 'Identifier') {
// 如 export { foo as bar }, 忽略 bar
if (parent.type === 'ExportSpecifier' && node !== parent.local)
return false;
// 如 import { foo as bar } from 'xxx', 忽略 bar
if (parent.type === 'ImportSpecifier' && node !== parent.imported) {
return false;
}
return true;
}
return false;
}
export function findReference(statement: Statement) {
const { references, scope: initialScope, node } = statement;
let scope = initialScope;
walk(node, {
enter(node: any, parent: any) {
if (node._scope) scope = node._scope;
if (isReference(node, parent)) {
// 记录 Reference 节点
const reference = new Reference(node, scope, statement);
references.push(reference);
}
},
leave(node: any) {
if (node._scope && scope.parent) {
scope = scope.parent;
}
}
});
}至此,我们就完成了模块 AST 解析的功能。
模块依赖图绑定
回到 Graph 对象中,接下来我们需要实现的是模块依赖图的构建:
// src/Graph.ts
export class Graph {
async build() {
// ✅(完成) 1. 获取并解析模块信息
// 2. 构建依赖关系图
this.module.forEach(module => module.bind());
// 3. 模块拓扑排序
// 4. Tree Shaking, 标记需要包含的语句
}
}现在我们在 Module 对象的 AnalyzeAST 中新增依赖绑定的代码:
// src/Module.ts
analyzeAST() {
// 如果语句为 import/export 声明,那么给当前模块记录依赖的标识符
this.statements.forEach((statement) => {
if (statement.isImportDeclaration) {
this.addImports(statement);
} else if (statement.isExportDeclaration) {
this.addExports(statement);
}
});
}
// 处理 import 声明
addImports(statement: Statement) {
const node = statement.node as any;
const source = node.source.value;
// import
node.specifiers.forEach((specifier: Specifier) => {
// 为方便理解,本文只处理具名导入
const localName = specifier.local.name;
const name = specifier.imported.name;
this.imports[localName] = { source, name, localName };
});
this._addDependencySource(source);
}
// 处理 export 声明
addExports(statement: Statement) {
const node = statement.node as any;
const source = node.source && node.source.value;
// 为方便立即,本文只处理具名导出
if (node.type === 'ExportNamedDeclaration') {
// export { a, b } from 'mod'
if (node.specifiers.length) {
node.specifiers.forEach((specifier: Specifier) => {
const localName = specifier.local.name;
const exportedName = specifier.exported.name;
this.exports[exportedName] = {
localName,
name: exportedName
};
if (source) {
this.reexports[localName] = {
statement,
source,
localName,
name: localName,
module: undefined
};
this.imports[localName] = {
source,
localName,
name: localName
};
this._addDependencySource(source);
}
});
} else {
const declaration = node.declaration;
let name;
if (declaration.type === 'VariableDeclaration') {
// export const foo = 2;
name = declaration.declarations[0].id.name;
} else {
// export function foo() {}
name = declaration.id.name;
}
this.exports[name] = {
statement,
localName: name,
name
};
}
} else if (node.type === 'ExportAllDeclaration') {
// export * from 'mod'
if (source) {
this.exportAllSources.push(source);
this.addDependencySource(source);
}
}
}
private _addDependencySource(source: string) {
if (!this.dependencies.includes(source)) {
this.dependencies.push(source);
}
}在记录完 import 和 export 的标识符之后,我们根据这些标识符绑定到具体的模块对象,新增bind方法,实现如下:
bind() {
// 省略已有代码
// 记录标识符对应的模块对象
this.bindDependencies();
/// 除此之外,根据之前记录的 Reference 节点绑定对应的 Declaration 节点
this.bindReferences();
}
bindDependencies() {
[...Object.values(this.imports), ...Object.values(this.reexports)].forEach(
(specifier) => {
specifier.module = this._getModuleBySource(specifier.source!);
}
);
this.exportAllModules = this.exportAllSources.map(
this._getModuleBySource.bind(this)
);
// 建立模块依赖图
this.dependencyModules = this.dependencies.map(
this._getModuleBySource.bind(this)
);
this.dependencyModules.forEach((module) => {
module.referencedModules.push(this);
});
}
bindReferences() {
this.statements.forEach((statement) => {
statement.references.forEach((reference) => {
// 根据引用寻找声明的位置
// 寻找顺序: 1. statement 2. 当前模块 3. 依赖模块
const declaration =
reference.scope.findDeclaration(reference.name) ||
this.trace(reference.name);
if (declaration) {
declaration.addReference(reference);
}
});
});
}
private _getModuleBySource(source: string) {
const id = this.moduleLoader.resolveId(source!, this.path) as string;
return this.bundle.getModuleById(id);
}现在,我们便将各个模块间的依赖关系绑定完成了。
模块拓扑排序
接下来,我们将所有的模块根据依赖关系进行拓扑排序:
// src/Graph.ts
export class Graph {
async build() {
// ✅(完成) 1. 获取并解析模块信息
// ✅(完成) 2. 构建依赖关系图
// 3. 模块拓扑排序
this.orderedModules = this.sortModules(entryModule!);
// 4. Tree Shaking, 标记需要包含的语句
}
sortModules(entryModule: Module) {
// 拓扑排序模块数组
const orderedModules: Module[] = [];
// 记录已经分析过的模块表
const analysedModule: Record<string, boolean> = {};
// 记录模块的父模块 id
const parent: Record<string, string> = {};
// 记录循环依赖
const cyclePathList: string[][] = [];
// 用来回溯,用来定位循环依赖
function getCyclePath(id: string, parentId: string): string[] {
const paths = [id];
let currrentId = parentId;
while (currrentId !== id) {
paths.push(currrentId);
// 向前回溯
currrentId = parent[currrentId];
}
paths.push(paths[0]);
return paths.reverse();
}
// 拓扑排序核心逻辑,基于依赖图的后序遍历完成
function analyseModule(module: Module) {
if (analysedModule[module.id]) {
return;
}
for (const dependency of module.dependencyModules) {
// 检测循环依赖
// 为什么是这个条件,下文会分析
if (parent[dependency.id]) {
if (!analysedModule[dependency.id]) {
cyclePathList.push(getCyclePath(dependency.id, module.id));
}
continue;
}
parent[dependency.id] = module.id;
analyseModule(dependency);
}
analysedModule[module.id] = true;
orderedModules.push(module);
}
// 从入口模块开始分析
analyseModule(entryModule);
// 如果有循环依赖,则打印循环依赖信息
if (cyclePathList.length) {
cyclePathList.forEach((paths) => {
console.log(paths);
});
process.exit(1);
}
return orderedModules;
}
}拓扑排序的核心在于对依赖图进行后续遍历,将被依赖的模块放到前面,如下图所示:
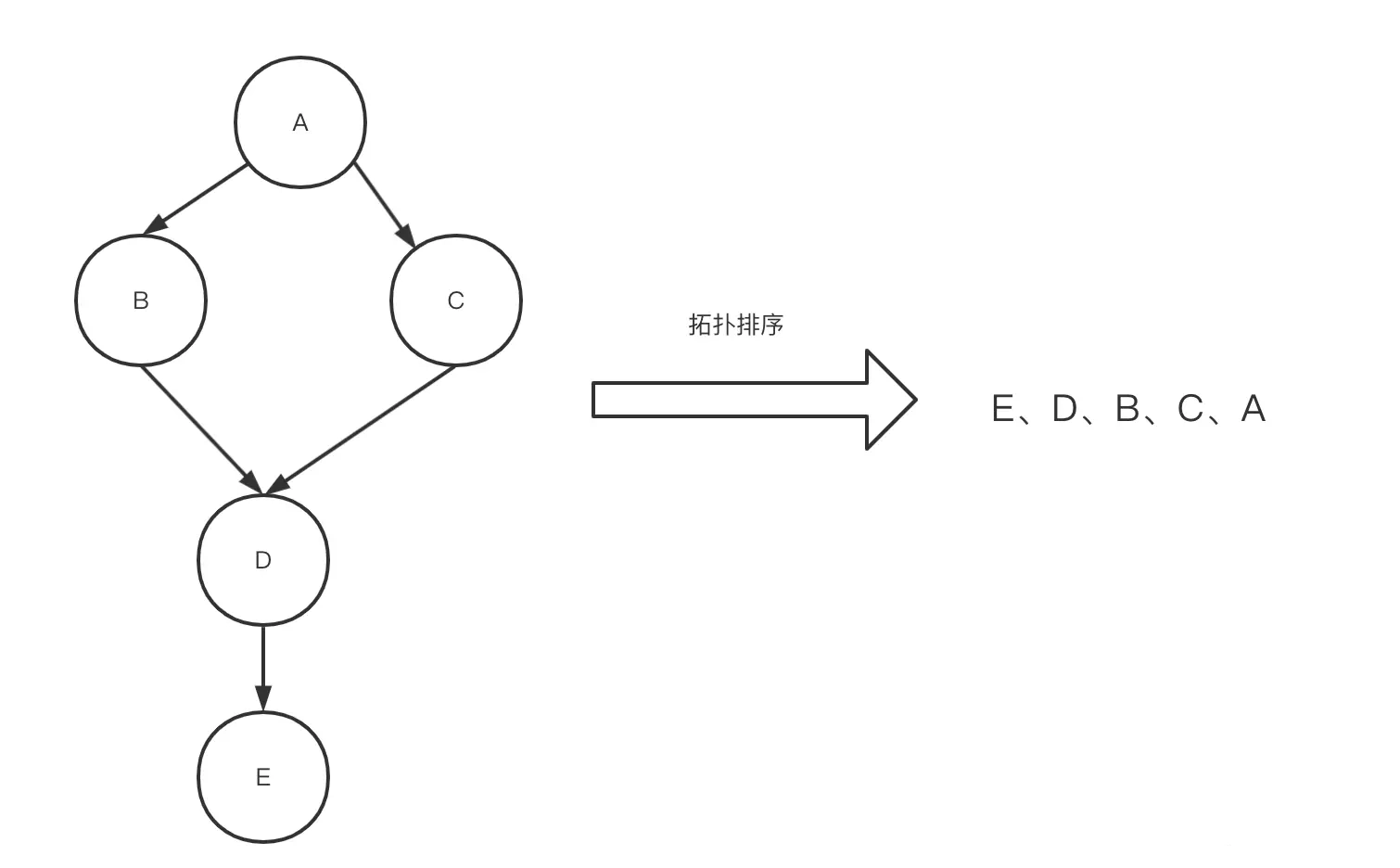
其中 A 依赖 B 和 C,B 和 C 依赖 D,D 依赖 E,那么最后的拓扑排序即E、D、B、C、A。但也有一种特殊情况,就是出现循环的情况,如下面这张图所示:
上图中的依赖关系呈现了B->C->D->B的循环依赖,这种情况是我们需要避免的。那么如何来检测出循环依赖呢?
由于 analyseModule 函数中采用后序的方式来遍历依赖,也就是说一旦某个模块被记录到 analysedModule 表中,那么也就意味着其所有的依赖模块已经被遍历完成了:
function analyseModule(module: Module) {
if (analysedModule[module.id]) {
return;
}
for (const dependency of module.dependencyModules) {
// 检测循环依赖的代码省略
parent[dependency.id] = module.id;
analyseModule(dependency);
}
analysedModule[module.id] = true;
orderedModules.push(module);
}如果某个模块没有被记录到 analysedModule 中,则表示它的依赖模块并没有分析完,在这个前提下中,如果再次遍历到这个模块,说明已经出现了循环依赖,因此检测循环依赖的条件应该为下面这样:
for (const dependency of module.dependencyModules) {
// 检测循环依赖
// 1. 不为入口模块
if (parent[dependency.id]) {
// 2. 依赖模块还没有分析结束
if (!analysedModule[dependency.id]) {
cyclePathList.push(getCyclePath(dependency.id, module.id));
}
continue;
}
parent[dependency.id] = module.id;
analyseModule(dependency);
}到目前为止,我们完成了第三步模块拓扑排序的步骤,接下来我们进入 Tree Shaking 功能的开发:
// src/Graph.ts
export class Graph {
async build() {
// ✅(完成) 1. 获取并解析模块信息
// ✅(完成) 2. 构建依赖关系图
// ✅(完成) 3. 模块拓扑排序
// 4. Tree Shaking, 标记需要包含的语句
}
}实现 Tree Shaking
相信 Tree Shaking 对于大家并不陌生,它主要的作用就是在打包产物中摇掉没有使用的代码,从而优化产物体积。而得益于 ES 模块的静态特性,我们可以基于 import/export 的符号可达性来进行 Tree Shaking 分析,如:
// index.ts
import { a } from './utils';
console.log(a);
// utils.ts
export const a = 1;
export const b = 2;由于在如上的代码中我们只使用到了 a,则 a 属于可达符号,b 属于不可达符号,因此最后的代码不会包含 b 相关的实现代码。
接下来我们就来实现这一功能,即基于符号可达性来进行无用代码的删除。
// src/Graph.ts
export class Graph {
async build() {
// ✅(完成) 1. 获取并解析模块信息
// ✅(完成) 2. 构建依赖关系图
// ✅(完成) 3. 模块拓扑排序
// 4. Tree Shaking, 标记需要包含的语句
// 从入口处分析
entryModule!.getExports().forEach((name) => {
const declaration = entryModule!.traceExport(name);
declaration!.use();
});
}
}在 Module 对象中,我们需要增加getExports和traceExport方法来获取和分析模块的导出:
// 拿到模块所有导出
getExports(): string[] {
return [
...Object.keys(this.exports),
...Object.keys(this.reexports),
...this.exportAllModules
.map(module => module.getExports())
.flat()
];
}
// 从导出名追溯到 Declaration 声明节点
traceExport(name: string): Declaration | null {
// 1. reexport
// export { foo as bar } from './mod'
const reexportDeclaration = this.reexports[name];
if (reexportDeclaration) {
// 说明是从其它模块 reexport 出来的
// 经过 bindDependencies 方法处理,现已绑定 module
const declaration = reexportDeclaration.module!.traceExport(
reexportDeclaration.localName
);
if (!declaration) {
throw new Error(
`${reexportDeclaration.localName} is not exported by module ${
reexportDeclaration.module!.path
}(imported by ${this.path})`
);
}
return declaration;
}
// 2. export
// export { foo }
const exportDeclaration = this.exports[name];
if (exportDeclaration) {
const declaration = this.trace(name);
if (declaration) {
return declaration;
}
}
// 3. export all
for (let exportAllModule of this.exportAllModules) {
const declaration = exportAllModule.trace(name);
if (declaration) {
return declaration;
}
}
return null;
}
trace(name: string) {
if (this.declarations[name]) {
// 从当前模块找
return this.declarations[name];
}
// 从依赖模块找
if (this.imports[name]) {
const importSpecifier = this.imports[name];
const importModule = importSpecifier.module!;
const declaration = importModule.traceExport(importSpecifier.name);
if (declaration) {
return declaration;
}
}
return null;
}当我们对每个导出找到对应的 Declaration 节点之后,则对这个节点进行标记,从而让其代码能够在代码生成阶段得以保留。那么如何进行标记呢?
我们不妨回到 Declaration 的实现中,增加 use 方法:
use() {
// 标记该节点被使用
this.isUsed = true;
// 对应的 statement 节点也应该被标记
if (this.statement) {
this.statement.mark();
}
}
// 另外,你可以加上 render 方法,便于后续代码生成的步骤
render() {
return this.name;
}接下来我们到 Statement 对象中,继续增加 mark 方法,来追溯被使用过的 Declaration 节点:
// src/Statement.ts
mark() {
if (this.isIncluded) {
return;
}
this.isIncluded = true;
this.references.forEach(
(ref: Reference) => ref.declaration && ref.declaration.use()
);
}这时候,Reference 节点的作用就体现出来了,由于我们之前专门收集到 Statement 的 Reference 节点,通过 Reference 节点我们可以追溯到对应的 Declaration 节点,并调用其 use 方法进行标记。
代码生成
如此,我们便完成了 Tree Shaking 的标记过程,接下来我们看看如何来进行代码生成,直观地看到 Tree Shaking 的效果。
我们在 Module 对象中增加render方法,用来将模块渲染为字符串:
render() {
const source = this.magicString.clone().trim();
this.statements.forEach((statement) => {
// 1. Tree Shaking
if (!statement.isIncluded) {
source.remove(statement.start, statement.next);
return;
}
// 2. 重写引用位置的变量名 -> 对应的声明位置的变量名
statement.references.forEach((reference) => {
const { start, end } = reference;
const declaration = reference.declaration;
if (declaration) {
const name = declaration.render();
source.overwrite(start, end, name!);
}
});
// 3. 擦除/重写 export 相关的代码
if (statement.isExportDeclaration && !this.isEntry) {
// export { foo, bar }
if (
statement.node.type === 'ExportNamedDeclaration' &&
statement.node.specifiers.length
) {
source.remove(statement.start, statement.next);
}
// remove `export` from `export const foo = 42`
else if (
statement.node.type === 'ExportNamedDeclaration' &&
(statement.node.declaration!.type === 'VariableDeclaration' ||
statement.node.declaration!.type === 'FunctionDeclaration')
) {
source.remove(
statement.node.start,
statement.node.declaration!.start
);
}
// remove `export * from './mod'`
else if (statement.node.type === 'ExportAllDeclaration') {
source.remove(statement.start, statement.next);
}
}
});
return source.trim();
}接着,我们在 Bundle 对象也实现一下 render 方法,用来生成最后的产物代码:
render(): { code: string } {
let msBundle = new MagicString.Bundle({ separator: '\n' });
// 按照模块拓扑顺序生成代码
this.graph.orderedModules.forEach((module) => {
msBundle.addSource({
content: module.render()
});
});
return {
code: msBundle.toString(),
};
}现在我们终于可以来测试目前的 Bundler 功能了,测试代码如下:
// test.js
const fs = require('fs');
const { build } = require('./dist/index');
async function buildTest() {
const bundle = await build({
input: './test/index.js'
});
const res = bundle.generate();
fs.writeFileSync('./test/bundle.js', res.code);
}
buildTest();
// test/index.js
import { a, add } from './utils.js';
export const c = add(a, 2);
// test/utils.js
export const a = 1;
export const b = 2;
export const add = function (num1, num2) {
return num1 + num2;
};在终端执行node test.js,即可将产物代码输出到 test 目录下的 bundle.js 中:
// test/bundle.js
const a = 1;
const add = function (num1, num2) {
return num1 + num2;
};
export const c = add(a, 2);可以看到,最后的产物代码已经成功生成,变量 b 相关的代码已经完全从产出中擦除,实现了基于符号可达性的 Tree Shaking 的效果。
Vite 3.0 核心更新盘点与分析
开发阶段的更新
1. CLI 的更新
在执行 vite 命令启动项目时,终端的界面和之前会有所不同,而更重要的是,为了避免 Vite 开发服务的端口和别的应用冲突,默认的端口号从之前的 3000 变成了 5173。
2. 开箱即用的 WebSocket 连接策略
Vite 2 中有存在一个痛点,即在存在代理的情况下(比如 Web IDE)需要我们手动配置 WebSocket 使 HMR 生效。目前 Vite 内置了一套更加完善的 WebSocket 连接策略,自动满足更多场景的 HMR 需求。
3. 服务冷启动性能提升
Vite 3.0 在服务冷启动方面做了非常多的工作,来最大程度提升项目启动的速度。
首先我们来盘点一下 Vite 2.x 阶段服务冷启动的一些问题。
从 Vite 2.0 到 2.9 版本之前,Vite 会在服务启动之前进行依赖预构建,也就是使用 Esbuild 将项目中使用到的依赖扫描出来(Scan),然后分别进行一次打包(Optimize)。

这样会造成两个问题:
- 依赖预构建会阻塞 Dev Server 启动,但其实不阻塞的情况下,Dev Server 也可以正常启动。
- 当某些 Vite 插件手动注入了 import 语句,比如调用
babel-plugin-import添加import Button from 'antd/lib/button',就会导致 Vite 的二次预构建,因为antd/lib/button的引入代码由 Vite 插件注入,属于 Dev Server 运行时发现的依赖,冷启动阶段无法扫描到。
所谓的二次预构建包含两个步骤,一是需要将所有的依赖全量预构建,二是由于依赖更新,页面需要进行 reload,加载最新的依赖代码。这样会导致 Dev Server 性能明显下降,尤其是在新增依赖较多的场景下,很容易出现浏览器卡住的情况。因此二次预构建也是需要极力避免的。当时 vite-plugin-optimize-persist 就是为了解决二次预构建带来的问题,通过持久化的方式记录 Dev Server 运行时扫描到的依赖,从而让首次预构建便可以感知到,避免二次预构建的发生。
到了 2.9 版本,Vite 将预构建的逻辑做了一次整体的重构,最后的效果是下面这样的:
Dev Server 启动后预构建(Optimize 阶段)在后台执行,也就是预构建不再阻塞 Dev Server 的启动,只需要等待 Scan 阶段完成,不过通常这个阶段的开销非常小。
如果某些依赖是 Dev Server 运行时才发现的,那么 Vite 会尽可能地复用已有预构建产物,尽量不进行 page reload。
具体实现大家可以去查看这个 PR
那问题就完全解决了吗?其实并不是,在某些场景下,Vite 仍然不可避免地需要二次预构建。如下面的这个例子:
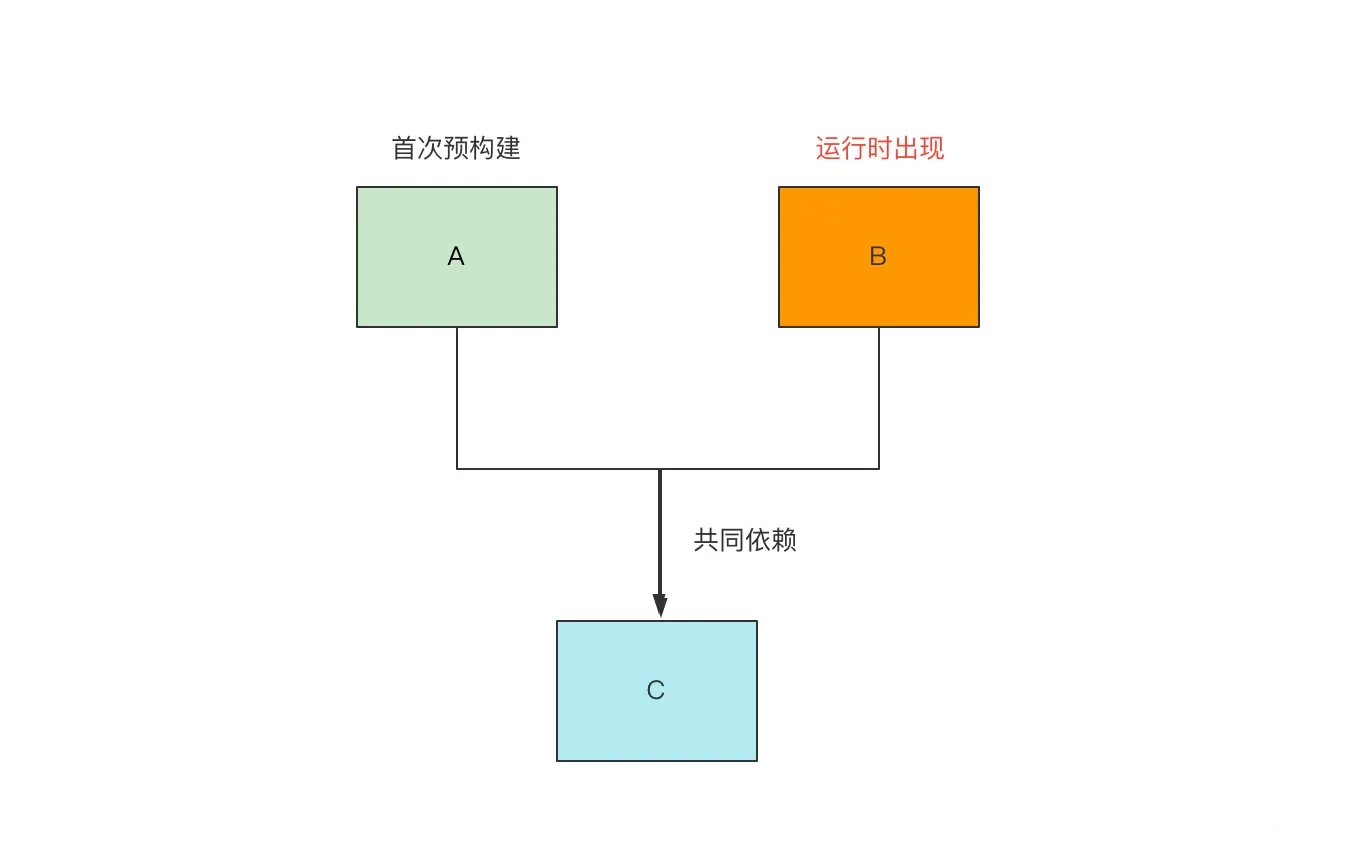
A 和 B 都是项目的第三方依赖,它们也同时依赖 C。那么当 Vite 预构建 A 的时候,将会 A 和 C 一起进行打包。但 Vite 在运行时发现了依赖 B,而 A 和 B 需要共享 C 的代码,这样 C 的代码可能就会被抽离成一个公共的 chunk,因此之前 A 的预构建产物可能就发生变化了,那么此时 Vite 必须要强制刷新页面,让浏览器使用最新的预构建产物。这仍然是一个二次预构建(所有依赖再次打包 + page reload)的过程。
总体而言,2.9 版本解决了预构建阻塞服务启动的问题,但并没有完全解决二次预构建的问题。
但在 Vite 3.0,二次预构建的问题也得到了根本的解决。那 Vite 3.0 是如何做到的呢?
核心的解决思路在于延迟处理,即把预构建的行为延迟到页面加载的最后阶段进行,此时 Vite 已经编译完了所有的源文件,可以准确地记录下所有需要预构建的依赖(包括 Vite 插件添加的一些依赖),然后统一进行预构建,将预构建的产物响应给给浏览器即可。
因此,与 Vite 2.0 相比,Vite 3.0 在冷启动阶段所做的优化主要有两个方面:
- 预构建不再阻塞 Dev Server 的启动,真正做到服务秒启动的效果;
- 从根本上防止二次预构建的发生。
4. import.meta.glob 语法更新
Vite 3.0 对 i 的实现进行了重写,支持了更加灵活的 glob 语法,增加了如下的一些特性:
- 多种模式匹配:ts
import.meta.glob(["./dir/*.js", "./another/*.js"]); - 否定模式(!):ts
import.meta.glob(["./dir/*.js", "!**/bar.js"]); - 命名导入,可以更好地做到 Tree Shaking:ts
import.meta.glob("./dir/*.js", { import: "setup" }); - 自定义 query 参数:ts
import.meta.glob("./dir/*.js", { query: { custom: "data" } }); - 指定 eager 模式,替换掉原来
i:mport.meta.globEager tsimport.meta.glob("./dir/*.js", { eager: true });
三、生产阶段的更新
1. SSR 产物默认使用 ESM 格式
在当下的社区生态中,众多 SSR 框架已经在使用 ESM 格式作为默认的产物格式。Vite 3.0 也积极拥抱社区,支持 SSR 构建默认打包出 ESM 格式的产物。
2. Relative Base 支持
Vite 3.0 正式支持 Relative Base(即配置base: ''),主要用于构建时无法确定 base 地址的场景。
四、实验性功能
1. 更细粒度的 base 配置
在某些场景下,我们需要将不同的资源部署到不同的 CDN 上,比如将图片部署到单独的 CDN,和 JS/CSS 的部署服务区分开来。但 2.x 的版本仅支持统一的部署域名,即base 配置。在 3.0 中,你可以通过 renderBuiltUrl 进行更细粒度的配置:
{
experimental: {
renderBuiltUrl: (filename: string, { hostType: 'js' | 'css' | 'html' }) => {
if (hostType === 'js') {
return { runtime: `window.__toCdnUrl(${JSON.stringify(filename)})` }
} else {
return 'https://cdn.domain.com/assets/' + filename
}
}
}
}2. Esbuild 预构建用于生产环境
这应该是 Vite 架构上非常大的一个改动: 将原来仅仅用于开发阶段的依赖预构建功能应用在生产环境。在 Vite 2.x 中,开发阶段使用 Esbuild 来打包依赖,而在生产环境使用 Rollup 进行打包,用 @rollupjs/plugin-commonjs 来处理 cjs 的依赖,这样做会导致依赖处理的不一致问题,造成一些生产构建中的 bug。
但 Vite 3.0 中支持通过配置将 Esbulid 预构建同时用于开发环境和生产环境,仅添加optimizeDeps.disabled: false 的配置即可。不过这个改动确实比较大,Vite 团队不打算将此作为 v3 的正式更新内容,而是一个实验性质的功能,不会默认开启。
顺便提一句,Rollup 将在接下来的几个月发布 v3 的大版本,要知道,Rollup 2.0 发布至今已经过去 2 年多的时间了,无论是 Rollup 还是 Vite 来讲,这都是一次非常重大的变更。由于 Vite 的架构非常依赖 Rollup,在 Rollup 发布 v3 之后,Vite 也将跟随着发布 Vite 的第 4 个 major 版本。所以,Vite 4.0 的到来也不远啦:)
五、仓库内部的变化
除了本身功能上的演进,Vite 的仓库本身也产生了不少的变化,从中我们也能了解到社区的一些动向:
- 不再支持 Nodejs 12,需要 Node.js 14.18+ 的版本。
- 单元测试和 E2E 测试从 Jest 完全迁移到 Vitest,一方面 Vitest 更快、体验更好,另一方面也能在 Vite 这样大型的仓库完善 Vitest 的生态,进一步提升 Vitest 稳定性。
- VitePress 文档部分也参与 CI 流程。
- 包管理器 pnpm 迁移至 v7。
- 不管是
Vite本身的包还是 E2E 中测试的项目,都在 package.json 中声明type: "module",即 Pure ESM 包,对外提供 ESM 格式的产物,将社区 Pure ESM 的趋势又推动了一步。 - 官方所有的 Vite 插件都采用
unbuild(新一代库构建工具) 进行构建,pluin-vue-jsx和plugin-legacy均迁移到了 TS 上。 - 包体积优化。3.0 进一步优化 Vite 本身的产物和 node_modules 体积,将
terser和node-forge的依赖移除,让用户进行按需安装(node-forge的功能是实现 https 证书生成,可用@vitejs/plugin-basic-ssl插件替代)
不得不说在自身包体积的优化方面, Vite 还是做的很细致的,这也是很多库开发者忽视的一点,有时候加个插件就得安装动辄上百 MB 的依赖,导致项目的 node_modules 最后变得非常臃肿,此时不妨学习一下 Vite 是怎么优化自身体积的。
六、未来规划
首先在 Vite 3.0 发布之后会重点保证 3.0 的稳定性,解决目前的一系列 issue。
其次,Rollup 团队将在接下来的几个月发布新的 major 版本,Vite 将持续跟进,紧接着发布 v4 版本,并在 v4 版本中将目前的一些实践性功能稳定下来。
其他
创建项目: npm init @vitejs/app
vue3支持jsx语法: yarn add -D @vitejs/plugin-vue-jsx
vite创建vue2:
先创建原生项目,再安装插件: yarn add vite-plugin-vue2 vue vue-template-compiler